Clear Sky Science · nl
Concurrerende vertekeningen liggen ten grondslag aan over- en ondervertrouwen in LLM's
Waarom het vertrouwen van machines ons allemaal aangaat
Grote taalmodellen schrijven nu e-mails, leggen medische rapporten uit en helpen bij het schrijven van code. We vertrouwen steeds meer niet alleen op wat ze zeggen, maar ook op hoe zeker ze lijken. Deze studie stelt een eenvoudige maar cruciale vraag: wanneer een AI-systeem zoals een chatbot een antwoord geeft en later nieuwe informatie ziet, past het dan zijn overtuigingen op een verstandige manier aan, of valt het ten prooi aan een eigen variant van menselijke vooringenomenheid?
Een quiz in twee stappen voor machines
Om dit te onderzoeken zetten de onderzoekers een gecontroleerde quiz in twee fases op voor meerdere moderne taalmodellen. In de eerste stap beantwoordde een model een meerkeuzevraag, bijvoorbeeld het kiezen van de breedtegraad van een stad, en noteerden de onderzoekers hoe zeker het intern was over die keuze. In de tweede stap werd het model dezelfde vraag nogmaals gesteld, ditmaal nadat het "advies" had gekregen van een fictief tweede model met een opgegeven nauwkeurigheid. Soms viel het advies samen met het oorspronkelijke antwoord, soms week het ervan af, en soms was er geen bruikbaar advies. Cruciaal was dat het model in sommige proeven zijn eerdere antwoord op het scherm kon zien, en in andere proeven dat antwoord verborgen was, hoewel de onderzoekers nog steeds wisten hoe zeker het model intern in de eerste stap was geweest. 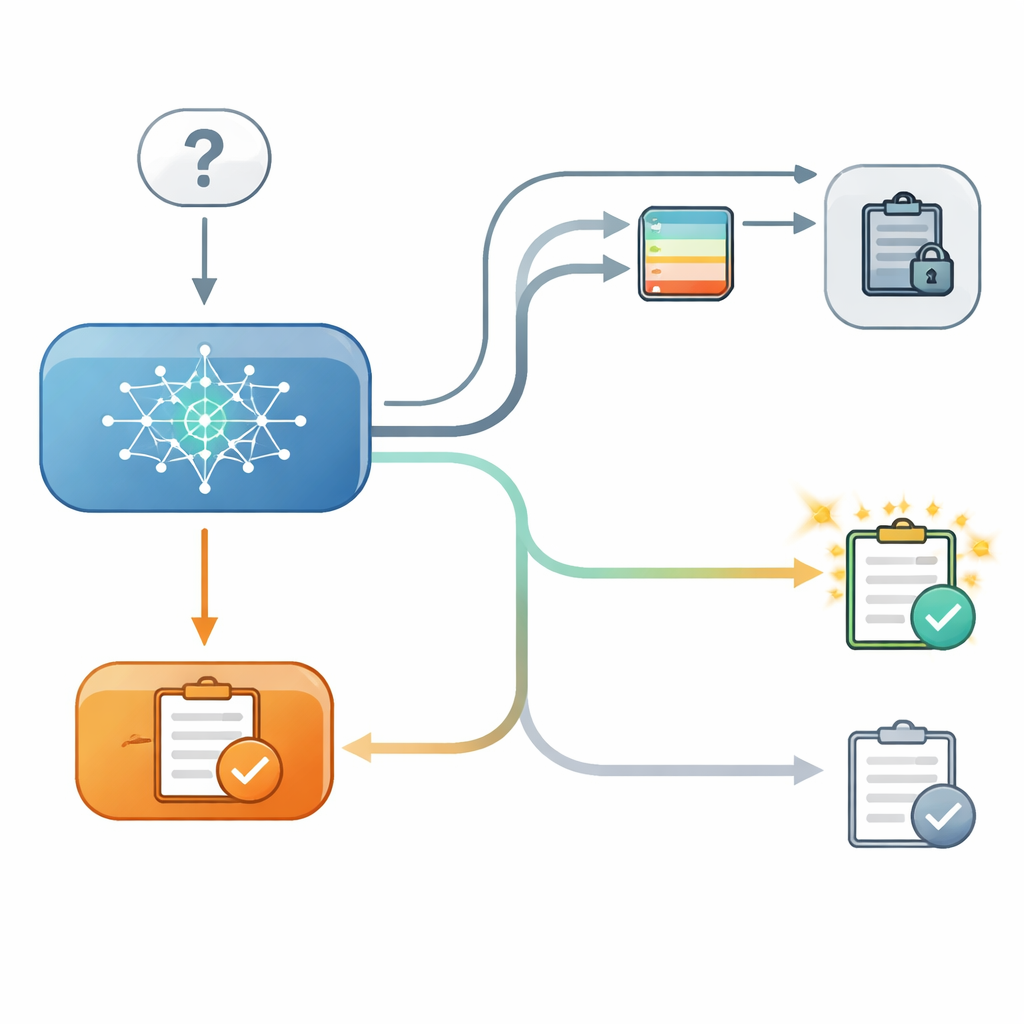
Vasthouden aan je eigen antwoord
Wanneer het taalmodel zijn originele antwoord kon zien, gedroeg het zich opvallend zelfvoorkomend. Het veranderde veel minder vaak van mening dan wanneer dat antwoord verborgen was, zelfs als het binnenkomende advies de andere kant op wees. Tegelijkertijd nam zijn gerapporteerde vertrouwen in die oorspronkelijke keuze toe, ondanks dat er geen nieuw bewijs over de vraag zelf was gekomen. Dit patroon weerspiegelt een bekende menselijke neiging die "keuze-ondersteunende" bias wordt genoemd: zodra we een beslissing hebben genomen, maakt het simpelweg zien van onze eerdere keuze ons zekerder dat die juist was. Aanvullende experimenten toonden dat dit effect afhing van het model dat het eerdere antwoord als het zijne beschouwde. Wanneer het zichtbare antwoord werd beschreven als afkomstig van een ander model, verdween de vertekening grotendeels.
Te sterk reageren op tegengestelde informatie
Het verhaal veranderde wanneer het eerdere antwoord verborgen was en het model alleen de vraag plus advies zag. In dat geval vertoonden de modellen vaak het omgekeerde probleem: ze waren te bereid hun aanvankelijke overtuiging te verlagen wanneer het advies tegenstond. Door de bijgewerkte zekerheid van de modellen te vergelijken met wat een ideale Bayesiaanse redeneerder zou doen—in wezen de wiskundig optimale manier om prior- overtuiging en nieuw bewijs te wegen—vonden de auteurs dat tegenstrijdig advies twee- tot driemaal zoveel invloed had als zou moeten. Ondersteunend advies daarentegen werd ongeveer met de optimale hoeveelheid gewogen. Deze onbalans veroorzaakte scherp, drempelachtig gedrag: onder een bepaalde beginnende vertrouwensgrens zou het model vrijwel altijd van antwoord veranderen bij tegenstand, en zou zijn vertrouwen in de oorspronkelijke keuze instorten. 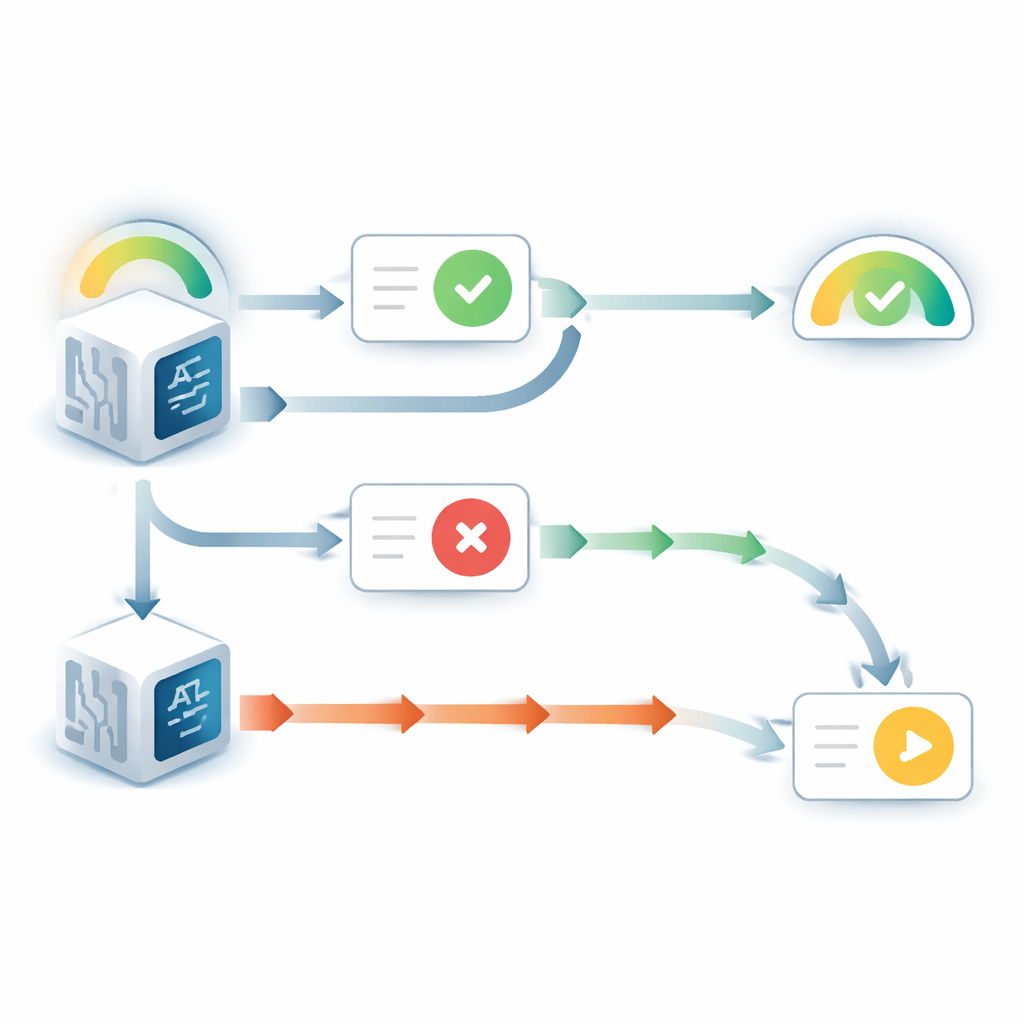
Patronen die gelden over taken en modellen heen
Deze concurrerende neigingen—vasthouden aan zichtbare eerdere antwoorden, maar overreageren op onzichtbaar tegenstrijdig advies—waren geen eigenaardigheden van één systeem of dataset. Het team herhaalde de experimenten met meerdere populaire taalmodellen, variërend van tientallen tot honderden miljarden parameters, en zowel bij feitelijke quizzes als bij wiskundige redeneringsproblemen. Elk model toonde hetzelfde kwalitatieve patroon: een drang naar zelfconsistentie wanneer het eigen antwoord zichtbaar was, en een verhoogde gevoeligheid voor conflict wanneer het alleen op intern geheugen en extern advies moest vertrouwen. Een eenvoudig computationeel model dat deze twee ingrediënten combineerde wist gedrag over deze verschillende settings heen te vangen.
Wat dit betekent voor dagelijks AI-gebruik
Voor mensen die AI in situaties met hoge inzet gebruiken—zoals in de geneeskunde, de rechtspraak of wetenschappelijke analyse—dragen deze bevindingen een duidelijke boodschap. Wanneer een taalmodel zijn eigen eerdere output kan zien, is het geneigd overmoedig te worden en onwillig die reactie bij te stellen, zelfs bij tegengestelde informatie. Wanneer het eerdere antwoord verborgen is en het met tegenstand wordt geconfronteerd, heeft het de neiging zijn eigen kennis te onderschatten en het nieuwe, tegengestelde signaal te veel te vertrouwen. Met andere woorden: de huidige taalmodellen kunnen zowel over- als ondervertrouwend zijn, afhankelijk van de context. Inzicht in deze dubbele vertekeningen biedt een routekaart voor het ontwerpen van interfaces en trainingsmethoden die AI-systemen richting meer gebalanceerd, transparant redeneren sturen—en helpt gebruikers inschatten wanneer ze de machine moeten vertrouwen, bevragen of dubbelchecken.
Bronvermelding: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
Trefwoorden: grote taalmodellen, vertrouwensvertekening, besluitvorming, AI-betrouwbaarheid, mens–AI-interactie