Clear Sky Science · it
Bias in competizione spiegano sovrafiducia e sfiducia nei LLM
Perché la fiducia delle macchine ci riguarda tutti
I grandi modelli di linguaggio ora redigono email, spiegano referti medici e aiutano a scrivere codice. Facciamo sempre più affidamento non solo su ciò che dicono, ma anche su quanto appaiono sicuri. Questo studio pone una domanda semplice ma cruciale: quando un sistema di IA come una chatbot dà una risposta e poi vede nuove informazioni, rivede le proprie convinzioni in modo sensato, o cade vittima di una sua versione di bias umano?
Un test in due fasi per le macchine
Per indagare la questione, i ricercatori hanno predisposto un quiz controllato in due fasi per diversi modelli di linguaggio moderni. Nella prima fase, un modello rispondeva a una domanda a scelta multipla, per esempio scegliendo la latitudine di una città, e i ricercatori registravano quanto fosse internamente confidente in quella scelta. Nella seconda fase, al modello veniva posta di nuovo la stessa domanda, questa volta dopo avergli mostrato un “consiglio” proveniente da un secondo modello fittizio con un livello di accuratezza dichiarato. Talvolta il consiglio concordava con la risposta originale, talvolta era in disaccordo, e altre volte non veniva fornito alcun consiglio utile. Cruciale: in alcuni trial il modello poteva vedere la sua risposta precedente sullo schermo, in altri quella risposta era nascosta, anche se la fiducia interna del modello nella prima fase era comunque nota ai ricercatori. 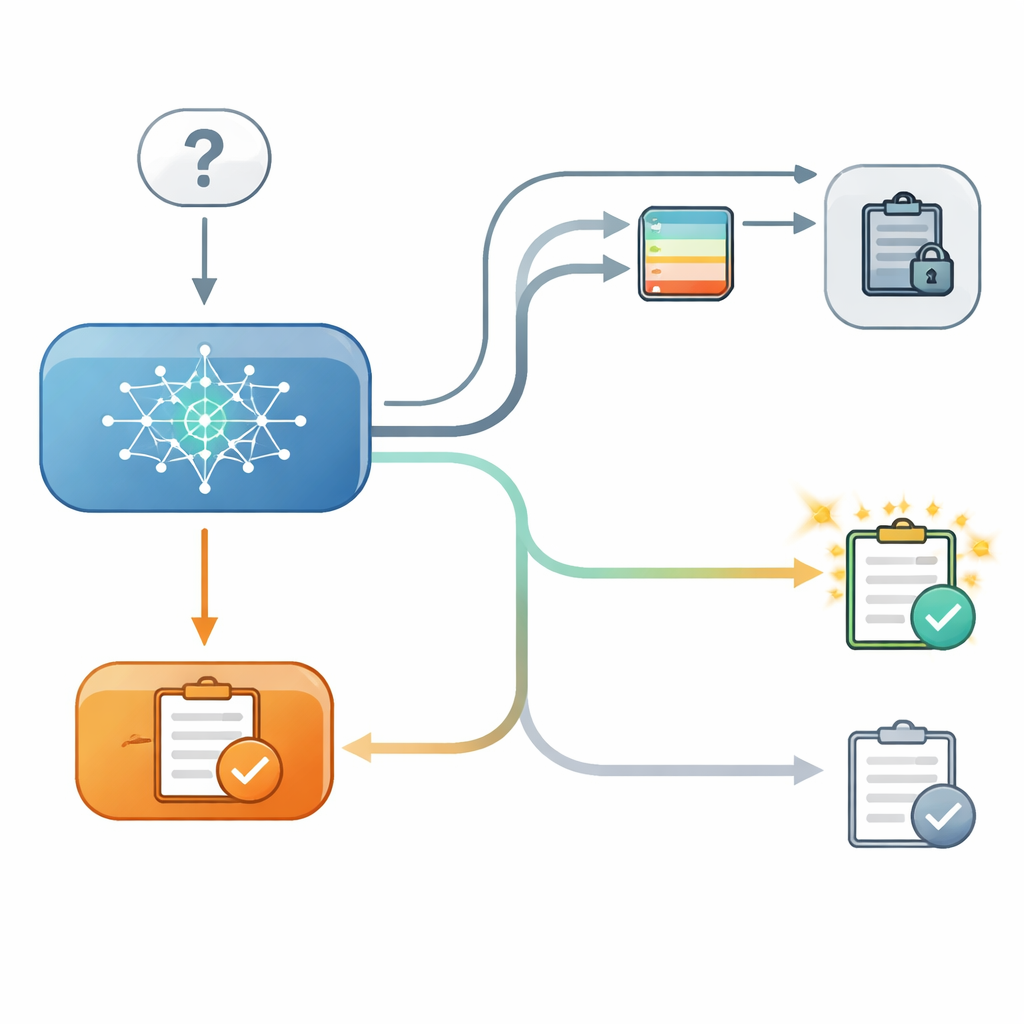
Attaccarsi alla propria risposta
Quando il modello di linguaggio poteva vedere la sua risposta originale, si comportava in modo sorprendentemente auto‑favorente. Cambiava idea molto meno spesso rispetto a quando quella risposta era nascosta, anche se il consiglio entrante indicava il contrario. Allo stesso tempo, la fiducia riportata in quella scelta originale aumentava, nonostante non fosse emersa nuova evidenza sulla domanda stessa. Questo schema rispecchia una tendenza umana ben nota chiamata bias “a supporto della scelta”: una volta che ci impegniamo in una decisione, il semplice vedere la nostra scelta passata ci fa sentire più certi che fosse giusta. Esperimenti aggiuntivi hanno mostrato che questo effetto dipendeva dal fatto che il modello trattasse la risposta precedente come propria. Quando la risposta visibile veniva descritta come proveniente da un modello diverso, il bias scompariva in gran parte.
Sovrareagire al disaccordo
La storia cambiava quando la risposta precedente era nascosta e il modello vedeva solo la domanda più il consiglio. In quel caso, i modelli mostravano spesso il problema opposto: erano troppo pronti a declassare la loro convinzione iniziale quando il consiglio era in disaccordo. Confrontando la fiducia aggiornata dei modelli con ciò che farebbe un ragionatore bayesiano ideale—cioè il modo matematicamente ottimale di pesare la credenza precedente e la nuova evidenza—gli autori hanno scoperto che il consiglio contraddittorio riceveva due‑tre volte l’influenza che avrebbe dovuto avere. Il consiglio che confermava, invece, veniva pesato vicino alla quantità ottimale. Questo squilibrio produceva un comportamento netto, simile a una soglia: al di sotto di un certo livello di fiducia iniziale, il modello quasi sempre capovolgeva la risposta di fronte al disaccordo, e la sua fiducia nella scelta originale crollava. 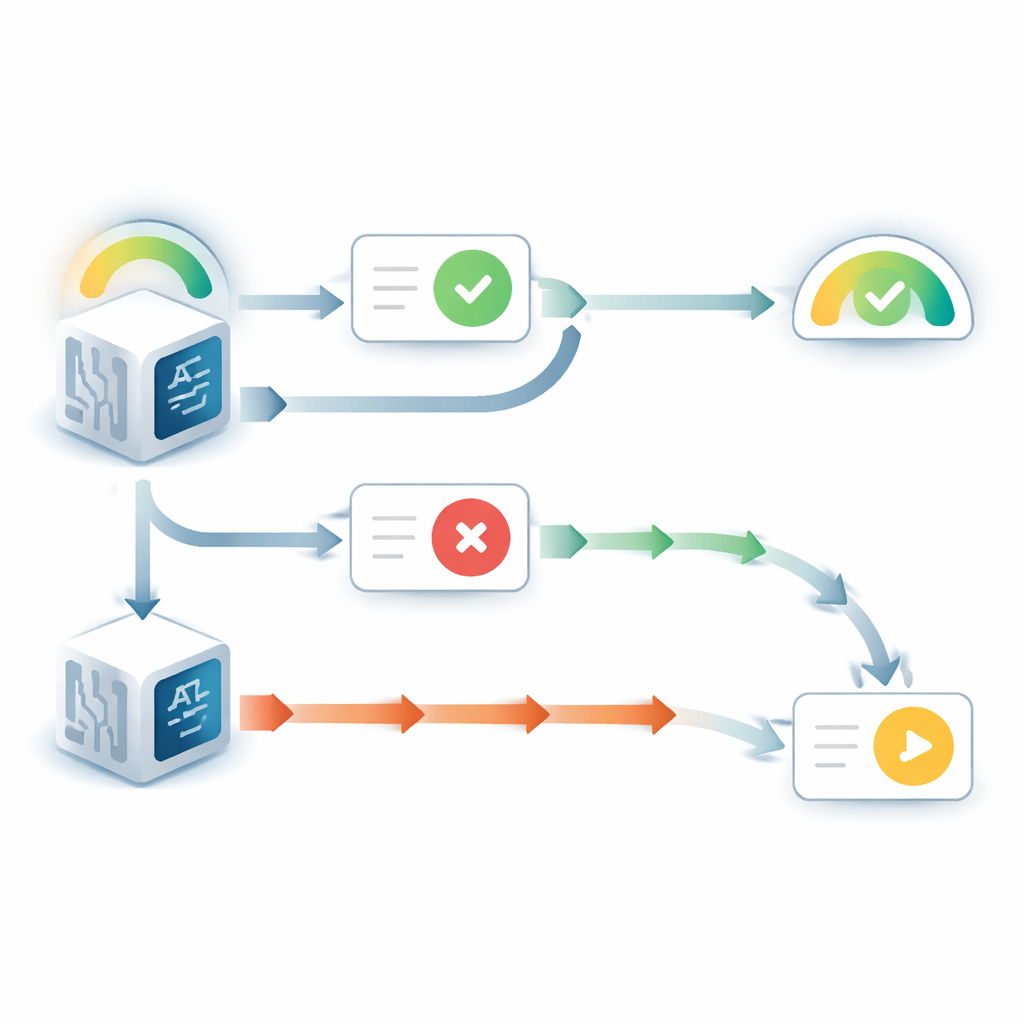
Pattern che si mantengono tra compiti e modelli
Queste tendenze concorrenti—attaccarsi alle risposte passate visibili e sovrareagire al consiglio contraddittorio non visto—non erano peculiarità di un singolo sistema o dataset. Il team ha ripetuto gli esperimenti con più modelli di linguaggio popolari, da decine a centinaia di miliardi di parametri, e sia su quiz fattuali sia su problemi di ragionamento matematico. Ogni modello ha mostrato lo stesso andamento qualitativo: una spinta alla coerenza quando la propria risposta era in vista, e una sensibilità aumentata al conflitto quando si faceva affidamento solo sulla memoria interna e sul consiglio esterno. Un semplice modello computazionale che combinava questi due ingredienti è riuscito a riprodurre il comportamento osservato nei diversi contesti.
Che cosa significa per l'uso quotidiano dell'IA
Per chi usa l'IA in contesti ad alto rischio—come medicina, diritto o analisi scientifica—questi risultati trasmettono un messaggio chiaro. Quando un modello di linguaggio può vedere il proprio output precedente, è incline a diventare sovra‑fiducioso e riluttante a rivedere quella risposta, anche di fronte a informazioni contrarie. Quando la sua risposta precedente è nascosta e gli viene presentato un disaccordo, tende a sottovalutare la propria conoscenza e a fidarsi troppo del nuovo indizio opposto. In altre parole, i modelli di linguaggio odierni possono essere sia sovra‑fiduciosi sia sotto‑fiduciosi, a seconda del contesto. Comprendere questi bias gemelli offre una tabella di marcia per progettare interfacce e metodi di addestramento che inducano i sistemi di IA a ragionare in modo più equilibrato e trasparente—e aiuta gli utenti a capire quando fidarsi, mettere in dubbio o ricontrollare ciò che dice la macchina.
Citazione: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
Parole chiave: modelli di linguaggio di grandi dimensioni, bias di fiducia, processo decisionale, affidabilità dell'IA, interazione uomo–IA