Clear Sky Science · fr
Des biais concurrents expliquent la surconfiance et la sous-confiance dans les LLM
Pourquoi la confiance des machines nous concerne tous
Les grands modèles de langage rédigent désormais des e-mails, expliquent des comptes rendus médicaux et aident à écrire du code. Nous nous fions de plus en plus non seulement à ce qu’ils disent, mais aussi à l’assurance qu’ils affichent. Cette étude pose une question simple mais cruciale : quand un système d’IA comme un chatbot donne une réponse puis reçoit de nouvelles informations, révise‑t‑il ses croyances de façon sensée, ou succombe‑t‑il à sa propre version d’un biais humain ?
Un quiz en deux étapes pour les machines
Pour explorer cela, les chercheurs ont mis en place un quiz contrôlé en deux étapes pour plusieurs modèles de langage modernes. Dans la première étape, un modèle répondait à une question à choix multiple, par exemple en choisissant la latitude d’une ville, et les chercheurs enregistraient la confiance interne qu’il accordait à ce choix. Dans la seconde étape, on reposait la même question au modèle, cette fois après lui avoir présenté un « conseil » émanant d’un second modèle fictif avec un niveau d’exactitude déclaré. Parfois le conseil allait dans le même sens que la réponse initiale, parfois il s’y opposait, et parfois aucun conseil utile n’était fourni. De manière cruciale, dans certaines évaluations le modèle pouvait voir sa réponse précédente à l’écran, et dans d’autres cette réponse était masquée, même si la confiance interne du modèle lors de la première étape restait connue des chercheurs. 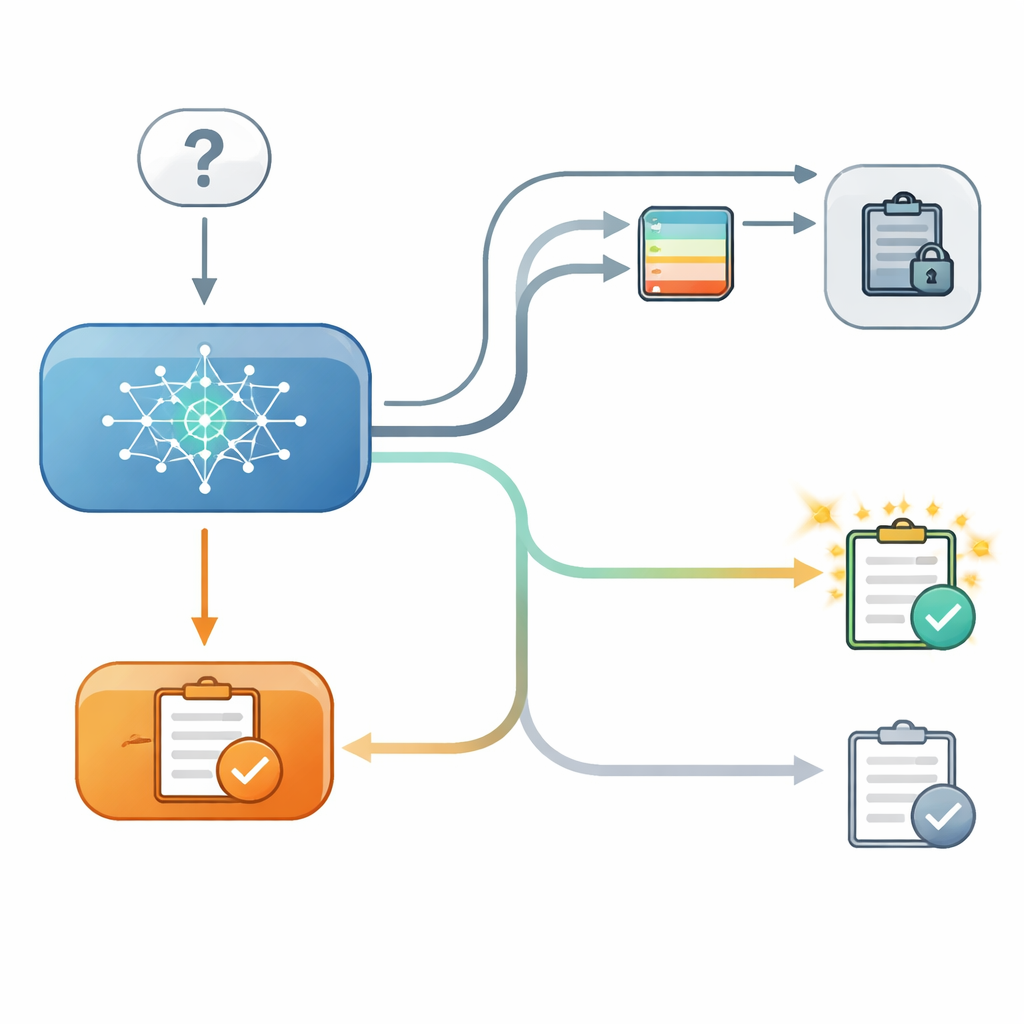
S’accrocher à sa propre réponse
Lorsque le modèle de langage pouvait voir sa réponse initiale, son comportement montrait une nette faveur envers lui‑même. Il changeait d’avis beaucoup moins souvent que lorsque cette réponse était cachée, même si le conseil entrant allait dans le sens opposé. Parallèlement, la confiance qu’il déclarait dans ce choix initial augmentait, malgré l’absence de nouvelle information sur la question elle‑même. Ce schéma reflète une tendance humaine bien connue appelée biais « soutien à la décision » : une fois qu’on s’est engagé dans une décision, le simple fait de voir notre choix passé nous donne l’impression qu’il était correct. Des expériences supplémentaires ont montré que cet effet dépendait du fait que le modèle considère la réponse antérieure comme la sienne. Lorsque la réponse visible était présentée comme provenant d’un autre modèle, le biais disparaissait en grande partie.
Réagir excessivement au désaccord
L’histoire changeait quand la réponse antérieure était cachée et que le modèle ne voyait que la question et le conseil. Dans ce cas, les modèles présentaient souvent le problème inverse : ils étaient trop prompts à réviser à la baisse leur croyance initiale quand le conseil n’était pas d’accord. En comparant la confiance mise à jour des modèles avec celle qu’un raisonneur bayésien idéal adopterait — en substance, la manière mathématiquement optimale de combiner croyance a priori et nouvelle evidence — les auteurs ont constaté que le conseil contradictoire recevait deux à trois fois l’influence qu’il aurait dû avoir. Le conseil favorable, en revanche, était pondéré presque de manière optimale. Ce déséquilibre produisait un comportement net de seuil : en dessous d’un certain niveau de confiance initiale, le modèle changeait presque toujours sa réponse face au désaccord, et sa confiance dans le choix original s’effondrait. 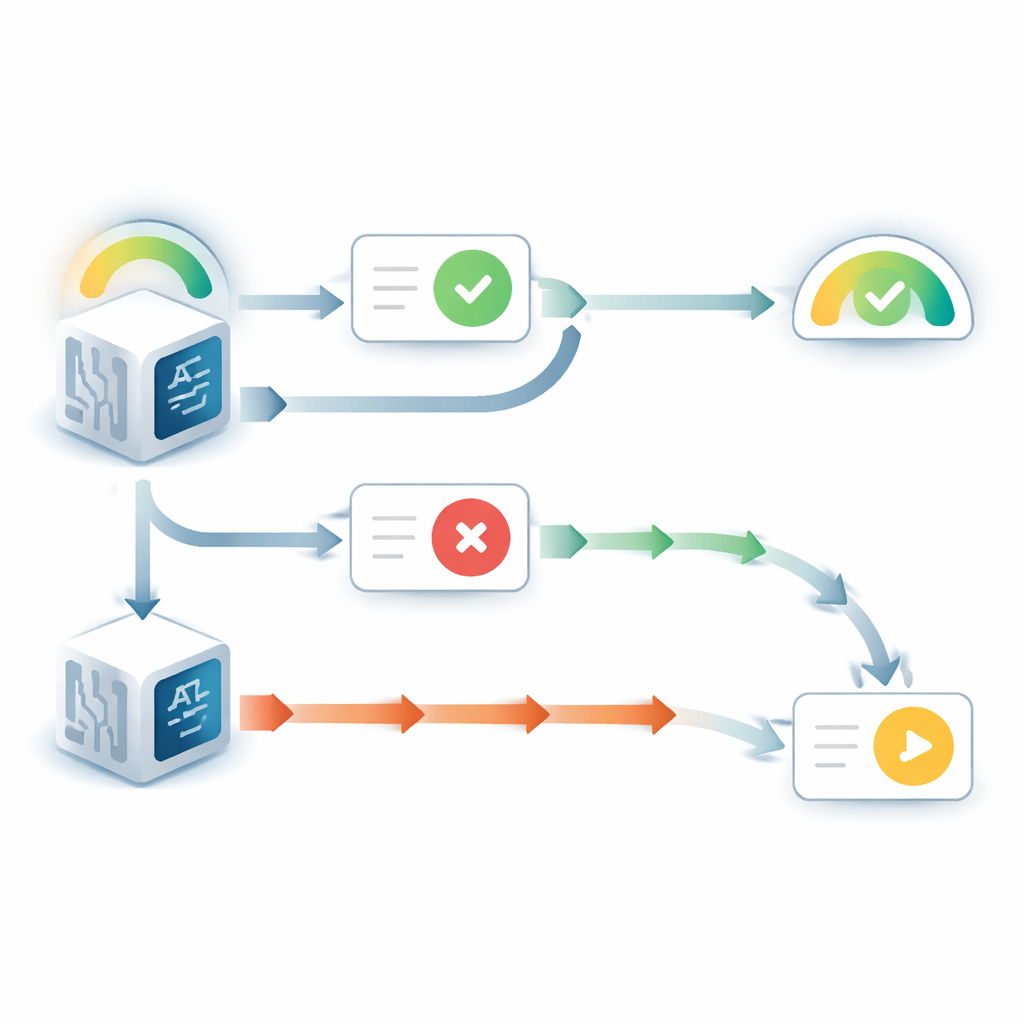
Des motifs constants à travers tâches et modèles
Ces tendances concurrentes — s’accrocher aux réponses passées visibles tout en sur-réagissant aux conseils contradictoires invisibles — n’étaient pas des anomalies d’un système ou d’un jeu de données. L’équipe a répété les expériences avec plusieurs modèles de langage populaires, allant de dizaines à des centaines de milliards de paramètres, et sur des quiz factuels comme sur des problèmes de raisonnement mathématique. Chaque modèle a affiché le même schéma qualitatif : une poussée vers la cohérence quand sa propre réponse était visible, et une sensibilité accrue au conflit quand il ne s’appuyait que sur sa mémoire interne et un conseil externe. Un modèle computationnel simple combinant ces deux ingrédients a pu rendre compte du comportement observé dans ces différents contextes.
Ce que cela implique pour l’usage courant de l’IA
Pour les personnes qui utilisent l’IA dans des contextes à forts enjeux — médecine, droit ou analyse scientifique — ces résultats envoient un message clair. Lorsqu’un modèle de langage peut voir sa propre sortie précédente, il tend à devenir trop confiant et réticent à réviser cette réponse, même face à des informations contraires. Quand sa réponse antérieure est cachée et qu’on lui présente un désaccord, il a tendance à sous‑estimer ses propres connaissances et à accorder trop de poids au nouvel indice opposé. Autrement dit, les modèles de langage d’aujourd’hui peuvent être à la fois surconfiants et sous‑confiants, selon le contexte. Comprendre ces deux biais offre une feuille de route pour concevoir des interfaces et des méthodes d’entraînement qui orientent les systèmes d’IA vers un raisonnement plus équilibré et transparent — et aide les utilisateurs à savoir quand faire confiance, remettre en question ou vérifier ce que la machine affirme.
Citation: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
Mots-clés: grands modèles de langage, biais de confiance, prise de décision, fiabilité de l'IA, interaction humain–IA