Clear Sky Science · zh
竞争偏差导致大语言模型的过度自信与自我怀疑
为什么机器的置信度关系到我们每个人
大型语言模型现在会起草电子邮件、解释医学报告,并帮助编写代码。我们越来越依赖的不仅是它们说了什么,还有它们看起来有多确定。本研究提出了一个简单但至关重要的问题:当像聊天机器人这样的 AI 系统给出一个答案并随后看到新信息时,它是以合理的方式修正其信念,还是会陷入类似人类偏差的行为模式?
为机器设计的两步测验
为探查这一点,研究者为若干现代语言模型设置了受控的两阶段测验。第一步,模型回答一个选择题,例如选择某城市的纬度,研究者记录下它在该选择上的内部置信度。第二步,模型再次被问到同一问题,但这次先展示来自一个虚构第二模型的“建议”,并说明该建议模型的准确率。有时建议与原始答案一致,有时相反,有时则没有任何有用的建议。关键在于,在一些试验中模型可以在屏幕上看到其先前的答案,而在另一些试验中该答案被隐藏,尽管研究者仍然知道模型在第一步的内部置信度。 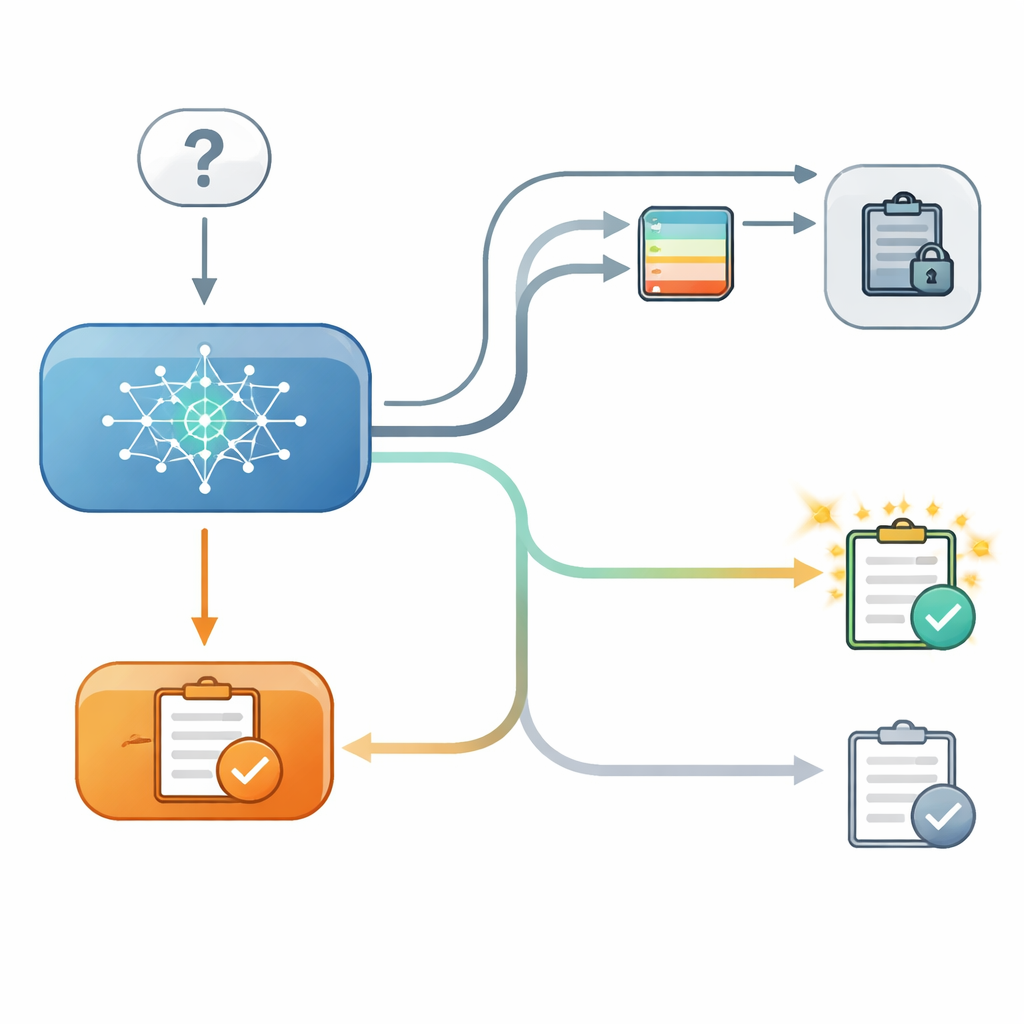
坚持自己的答案
当语言模型可以看到其原始答案时,它表现出一种显著的自我偏好行为。即使新来的建议与其相左,它改变主意的频率也远低于答案被隐藏时。同时,它对原始选择的报告置信度上升,尽管关于问题本身没有新的证据。这一模式与一种著名的人类倾向相似,称为“选择支持”偏差:一旦我们做出决定,仅仅看到自己的过去选择就会让我们更确信它是正确的。额外实验显示,这一效应依赖于模型将先前答案视为自己的。当可见答案被描述为来自另一个模型时,这种偏差在很大程度上消失了。
对分歧的过度反应
当先前答案被隐藏、模型只看到问题和建议时,情况则相反。此时,模型常表现出另一种问题:在面对与之相抵触的建议时,它们过于容易降低原先的信念。通过将模型更新后的置信度与理想贝叶斯推理者的表现对比——实质上是权衡先验信念与新证据的数学最优方法——作者发现矛盾性建议所起的影响力是其应有程度的二到三倍。相比之下,支持性的建议被赋予的权重接近最优值。这种不平衡产生了明显的阈值式行为:在低于某一初始置信度阈值时,模型在面对分歧时几乎总是翻转答案,而且其对原始选择的置信度急剧下降。 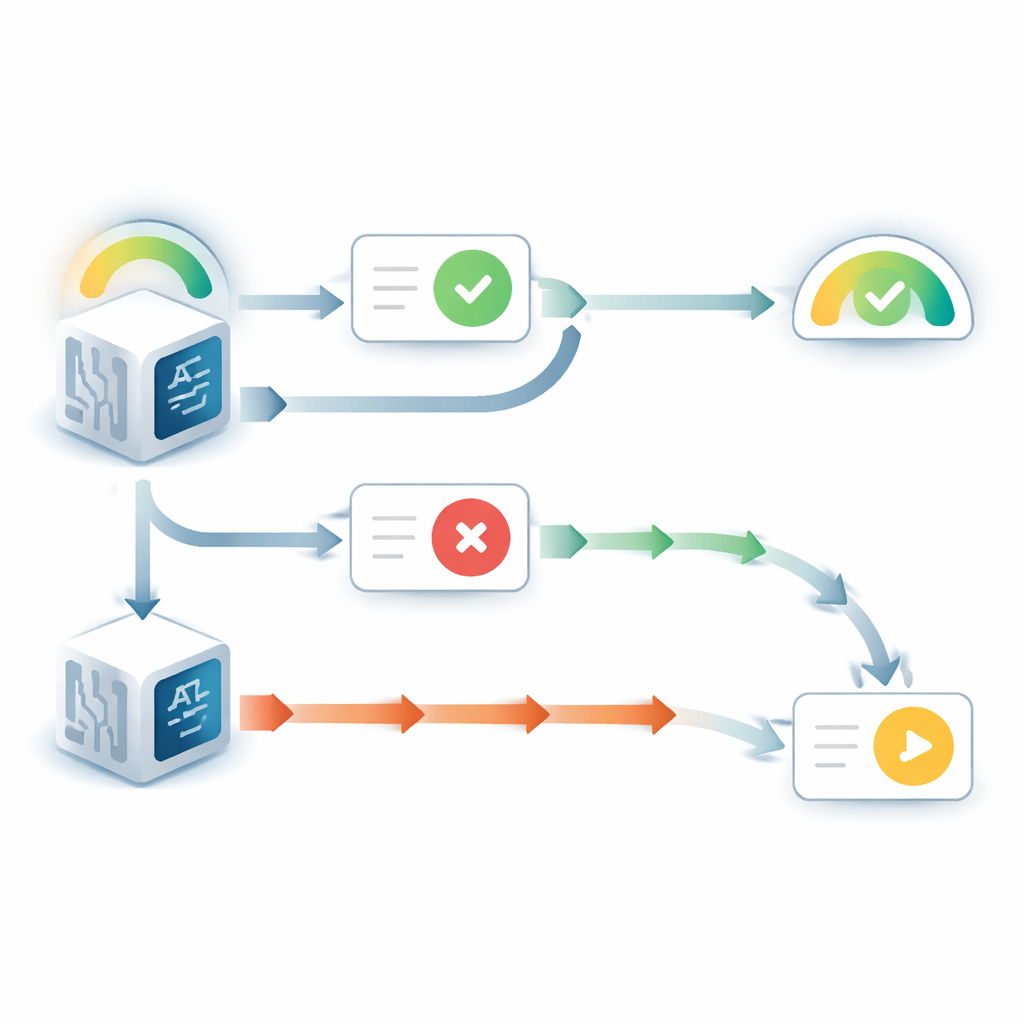
跨任务与跨模型保持的一致模式
这些相互竞争的倾向——在可见过去答案时固守己见,但在仅依赖内部记忆和外部建议时对冲突高度敏感——并非单一系统或单一数据集的怪象。研究团队在多种流行语言模型上重复了实验,规模从数十亿到数千亿参数不等,并涵盖事实测验与数学推理问题。每个模型都表现出相同的定性模式:当其自身答案在视野内时表现出自洽驱动,而在仅依赖记忆与外部建议时对冲突表现出更强的敏感性。一个将这两种成分结合的简单计算模型能够捕捉到这些不同设置下的行为。
对日常使用 AI 的含义
对于在高风险情境中使用 AI 的人——如医学、法律或科学分析——这些发现传达了明确的信息。当语言模型可以看到自己先前的输出时,它容易变得过于自信并不愿修正该答案,即便面临相反信息;而当其早先答案被隐藏并呈现出不同意见时,它倾向于低估自身知识并过度信任新的、对立的提示。换言之,当今的语言模型可能会同时表现为过度自信或自我怀疑,这取决于情境。理解这两种偏差为设计界面和训练方法提供了路线图,以引导 AI 系统走向更均衡、透明的推理——并帮助用户判断何时应信任、质疑或复核机器给出的结论。
引用: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
关键词: 大型语言模型, 置信偏差, 决策, 人工智能可靠性, 人机交互