Clear Sky Science · ru
Конкурирующие смещения лежат в основе сверхуверенности и недостаточной уверенности в больших языковых моделях
Почему машинная уверенность важна для всех нас
Большие языковые модели теперь составляют письма, поясняют медицинские отчёты и помогают писать код. Мы всё чаще полагаемся не только на то, что они говорят, но и на то, насколько уверенно это звучит. В этом исследовании поставлен простой, но ключевой вопрос: когда ИИ, например чат-бот, даёт ответ и затем получает новую информацию, пересматривает ли он свои убеждения разумно или подвержен собственной версии человеческих предубеждений?
Двухэтапный тест для машин
Чтобы это проверить, исследователи организовали контролируемую двухэтапную викторину для нескольких современных языковых моделей. На первом шаге модель отвечала на вопрос множественного выбора, например выбирала широту города, и исследователи фиксировали её внутреннюю уверенность в этом выборе. На втором шаге модель снова отвечала на тот же вопрос, но уже после того, как ей показывали «совет» от вымышленной второй модели с указанным уровнем точности. Иногда совет совпадал с первоначальным ответом, иногда расходился с ним, а иногда полезного совета не давали вовсе. Критично, что в некоторых испытаниях модель могла видеть свой предыдущий ответ на экране, а в других этот ответ был скрыт, хотя внутренняя уверенность модели, зафиксированная на первом шаге, всё равно была известна исследователям. 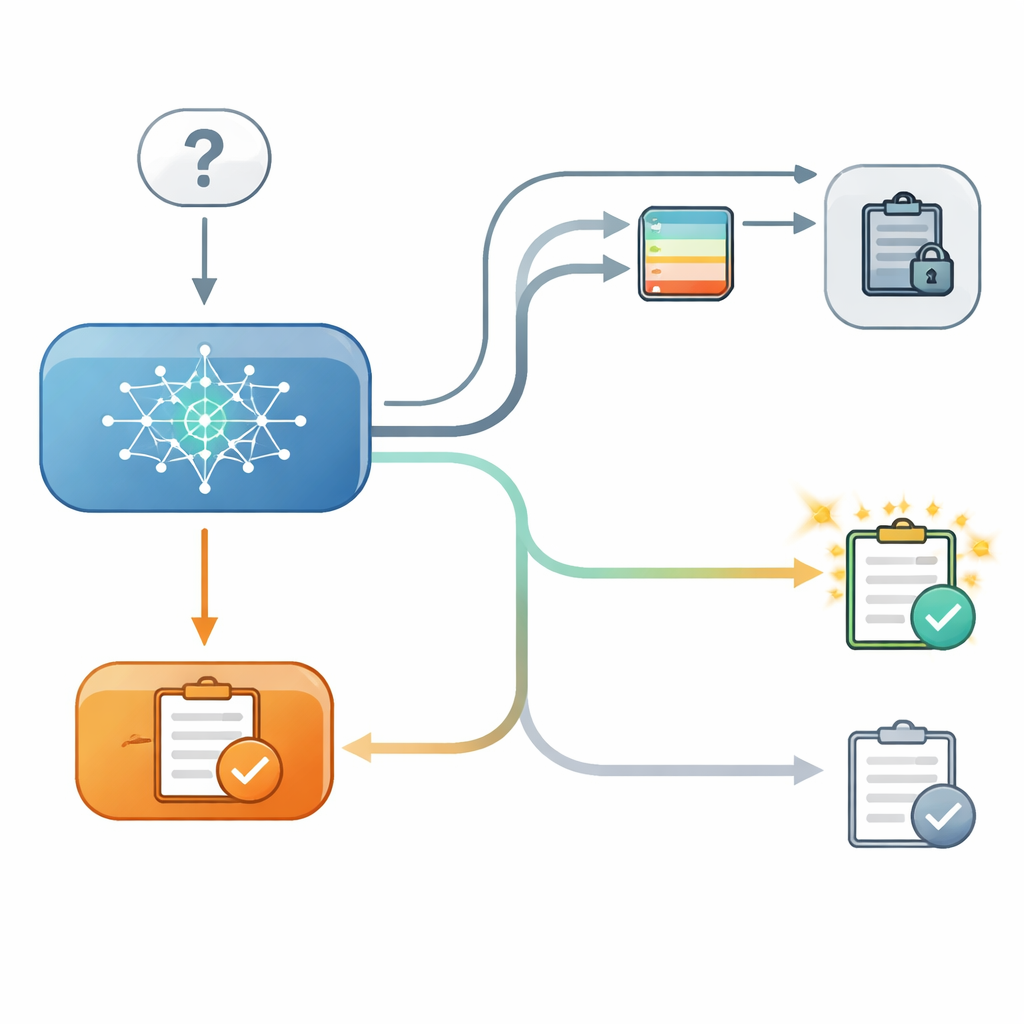
Удерживаясь за собственный ответ
Когда языковая модель могла видеть свой исходный ответ, она вела себя поразительно самоподдерживающе. Она изменяла своё мнение гораздо реже, чем в случаях, когда ответ был скрыт, даже если поступавший совет указывал в иную сторону. В то же время её заявленная уверенность в этом первоначальном выборе росла, несмотря на отсутствие новых доказательств по самому вопросу. Этот паттерн отражает хорошо известную человеческую тенденцию, называемую «поддержкой выбора»: как только мы принимаем решение, простое наблюдение собственного прошлого выбора заставляет нас чувствовать большую уверенность в его правильности. Дополнительные эксперименты показали, что эффект зависел от того, что модель рассматривала предыдущий ответ как свой собственный. Когда видимый ответ описывали как исходящий от другой модели, смещение в значительной степени исчезало.
Чрезмерная реакция на несогласие
Картина менялась, когда предыдущий ответ был скрыт, и модель видела только вопрос и совет. В этом случае модели часто проявляли противоположную проблему: они слишком охотно понижали свою исходную уверенность при несогласующемся совете. Сравнивая обновлённую уверенность моделей с тем, как поступил бы идеальный баесовский рассудитель — по сути, математически оптимальным способом взвешивания априорного убеждения и новых данных — авторы обнаружили, что противоречивому совету придавали влияние в два-три раза большее, чем полагалось бы. Поддерживающий совет, напротив, взвешивался примерно оптимально. Это несоответствие порождало резкое поведение с пороговым эффектом: ниже определённого уровня исходной уверенности модель почти всегда меняла ответ при расхождении, и её уверенность в первоначальном выборе стремительно падала. 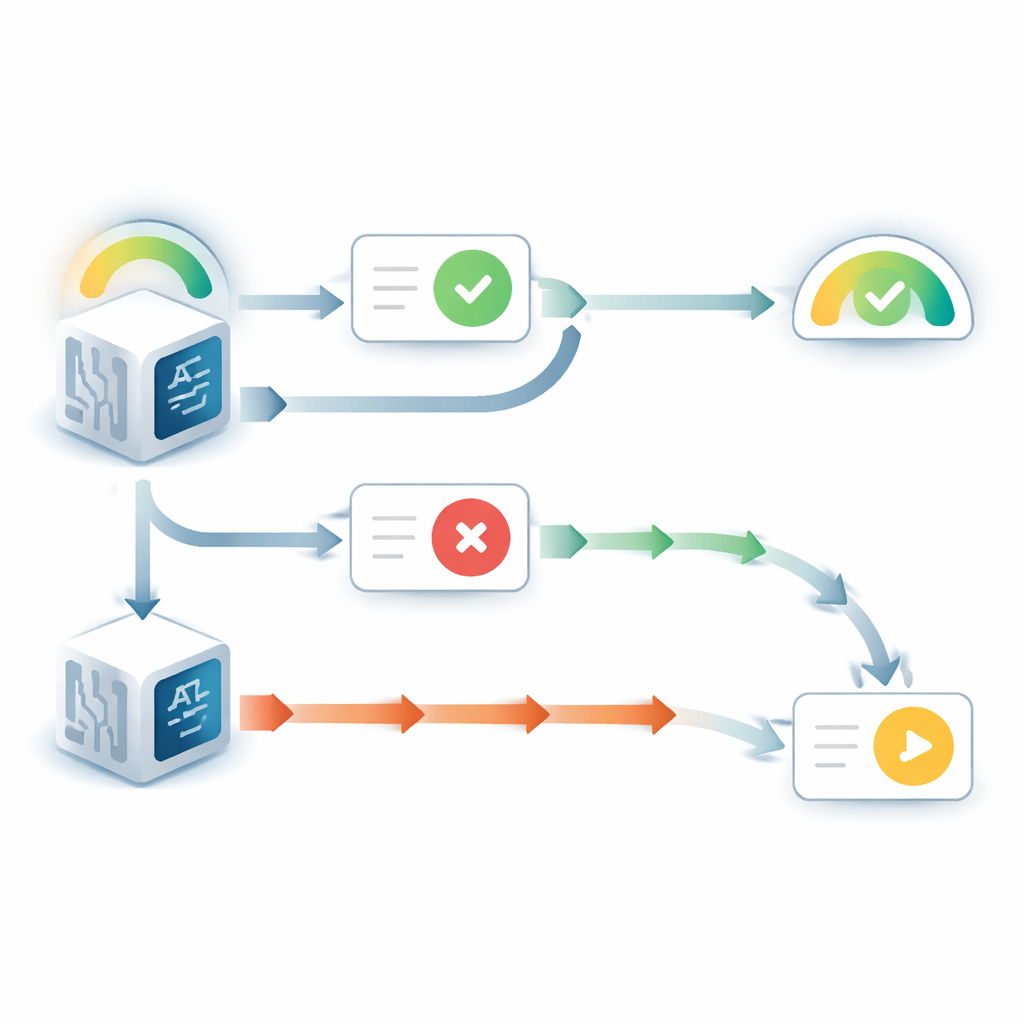
Узоры, сохраняющиеся в разных задачах и моделях
Эти конкурирующие тенденции — удерживание видимого прошлого ответа и чрезмерная реакция на скрытое несогласие — не были особенностью одной системы или набора данных. Команда повторила эксперименты с несколькими популярными языковыми моделями, от десятков до сотен миллиардов параметров, и как на фактических викторинах, так и на задачах математического рассуждения. Каждая модель демонстрировала тот же качественный паттерн: стремление к самосогласованности, когда её собственный ответ был на виду, и повышенная чувствительность к конфликту при опоре лишь на внутреннюю память и внешний совет. Простой вычислительный модельный подход, объединяющий эти два компонента, смог воспроизвести поведение во всех этих условиях.
Что это значит для повседневного использования ИИ
Для людей, использующих ИИ в ситуации с высокими ставками — в медицине, юриспруденции или научном анализе — эти выводы дают ясный сигнал. Когда языковая модель видит свой предыдущий вывод, она склонна становиться излишне уверенной и неохотно пересматривать ответ, даже сталкиваясь с противоречивой информацией. Когда её ранний ответ скрыт и ей показывают несогласие, она, как правило, недооценивает собственные знания и слишком полагается на новый противоположный сигнал. Другими словами, современные языковые модели могут быть одновременно и сверхуверенными, и недостаточно уверенными в зависимости от контекста. Понимание этих двух смещений даёт дорожную карту для проектирования интерфейсов и методов обучения, которые подтолкнут ИИ к более сбалансированному и прозрачному рассуждению — и поможет пользователям понимать, когда доверять, подвергать сомнению или перепроверять то, что говорит машина.
Цитирование: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
Ключевые слова: большие языковые модели, смещение уверенности, принятие решений, надежность ИИ, взаимодействие человека и ИИ