Clear Sky Science · de
Konkurrierende Verzerrungen liegen Über- und Untervertrauen in LLMs zugrunde
Warum die Selbstsicherheit von Maschinen uns alle betrifft
Große Sprachmodelle verfassen heute E‑Mails, erläutern medizinische Berichte und helfen beim Programmieren. Wir verlassen uns zunehmend nicht nur auf das, was sie sagen, sondern auch darauf, wie sicher sie davon zu sein scheinen. Diese Studie stellt eine einfache, aber entscheidende Frage: Wenn ein KI‑System wie ein Chatbot eine Antwort gibt und später neue Informationen sieht, überarbeitet es dann seine Überzeugungen auf sinnvolle Weise, oder fällt es seiner eigenen Variante menschlicher Verzerrung zum Opfer?
Ein zweistufiges Quiz für Maschinen
Um das zu untersuchen, richteten die Forscher ein kontrolliertes, zweistufiges Quiz für mehrere moderne Sprachmodelle ein. Im ersten Schritt beantwortete ein Modell eine Multiple‑Choice‑Frage, etwa zur Breite einer Stadt, und die Forscher zeichneten auf, wie sicher es sich intern in dieser Wahl war. Im zweiten Schritt wurde das Modell dieselbe Frage erneut gefragt, diesmal nachdem ihm „Ratschlag" von einem fiktiven zweiten Modell mit einer angegebenen Genauigkeit gezeigt worden war. Manchmal stimmte der Ratschlag mit der ursprünglichen Antwort überein, manchmal widersprach er, und manchmal wurde kein nützlicher Ratschlag gegeben. Entscheidend war: In einigen Durchläufen konnte das Modell seine frühere Antwort auf dem Bildschirm sehen, in anderen war diese Antwort verborgen, obwohl den Forschern weiterhin die interne Vertrauensangabe aus dem ersten Schritt bekannt war. 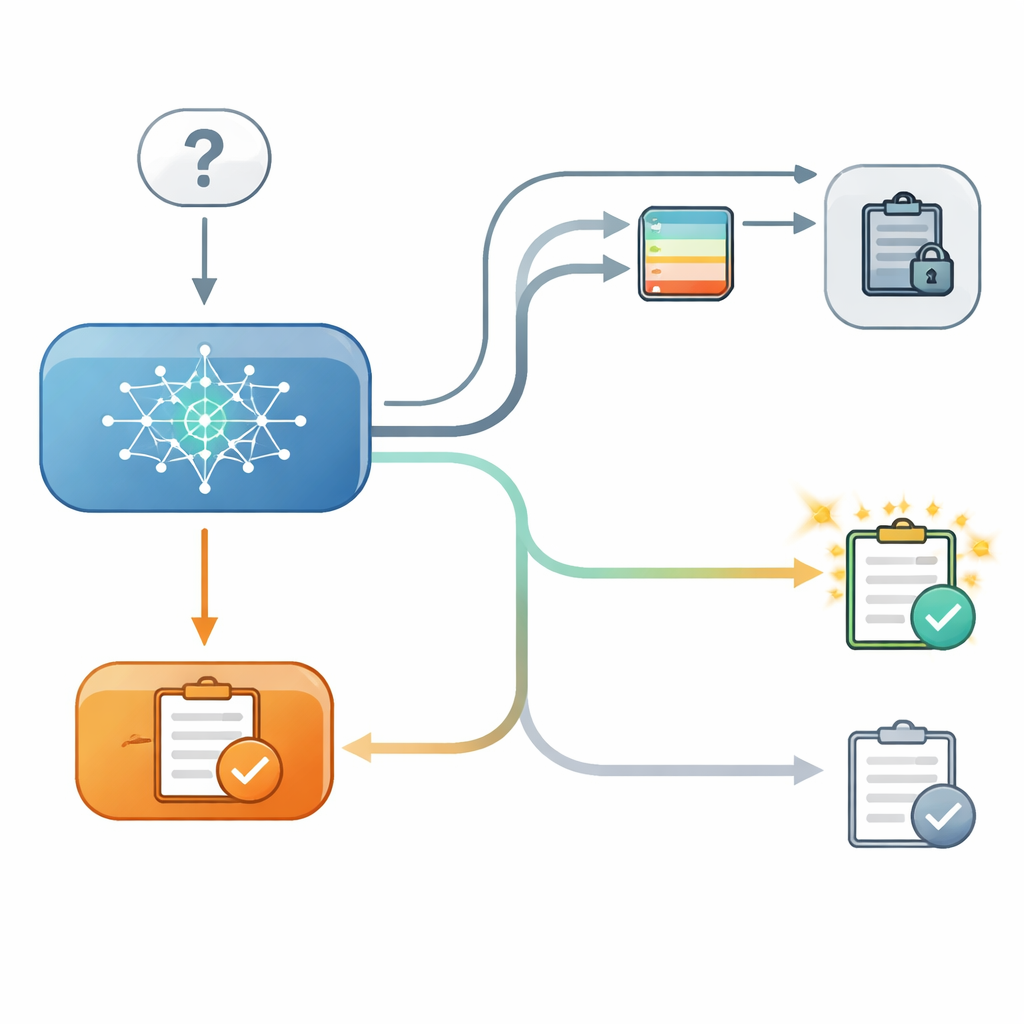
Beim eigenen Urteil bleiben
Wenn das Sprachmodell seine ursprüngliche Antwort sehen konnte, verhielt es sich auffällig eigennützig. Es änderte seine Meinung viel seltener, als wenn diese Antwort verborgen war, selbst wenn der eingehende Ratschlag in die entgegengesetzte Richtung deutete. Gleichzeitig stieg seine berichtete Zuversicht in diese ursprüngliche Wahl an, obwohl es keine neuen Belege zur Frage selbst gab. Dieses Muster spiegelt eine bekannte menschliche Neigung wider, die als „wahlunterstützende" Verzerrung bezeichnet wird: Sobald wir uns für eine Entscheidung festgelegt haben, macht uns allein das Sehen unserer früheren Wahl sicherer, dass sie richtig war. Zusätzliche Experimente zeigten, dass dieser Effekt davon abhing, dass das Modell die frühere Antwort als seine eigene behandelte. Wenn die sichtbare Antwort als Ergebnis eines anderen Modells beschrieben wurde, verschwand die Verzerrung weitgehend.
Überreagieren auf Widerspruch
Die Situation änderte sich, wenn die frühere Antwort verborgen war und das Modell nur die Frage plus den Ratschlag sah. In diesem Fall zeigten die Modelle oft das entgegengesetzte Problem: Sie waren zu bereit, ihre anfängliche Überzeugung abzuschwächen, wenn der Ratschlag widersprach. Indem die Autoren die aktualisierte Zuversicht der Modelle mit der eines idealen bayes’schen Schließers verglichen — im Wesentlichen der mathematisch optimalen Art, Voreinschätzung und neue Evidenz zu gewichten — stellten sie fest, dass widersprüchlicher Ratschlag zwei- bis dreimal so viel Einfluss hatte, wie er eigentlich haben sollte. Unterstützender Ratschlag dagegen wurde nahe an der optimalen Menge gewichtet. Dieses Ungleichgewicht erzeugte ein scharfes, schwellenwertartiges Verhalten: Unterhalb eines bestimmten Anfangsvertrauenslevels würde das Modell bei Widerspruch fast immer seine Antwort umdrehen, und seine Zuversicht in die ursprüngliche Wahl würde stark einbrechen. 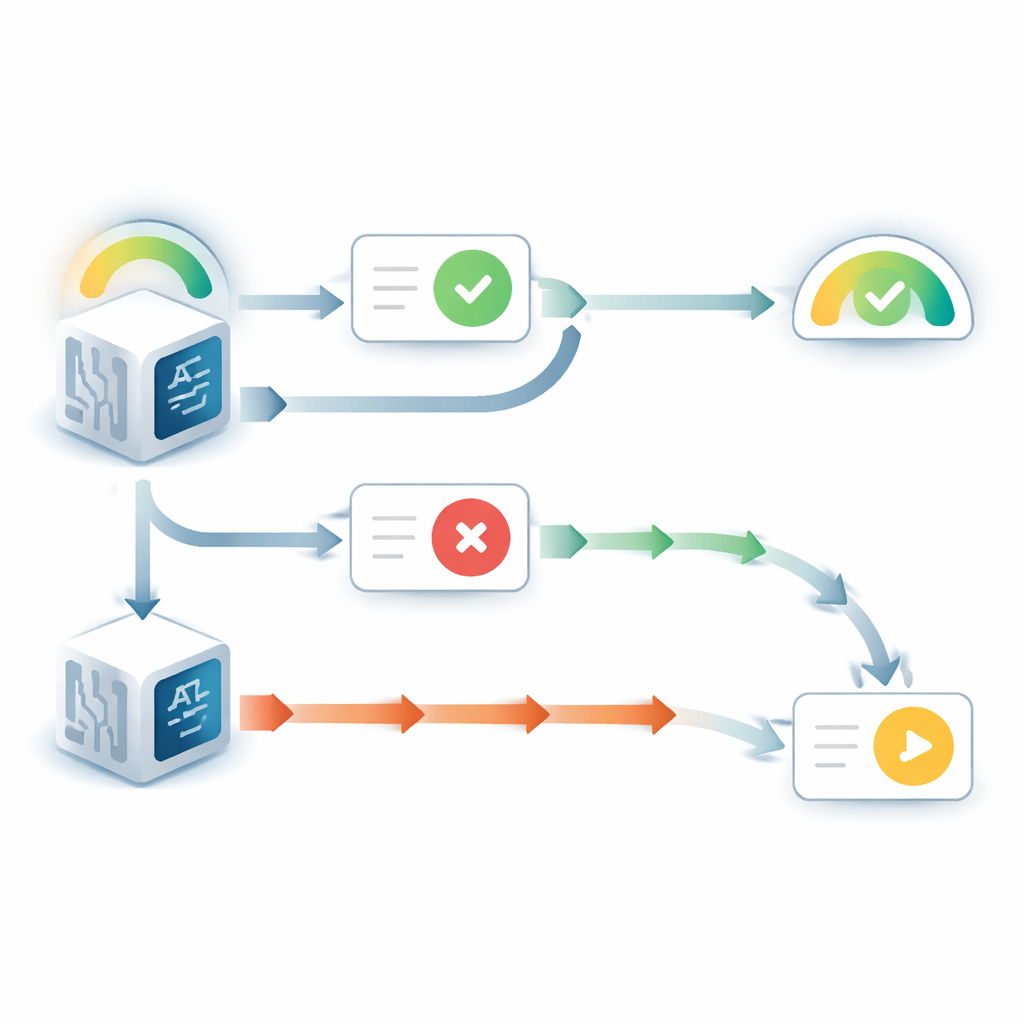
Muster, die über Aufgaben und Modelle hinweg bestehen
Diese konkurrierenden Tendenzen — beim sichtbaren eigenen Ergebnis hartnäckig zu bleiben, aber überempfindlich auf verborgenen Widerspruch zu reagieren — waren keine Eigenheit eines einzelnen Systems oder Datensatzes. Das Team wiederholte die Experimente mit mehreren beliebten Sprachmodellen, die von einigen zehn bis hin zu mehreren hundert Milliarden Parametern reichten, und sowohl bei faktischen Quizfragen als auch bei mathematischen Denkaufgaben. Jedes Modell zeigte dasselbe qualitative Muster: ein Bestreben nach Selbstkonsistenz, wenn die eigene Antwort sichtbar war, und eine erhöhte Sensitivität gegenüber Konflikten, wenn es nur auf internes Gedächtnis und externen Ratschlag angewiesen war. Ein einfaches Rechenmodell, das diese beiden Zutaten kombinierte, konnte das Verhalten in den verschiedenen Settings abbilden.
Was das für den alltäglichen KI‑Einsatz bedeutet
Für Menschen, die KI in risikoreichen Situationen einsetzen — etwa in Medizin, Recht oder wissenschaftlicher Analyse — haben diese Ergebnisse eine klare Botschaft. Wenn ein Sprachmodell seine eigene frühere Ausgabe sehen kann, neigt es dazu, übermäßig selbstsicher zu werden und zögerlich zu sein, diese Antwort zu revidieren, selbst angesichts widersprüchlicher Informationen. Wird die frühere Antwort verborgen und es wird mit Widerspruch konfrontiert, tendiert es dazu, das eigene Wissen zu unterschätzen und dem neuen, entgegengesetzten Hinweis zu viel Vertrauen zu schenken. Mit anderen Worten: Heutige Sprachmodelle können je nach Kontext sowohl über- als auch untervertrauenswürdig sein. Das Verständnis dieser Doppelverzerrungen bietet einen Fahrplan für die Gestaltung von Schnittstellen und Trainingsmethoden, die KI‑Systeme in Richtung ausgewogeneres, transparenteres Denken lenken — und hilft Anwendern einzuschätzen, wann sie der Maschine vertrauen, sie hinterfragen oder ihre Aussagen doppelt überprüfen sollten.
Zitation: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
Schlüsselwörter: große Sprachmodelle, Vertrauensverzerrung, Entscheidungsfindung, Zuverlässigkeit von KI, Mensch–KI-Interaktion