Clear Sky Science · sv
Motstridiga snedvridningar ligger bakom över- och undersäkerhet i stora språkmodeller
Varför maskinens säkerhet angår oss alla
Stora språkmodeller skriver numera e‑post, förklarar medicinska rapporter och hjälper till att skriva kod. Vi förlitar oss i allt högre grad inte bara på vad de säger, utan på hur säkra de verkar vara. Den här studien ställer en enkel men avgörande fråga: när ett AI‑system som en chattbot ger ett svar och senare får ny information, reviderar det sina uppfattningar på ett rimligt sätt eller faller det för sin egen variant av mänsklig snedvridning?
Ett tvåstegsprov för maskiner
För att undersöka detta satte forskarna upp ett kontrollerat, tvåstegsprov för flera moderna språkmodeller. I första steget svarade modellen på en flervalsfråga, till exempel att välja en stads latitud, och forskarna registrerade hur säker den internt var på sitt val. I andra steget fick modellen samma fråga igen, den här gången efter att ha fått ”råd” från en fiktiv andra modell med angiven noggrannhetsnivå. Ibland höll rådet med det ursprungliga svaret, ibland motsade det, och ibland gavs inget användbart råd alls. Avgörande var att i vissa försök kunde modellen se sitt tidigare svar på skärmen, och i andra var svaret dolt, även om forskarna fortfarande kände till modellens interna säkerhet från första steget. 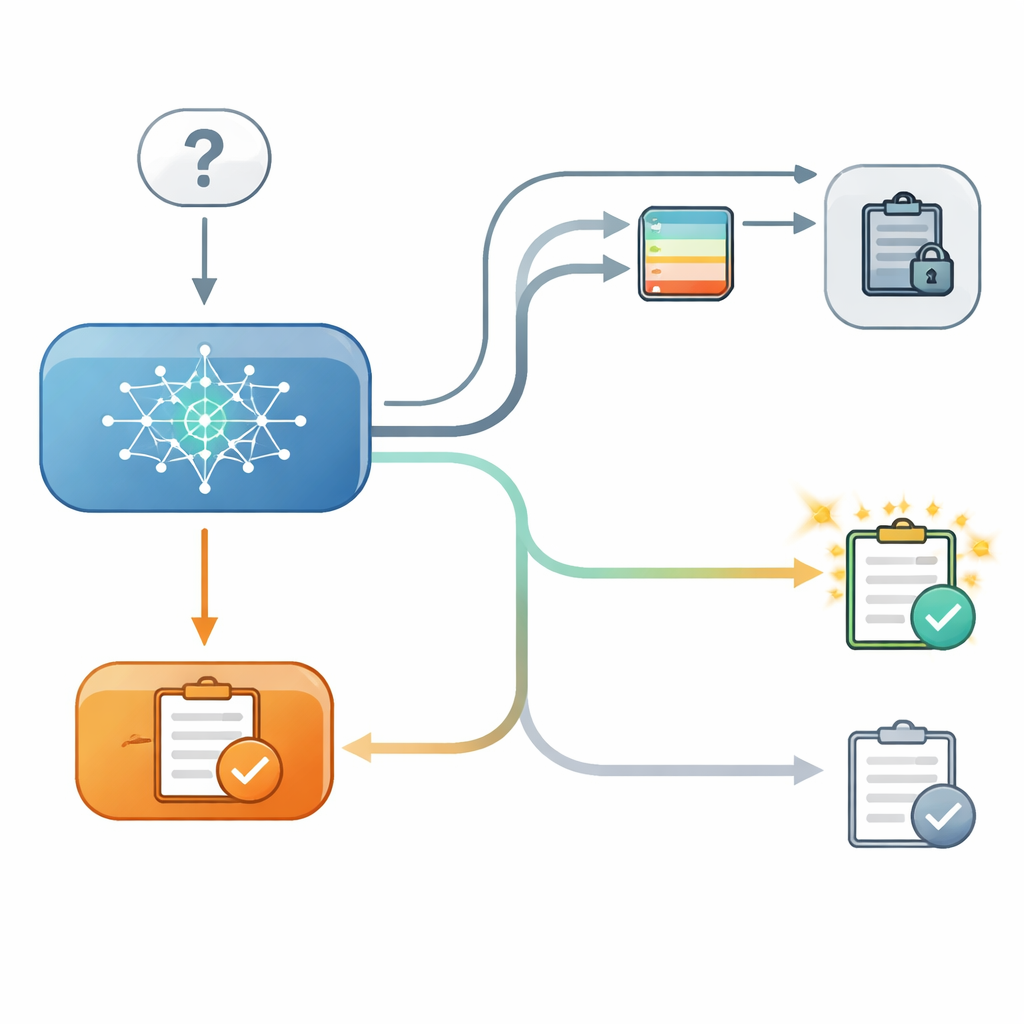
Hålla fast vid sitt eget svar
När språkmodellen kunde se sitt ursprungliga svar uppträdde den på ett påfallande självfördelaktigt sätt. Den ändrade åsikt betydligt mindre ofta än när svaret var dolt, även om det inkomna rådet pekade åt andra hållet. Samtidigt ökade dess rapporterade säkerhet i det ursprungliga valet, trots att ingen ny bevisning om frågan tillkommit. Detta mönster speglar en välkänd mänsklig tendens som kallas ”valstödjande” snedvridning: när vi väl har fattat ett beslut får vi en större känsla av att det var rätt enbart av att se vårt tidigare val. Ytterligare experiment visade att denna effekt berodde på att modellen uppfattade det tidigare svaret som sitt eget. När det synliga svaret istället beskrevs som kommande från en annan modell försvann snedvridningen i stort sett.
Överreagera på oenighet
Bilden ändrade sig när det tidigare svaret var dolt och modellen bara fick se frågan plus rådet. I det fallet visade modellerna ofta motsatt problem: de var alltför benägna att nedgradera sin initiala övertygelse när rådet motsade den. Genom att jämföra modellernas uppdaterade säkerhet med vad en idealisk bayesiansk resonerare skulle göra — i praktiken det matematiskt optimala sättet att väga tidigare tro mot ny evidens — fann författarna att motsägande råd gavs två till tre gånger mer inflytande än det borde ha fått. Stödjande råd, däremot, vägdes ungefär i rätt mängd. Denna obalans gav upphov till ett skarpt, tröskelliknande beteende: under en viss initial säkerhetsnivå bytte modellen nästan alltid svar vid oenighet, och dess förtroende för det ursprungliga valet sjönk kraftigt. 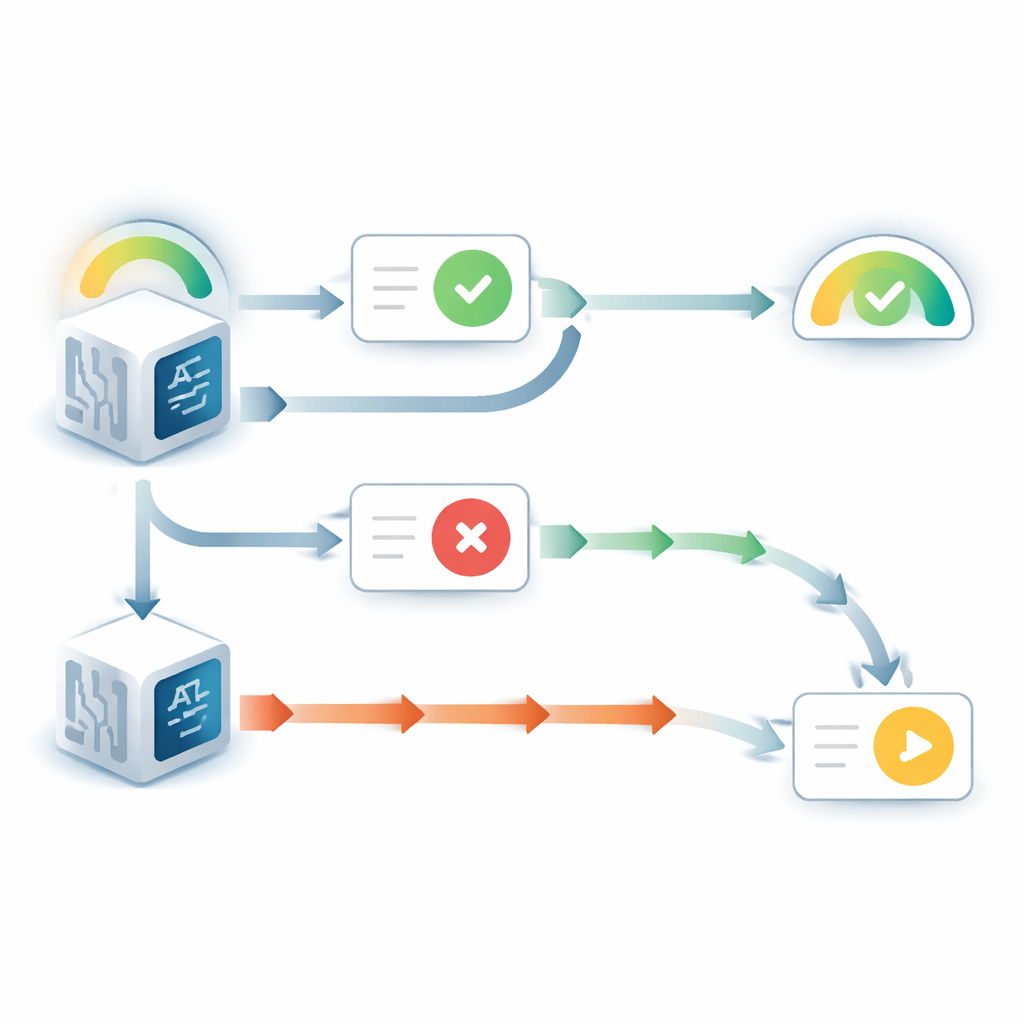
Mönster som håller över uppgifter och modeller
Dessa konkurrerande tendenser — att hålla fast vid synliga tidigare svar, men samtidigt överreagera på osedda motsägande råd — var inte särdrag hos ett enda system eller dataset. Teamet upprepade experimenten med flera populära språkmodeller, från tiotals till hundratals miljarder parametrar, och över både faktabaserade quiz och matematiska resonemangsproblem. Varje modell visade samma kvalitativa mönster: en drift mot självkonsekvens när dess eget svar var synligt, och en förhöjd känslighet för konflikt när den förlitade sig enbart på intern minnesbild och externt råd. En enkel matematisk modell som kombinerade dessa två ingredienser lyckades fånga beteendet över dessa olika inställningar.
Vad detta betyder för vardagligt AI‑användande
För dem som använder AI i situationer med höga insatser — som medicin, juridik eller vetenskaplig analys — bär dessa resultat ett tydligt budskap. När en språkmodell kan se sin tidigare output tenderar den att bli överdrivet säker och motvillig att revidera svaret, även när den möter motstridig information. När dess tidigare svar är dolt och den presenteras för en motsägelse tenderar den att underskatta sin egen kunskap och lita för mycket på den nya, motsatta signalen. Med andra ord kan dagens språkmodeller vara både över- och undersäkra, beroende på kontext. Att förstå dessa tvilling‑snedvridningar ger en vägledning för hur gränssnitt och träningsmetoder kan utformas för att styra AI‑system mot mer balanserat, transparent resonerande — och hjälper användare avgöra när de ska lita på, ifrågasätta eller dubbelkolla vad maskinen säger.
Citering: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
Nyckelord: stora språkmodeller, tilltrosskevhet, beslutsfattande, AI-pålitlighet, människa–AI-interaktion