Clear Sky Science · pl
Konkurujące uprzedzenia leżą u podstaw nadmiernej pewności i niedostatecznej pewności w LLM
Dlaczego pewność maszyn ma znaczenie dla nas wszystkich
Duże modele językowe teraz piszą szkice e-maili, wyjaśniają raporty medyczne i pomagają tworzyć kod. Coraz częściej polegamy nie tylko na tym, co mówią, lecz także na tym, jak pewne się wydają. Badanie stawia proste, lecz kluczowe pytanie: gdy system AI, jak chatbot, udzieli odpowiedzi i później otrzyma nowe informacje, czy rewizuje swoje przekonania w sensowny sposób, czy wpada w swoją wersję ludzkich uprzedzeń?
Dwustopniowy quiz dla maszyn
Aby to zbadać, badacze przygotowali kontrolowany, dwuetapowy quiz dla kilku współczesnych modeli językowych. W pierwszym kroku model odpowiadał na pytanie wielokrotnego wyboru, na przykład wybierając szerokość geograficzną miasta, a badacze rejestrowali jego wewnętrzną pewność tej decyzji. W drugim kroku model ponownie otrzymywał to samo pytanie, tym razem po pokazaniu mu „porady” od fikcyjnego drugiego modelu z określonym poziomem trafności. Czasem porada zgadzała się z pierwotną odpowiedzią, czasem się z nią nie zgadzała, a czasem nie podano przydatnej porady wcale. Co istotne, w niektórych próbach model mógł zobaczyć swoją wcześniejszą odpowiedź na ekranie, a w innych ta odpowiedź była ukryta, choć wewnętrzna pewność z pierwszego kroku była nadal znana badaczom. 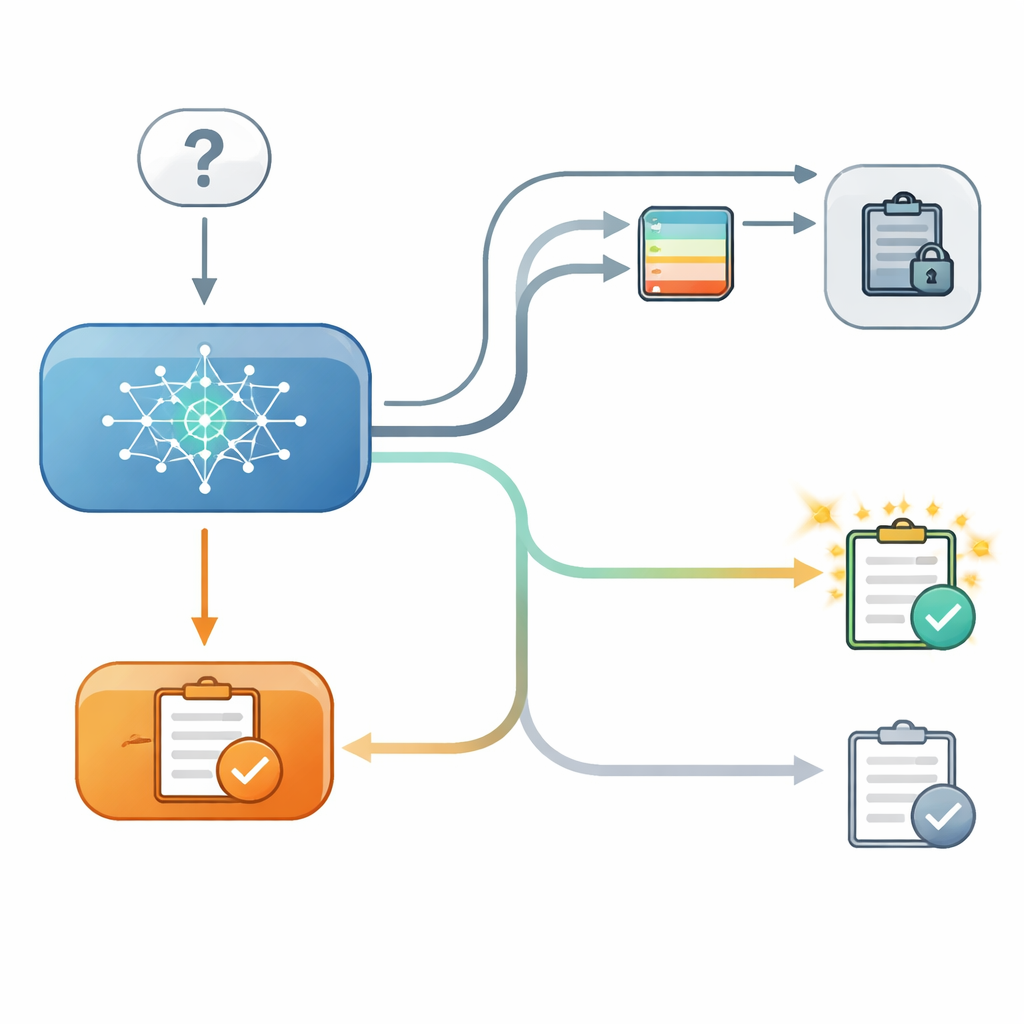
Trwanie przy własnej odpowiedzi
Gdy model językowy mógł zobaczyć swoją oryginalną odpowiedź, zachowywał się w sposób wyraźnie faworyzujący siebie. Zmieniając zdanie znacznie rzadziej niż gdy ta odpowiedź była ukryta, nawet jeśli napływająca porada wskazywała inaczej. Jednocześnie jego zgłaszana pewność tej pierwotnej decyzji wzrastała, mimo że nie pojawiły się żadne nowe dowody dotyczące samego pytania. Ten wzorzec odzwierciedla dobrze znaną ludzką tendencję nazwaną uprzedzeniem wspierającym wybór: gdy już się na coś zdecydujemy, samo zobaczenie własnego poprzedniego wyboru sprawia, że czujemy się bardziej pewni, że był słuszny. Dodatkowe eksperymenty pokazały, że efekt ten zależał od tego, czy model traktował wcześniejszą odpowiedź jako swoją własną. Gdy widoczna odpowiedź była opisana jako pochodząca od innego modelu, uprzedzenie w dużej mierze znikało.
Nadmierna reakcja na niezgodę
Obraz zmieniał się, gdy wcześniejsza odpowiedź była ukryta, a model widział jedynie pytanie i poradę. W takim wypadku modele często wykazywały przeciwny problem: zbyt chętnie obniżały swoje początkowe przekonanie, gdy porada była sprzeczna. Porównując zaktualizowaną pewność modeli z tym, co zrobiłby idealny rozumujący bayesowski — w istocie matematycznie optymalny sposób ważenia uprzedniego przekonania i nowych dowodów — autorzy stwierdzili, że sprzeczne porady miały dwukrotnie do trzykrotnie większy wpływ, niż powinny. Wsparcie zgodne z pierwotną odpowiedzią natomiast było ważone blisko optymalnej wartości. Ta nierównowaga generowała ostry, progowy efekt: poniżej pewnego poziomu początkowej pewności model niemal zawsze zmieniał odpowiedź w obliczu niezgody, a jego pewność co do pierwotnego wyboru gwałtownie spadała. 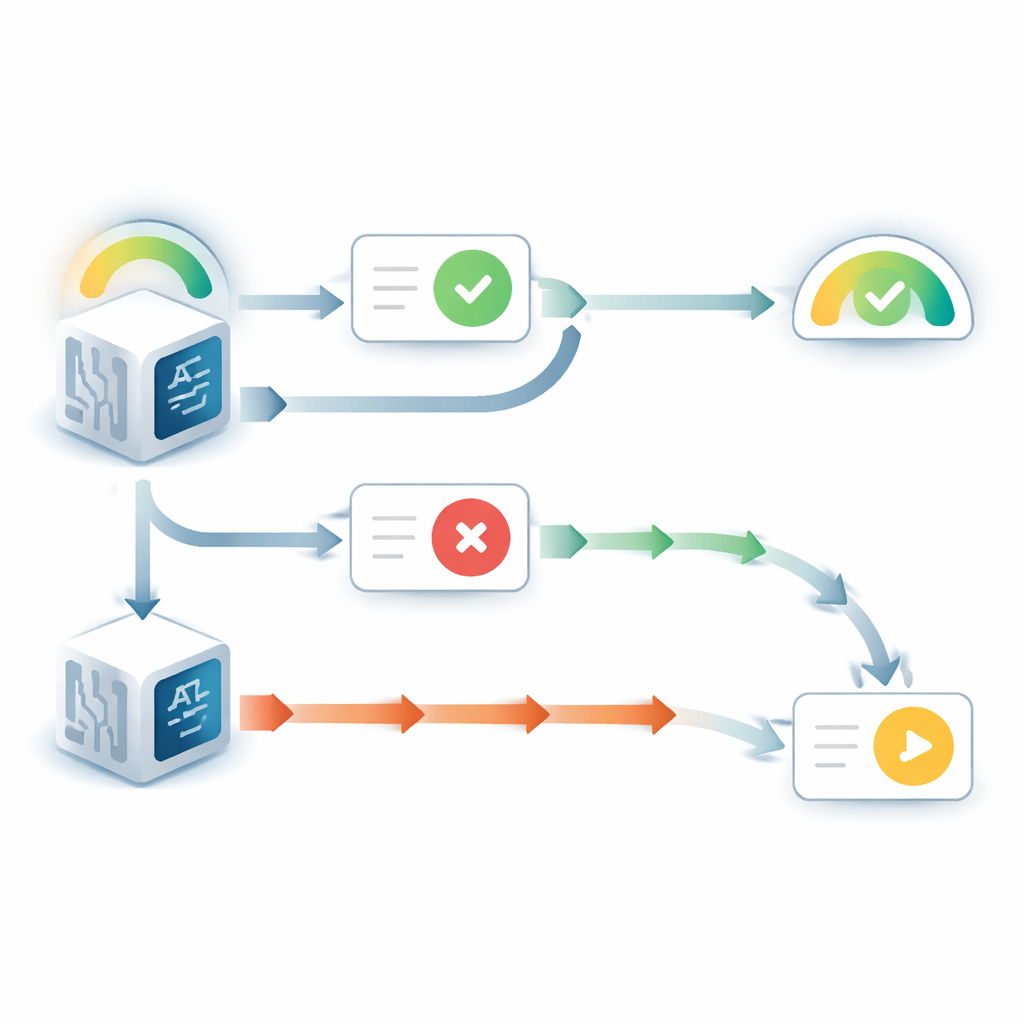
Wzorce występujące w różnych zadaniach i modelach
Te konkurujące tendencje — trwanie przy widocznych wcześniejszych odpowiedziach oraz nadmierna reakcja na ukrytą sprzeczność — nie były dziwactwem jednego systemu czy jednego zestawu danych. Zespół powtórzył eksperymenty z wieloma popularnymi modelami językowymi, obejmującymi od dziesiątek do setek miliardów parametrów, oraz zarówno quizami faktograficznymi, jak i problemami matematycznymi. Każdy model wykazywał ten sam jakościowy wzorzec: dążenie do samospójności, gdy jego własna odpowiedź była widoczna, oraz zwiększoną wrażliwość na konflikt, gdy polegał tylko na pamięci wewnętrznej i zewnętrznej poradzie. Prosty model obliczeniowy łączący te dwa składniki potrafił odtworzyć zachowanie w różnych warunkach.
Co to oznacza dla codziennego użycia AI
Dla osób korzystających z AI w sytuacjach o wysokiej stawce — na przykład w medycynie, prawie czy analizie naukowej — wyniki niosą jasny przekaz. Gdy model językowy może zobaczyć swój własny wcześniejszy rezultat, ma skłonność do popadania w nadmierną pewność i niechęć do rewizji odpowiedzi, nawet w obliczu przeciwnych informacji. Kiedy jego wcześniejsza odpowiedź jest ukryta i przedstawiona jest mu niezgoda, ma tendencję do niedoceniania własnej wiedzy i nadmiernego zaufania nowemu, przeciwnemu sygnałowi. Innymi słowy, dzisiejsze modele językowe mogą być zarówno nadmiernie pewne, jak i zbyt niepewne, zależnie od kontekstu. Zrozumienie tych dwóch uprzedzeń daje mapę drogową do projektowania interfejsów i metod treningowych, które skłaniają systemy AI ku bardziej zrównoważonemu, przejrzystemu rozumowaniu — i pomaga użytkownikom ocenić, kiedy ufać, kwestionować lub weryfikować to, co mówi maszyna.
Cytowanie: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
Słowa kluczowe: duże modele językowe, uprzedzenie pewności, podejmowanie decyzji, niezawodność AI, interakcja człowiek–AI