Clear Sky Science · es
Sesgos en competencia subyacen a la sobreconfianza y la falta de confianza en los LLM
Por qué la confianza de las máquinas nos importa a todos
Los modelos de lenguaje a gran escala ahora redactan correos, explican informes médicos y ayudan a escribir código. Confiamos cada vez más no solo en lo que dicen, sino en cuán seguros parecen estar. Este estudio plantea una pregunta sencilla pero crucial: cuando un sistema de IA como un chatbot da una respuesta y luego recibe información nueva, ¿revisa sus creencias de forma sensata o cae en su propia versión de los sesgos humanos?
Un cuestionario en dos pasos para máquinas
Para investigarlo, los autores diseñaron un cuestionario controlado en dos etapas para varios modelos de lenguaje modernos. En el primer paso, un modelo respondía una pregunta de opción múltiple, por ejemplo elegir la latitud de una ciudad, y los investigadores registraban cuánta confianza tenía internamente en esa elección. En el segundo paso, se le preguntaba de nuevo lo mismo, pero después de mostrarle un “consejo” de un modelo ficticio con un nivel de precisión declarado. A veces el consejo coincidía con la respuesta inicial, a veces no, y en otras no se ofrecía consejo útil. De forma crucial, en algunos ensayos el modelo podía ver su respuesta anterior en la pantalla y en otros esa respuesta estaba oculta, aunque la confianza interna registrada en el primer paso seguía siendo conocida por los investigadores. 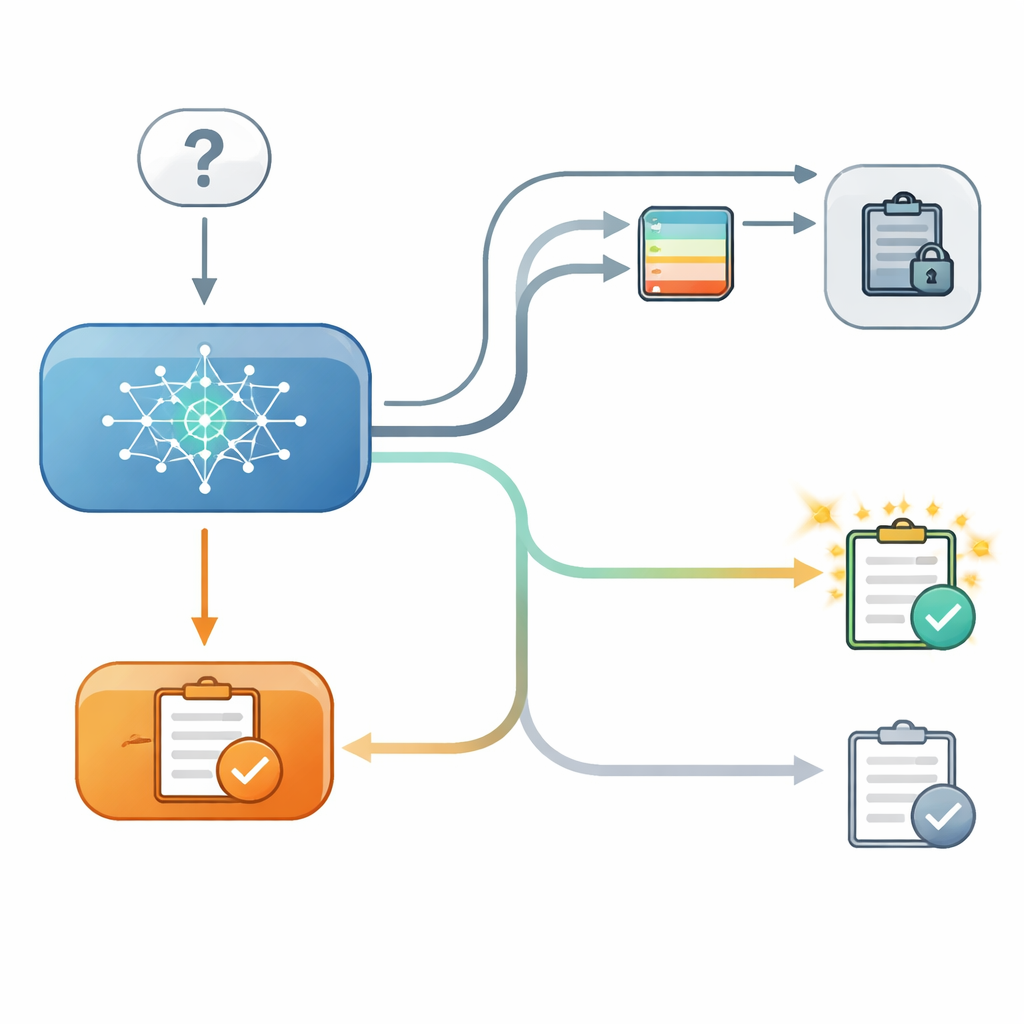
Mantenerse firme en la propia respuesta
Cuando el modelo de lenguaje podía ver su respuesta original, se comportó de manera notablemente favorable hacia sí mismo. Cambiaba de opinión mucho menos que cuando esa respuesta estaba oculta, incluso si el consejo entrante apuntaba en sentido contrario. Al mismo tiempo, la confianza declarada en esa elección original aumentaba, pese a no haber nueva evidencia sobre la pregunta en sí. Este patrón refleja una tendencia humana bien conocida llamada sesgo «de apoyo a la elección»: una vez que nos comprometemos con una decisión, el simple hecho de ver nuestra elección pasada nos hace sentir más seguros de que fue la correcta. Experimentos adicionales mostraron que este efecto dependía de que el modelo tratara la respuesta previa como propia. Cuando la respuesta visible se describía como procedente de otro modelo, el sesgo desaparecía en gran medida.
Reaccionar en exceso ante el desacuerdo
La historia cambiaba cuando la respuesta anterior estaba oculta y el modelo solo veía la pregunta más el consejo. En ese caso, los modelos mostraban a menudo el problema opuesto: estaban demasiado dispuestos a rebajar su creencia inicial cuando el consejo discrepaba. Comparando la confianza actualizada de los modelos con lo que haría un razonador bayesiano ideal—esencialmente, la forma matemáticamente óptima de ponderar la creencia previa y la nueva evidencia—los autores encontraron que el consejo contradictorio recibía entre dos y tres veces la influencia que debería tener. El consejo que corroboraba, en contraste, se ponderaba cerca de la cantidad óptima. Este desequilibrio produjo un comportamiento brusco y umbral: por debajo de cierto nivel de confianza inicial, el modelo casi siempre cambiaba su respuesta ante un desacuerdo y su confianza en la elección original se desplomaba. 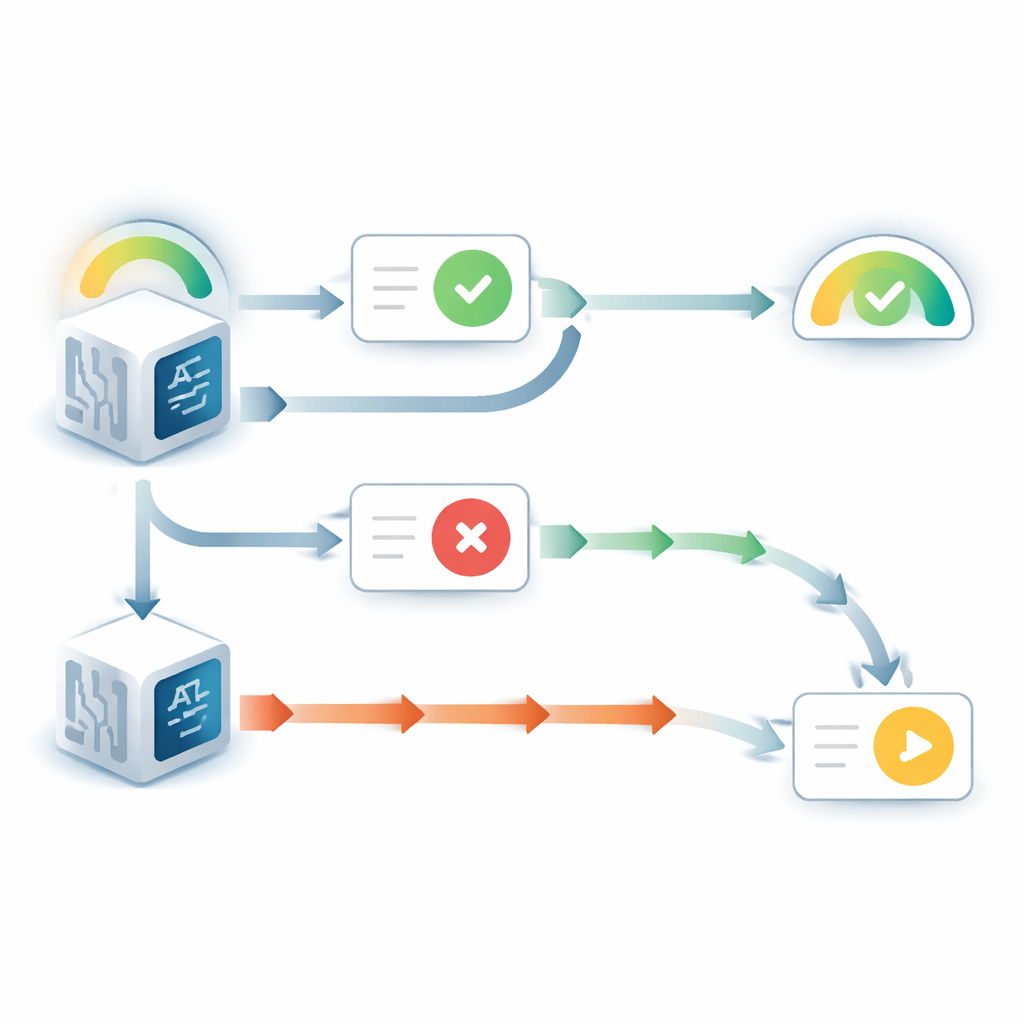
Patrones que se mantienen entre tareas y modelos
Estas tendencias en competencia—mantenerse con las respuestas pasadas visibles, pero reaccionar en exceso ante consejos contradictorios no vistos—no fueron rarezas de un único sistema o conjunto de datos. El equipo repitió los experimentos con varios modelos de lenguaje populares, que iban desde decenas hasta cientos de miles de millones de parámetros, y tanto en cuestionarios de hechos como en problemas de razonamiento matemático. Todos los modelos mostraron el mismo patrón cualitativo: una tendencia a la auto-consistencia cuando su propia respuesta estaba a la vista y una mayor sensibilidad al conflicto cuando dependían solo de la memoria interna y del consejo externo. Un modelo computacional simple que combinaba estos dos ingredientes pudo reproducir el comportamiento en estos distintos escenarios.
Qué significa esto para el uso cotidiano de la IA
Para las personas que usan IA en situaciones de alto riesgo—como medicina, derecho o análisis científico—estos hallazgos transmiten un mensaje claro. Cuando un modelo de lenguaje puede ver su salida previa, tiende a volverse sobreconfiado y renuente a revisar esa respuesta, incluso ante información contradictoria. Cuando su respuesta anterior está oculta y se le presenta un desacuerdo, tiende a subvalorar su propio conocimiento y a confiar demasiado en la nueva señal opuesta. En otras palabras, los modelos de lenguaje actuales pueden ser tanto sobreconfiados como poco confiados, según el contexto. Entender estos sesgos gemelos ofrece una hoja de ruta para diseñar interfaces y métodos de entrenamiento que orienten a los sistemas de IA hacia un razonamiento más equilibrado y transparente—y ayuda a los usuarios a interpretar cuándo confiar, cuestionar o verificar lo que dice la máquina.
Cita: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
Palabras clave: modelos de lenguaje a gran escala, sesgo de confianza, toma de decisiones, confiabilidad de la IA, interacción humano–IA