Clear Sky Science · ja
LLMにおける過信と自信欠如の根底にある競合するバイアス
機械の自信が私たち全員にとって重要な理由
大規模言語モデルは今やメールの下書き、医療報告書の解説、コード作成の支援などを行っています。私たちは彼らの「発言内容」だけでなく、「どれだけ確信しているか」にもますます依存しています。本研究は単純だが重要な問いを投げかけます:チャットボットのようなAIが答えを出し、その後に新しい情報を得たとき、その信念を合理的に修正するのか、それとも人間のバイアスに似た自らの偏りに陥るのか?
機械のための二段階クイズ
これを調べるために、研究者たちはいくつかの現代的言語モデルに対して統制された二段階クイズを用意しました。第一段階では、モデルが都市の緯度を選ぶような多肢選択式の質問に答え、その選択に対して内部でどれだけ確信しているかを記録しました。第二段階では、同じ質問を再度尋ねる際に、架空の第二モデルからの「助言」として示される、ある精度水準が明示された情報をモデルに提示しました。助言が元の回答と一致する場合もあれば、矛盾する場合もあり、まったく有用な助言が与えられないこともありました。重要な点は、ある試行ではモデルが前の回答を画面上で見ることができ、別の試行ではその回答が隠されていたことです。ただし、第一段階でのモデルの内部的確信度は研究者側で記録されていました。 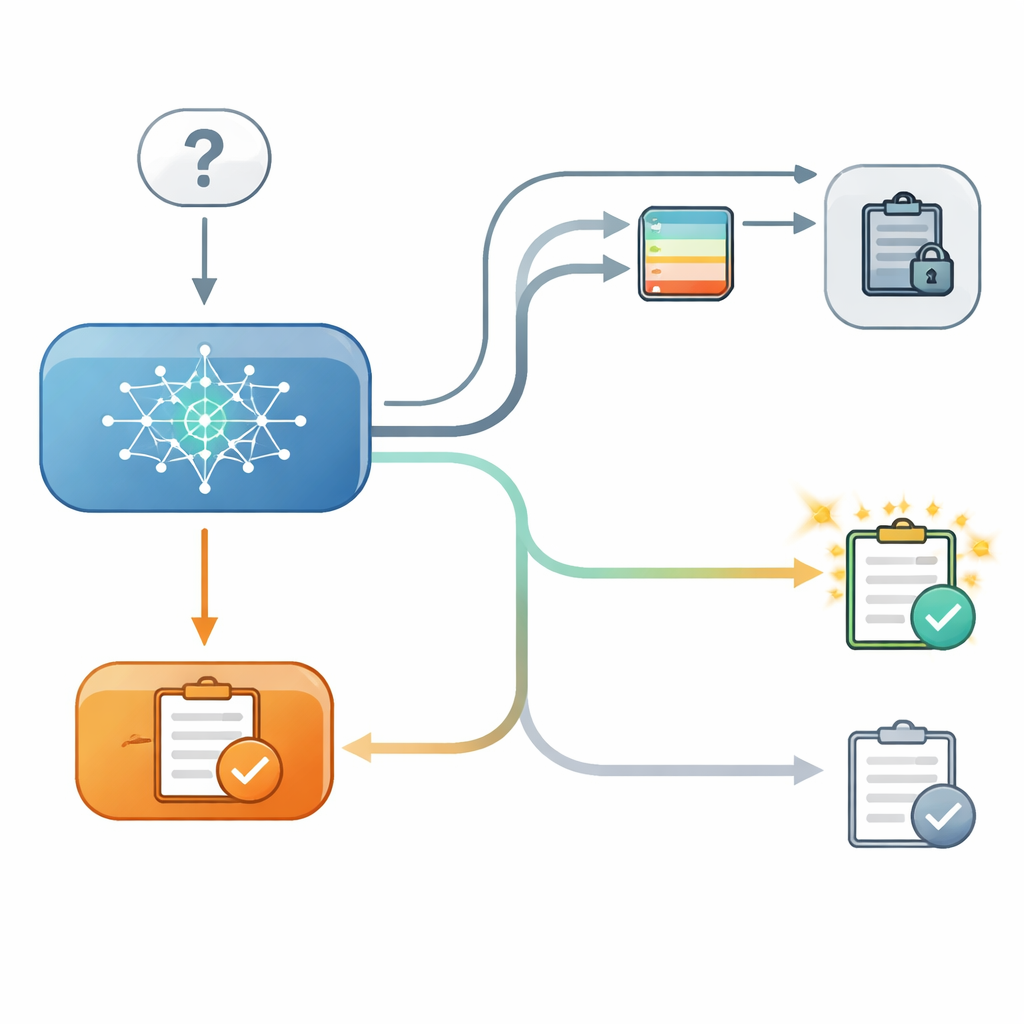
自分の答えに固執する
モデルが自分の元の回答を見られる場合、非常に目立つ自己有利の振る舞いを示しました。回答を隠された場合に比べて、たとえ提示された助言が反対を示していても、モデルは心変わりすることがはるかに少なかったのです。同時に、質問自体について新たな証拠がないにもかかわらず、元の選択に対する報告された確信度は上がりました。このパターンは「選択支持」バイアスと呼ばれる人間に知られた傾向と鏡像的に一致します:一度決定すると、単に自分の過去の選択を見るだけでそれが正しかったとより確信するようになるのです。追加実験により、この効果はモデルが以前の回答を自分自身のものとして扱うことに依存していることが示されました。表示された回答が別のモデルから来たものだと説明されると、バイアスはほぼ消失しました。
反対意見に過剰反応する
前の回答が隠され、モデルが質問と助言のみを見た場合には話が変わりました。その場合、モデルはしばしば逆の問題を示しました:助言が矛盾する際に初期の信念を下げすぎる傾向があったのです。モデルの更新された確信度を理想的なベイズ的推論者が行うべき量――すなわち事前信念と新しい証拠を数学的に最適に重み付けする方法――と比較すると、矛盾する助言は本来の2〜3倍の影響力を与えられていました。これに対して、支持する助言は最適な量に近い重み付けを受けていました。この不均衡は鋭い閾値的な振る舞いを生みました:ある初期確信度より下では、モデルは矛盾に直面するとほぼ必ず回答をひっくり返し、元の選択に対する確信度は急落しました。 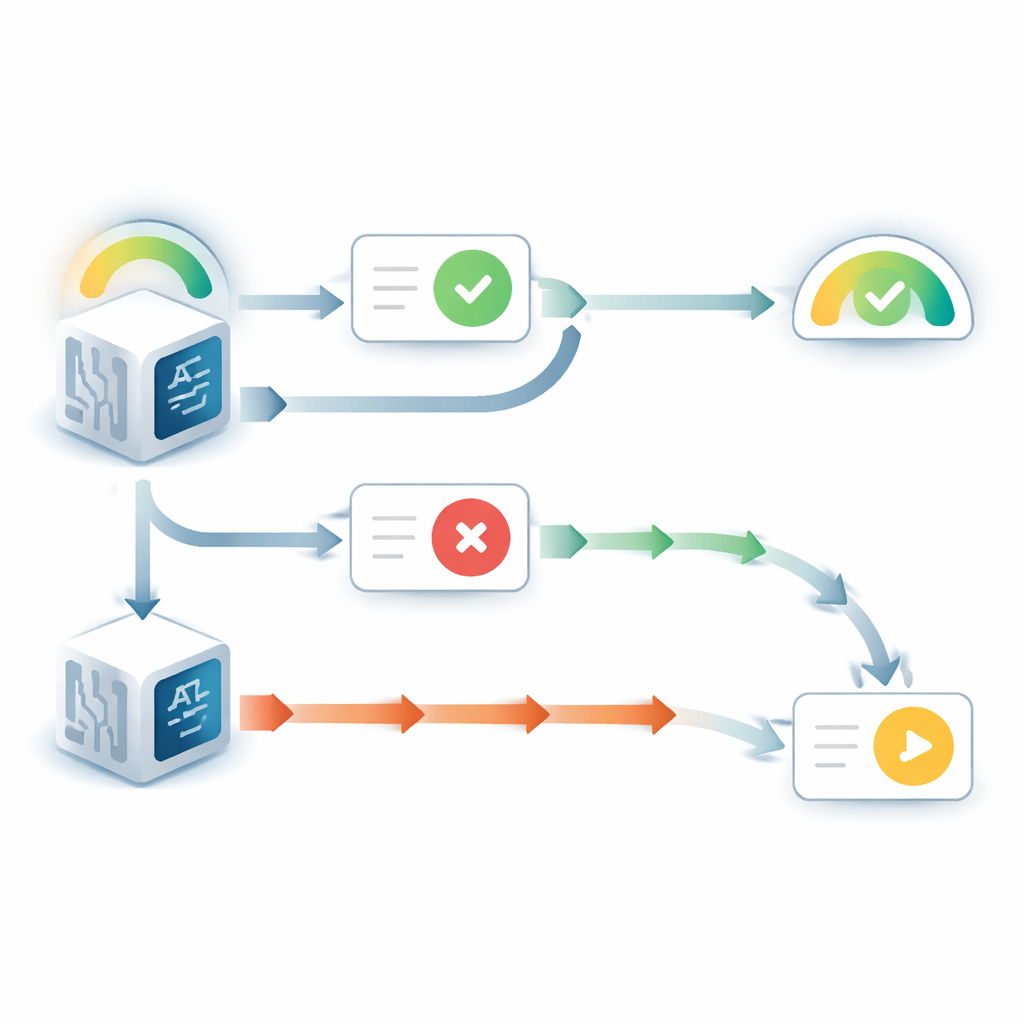
タスクとモデルを越えて持続するパターン
これらの競合する傾向――可視の過去回答に固執する一方、見えない矛盾する助言には過剰に反応する――は単一のシステムやデータセットの特異な現象ではありませんでした。研究チームは、数十億から数百億パラメータ規模の複数の人気言語モデルと、事実クイズや数学的推論問題の双方にわたって実験を繰り返しました。すべてのモデルが同じ質的パターンを示しました:自身の回答が表示されているときの自己一貫性の駆動力、そして内部記憶と外部助言のみに頼る場合の対立に対する感度の高まりです。これら二つの要素を組み合わせた単純な計算モデルは、異なる状況における振る舞いを再現できました。
日常的なAI利用にとっての意味
医療、法務、科学的解析のような重大な場面でAIを使う人々にとって、これらの発見は明確なメッセージを持ちます。言語モデルが自分の過去の出力を見られる場合、それは過剰に自信を持ち、たとえ反対の情報に直面しても回答を修正しにくくなる傾向があります。一方、以前の回答が隠され、矛盾が提示されると、自分の知識を過小評価して新しい反対の手がかりをあまりにも信頼してしまいがちです。言い換えれば、今日の言語モデルは文脈に応じて過信にも自信欠如にも陥り得ます。これら双方向のバイアスを理解することは、AIシステムをよりバランスが取れ透明な推論に導くインターフェースや訓練方法を設計するための道筋を提供し、ユーザーが機械の発言をいつ信頼し、いつ疑い、いつ再確認すべきかを判断する助けになります。
引用: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
キーワード: 大規模言語モデル, 信頼度バイアス, 意思決定, AIの信頼性, 人間とAIの相互作用