Clear Sky Science · ar
تحيزات متنافسة تُفسّر الثقة المفرطة ونقص الثقة في النماذج اللغوية الكبيرة
لماذا تهمنا ثقة الآلات
تقوم النماذج اللغوية الكبيرة الآن بصياغة الرسائل الإلكترونية، وشرح التقارير الطبية، والمساعدة في كتابة الشفرات. نعتمد بشكل متزايد ليس فقط على ما تقوله، بل على مدى اليقين الذي تبدو عليه. تطرح هذه الدراسة سؤالاً بسيطاً لكنه حاسم: عندما يعطي نظام ذكاء اصطناعي مثل الدردشة إجابة ثم يرى معلومات جديدة لاحقاً، هل يراجع معتقداته بطريقة معقولة، أم أنه يقع فريسة لنسخةٍ خاصة به من التحيز البشري؟
اختبار من خطوتين للآلات
لفحص ذلك، أنشأ الباحثون اختبارًا محكماً من مرحلتين لعدة نماذج لغوية حديثة. في الخطوة الأولى، أجاب النموذج على سؤال متعدد الخيارات، مثل اختيار خط العرض لمدينة، وسجّل الباحثون مدى ثقته الداخلية في ذلك الاختيار. في الخطوة الثانية، طُلب من النموذج نفس السؤال مرة أخرى، هذه المرة بعد عرضه على «نصيحة» من نموذج ثانٍ افتراضي مع مستوى دقة مُعلن. أحيانًا كانت النصيحة متوافقة مع الإجابة الأصلية، وأحيانًا كانت متعارضة، وأحيانًا لم تُقدَّم أي نصيحة مفيدة. والأهم أنَّ في بعض التجارب كان بإمكان النموذج رؤية إجابته السابقة على الشاشة، وفي تجارب أخرى كانت تلك الإجابة مخفية، رغم أن الباحثين ما زالوا يعرفون ثقة النموذج الداخلية من الخطوة الأولى. 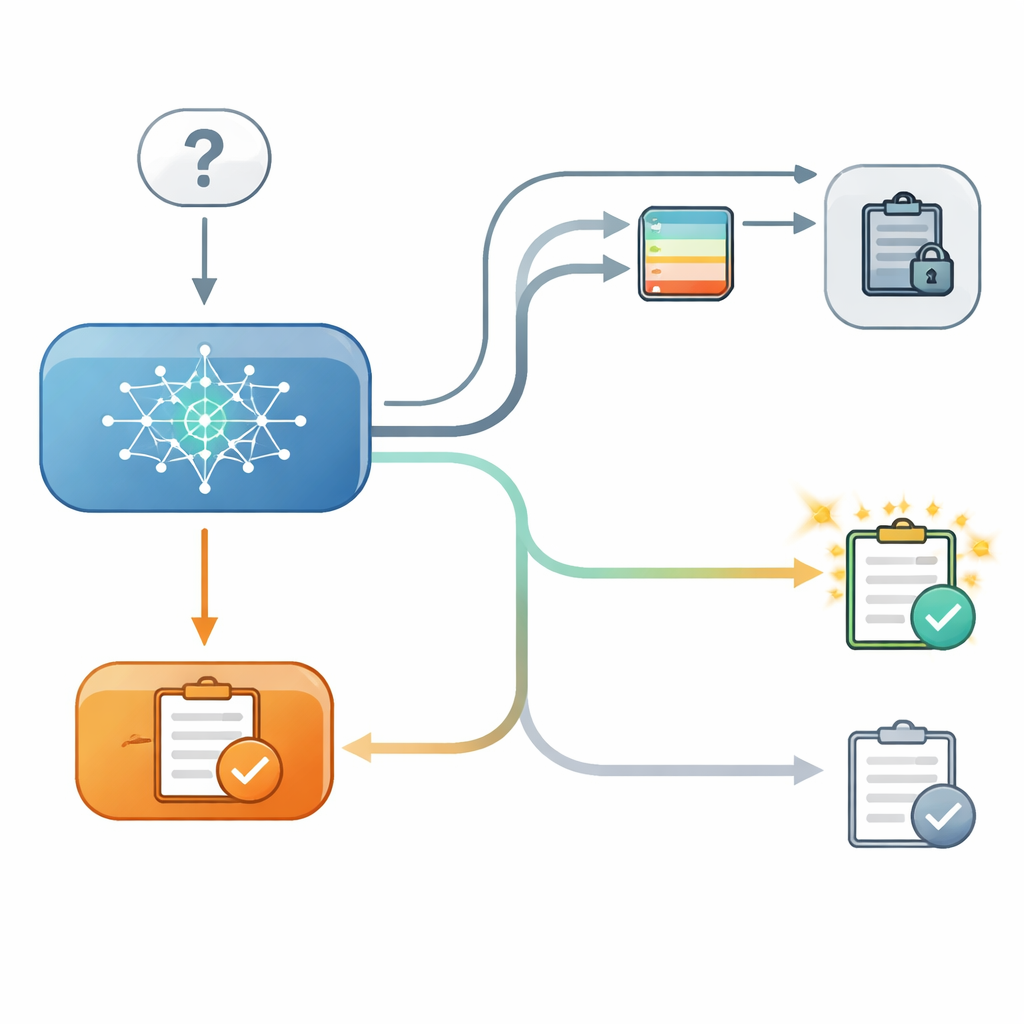
التمسّك بالإجابة الذاتية
عندما كان بإمكان النموذج رؤية إجابته الأصلية، تصرّف بطريقة تُظهر تحيزًا واضحًا لصالح ذاته. نادرًا ما كان يغيّر رأيه مقارنةً بحالته عندما كانت الإجابة مخفية، حتى لو كانت النصيحة الواردة تشير إلى الاتجاه المعاكس. وفي الوقت نفسه، ارتفعت الثقة المُعلن عنها في ذلك الاختيار الأصلي، رغم عدم وجود دليل جديد على السؤال نفسه. يعكس هذا النمط ميلًا بشريًا معروفًا يُدعى «تحيّز دعم الاختيار»: عندما نلتزم بقرار، فإن مجرد رؤية اختيارنا السابق تجعلنا نشعر بمزيد من اليقين بصحته. أظهرت تجارب إضافية أن هذا التأثير اعتمد على تعامل النموذج مع الإجابة السابقة على أنها تخصه. عندما وُصفت الإجابة الظاهرة بأنها صادرة عن نموذج مختلف، اختفى التحيّز إلى حد كبير.
المبالغة في الاستجابة للاختلاف
تغيّرت القصة عندما كانت الإجابة السابقة مخفية ورأى النموذج السؤال مع النصيحة فقط. في تلك الحالة، أبدى النماذج غالبًا المشكلة المعاكسة: كانت مستعدة بسهولة لخفض اعتقادها الأولي عندما اختلفت النصيحة. بمقارنة ثقة النماذج المحدثة مع ما سيقوم به مُحايس بايزي مثالي—بمعنى الطريقة الرياضية المثلى لموازنة الاعتقاد السابق والدليل الجديد—وجد المؤلفون أن النصائح المتعارضة حُكمت لها بتأثير أكبر بمقدار مرتين إلى ثلاث مرات مما ينبغي. أما النصائح المساندة فكانت موزونة قرب المقدار الأمثل. أنتج هذا الاختلال سلوكًا عتبيًا حادًا: تحت مستوى معين من الثقة المبدئية، كان النموذج يكاد دائمًا يغيّر إجابته عند مواجهة اختلاف، وتسقط ثقته في الاختيار الأصلي بشكل حاد. 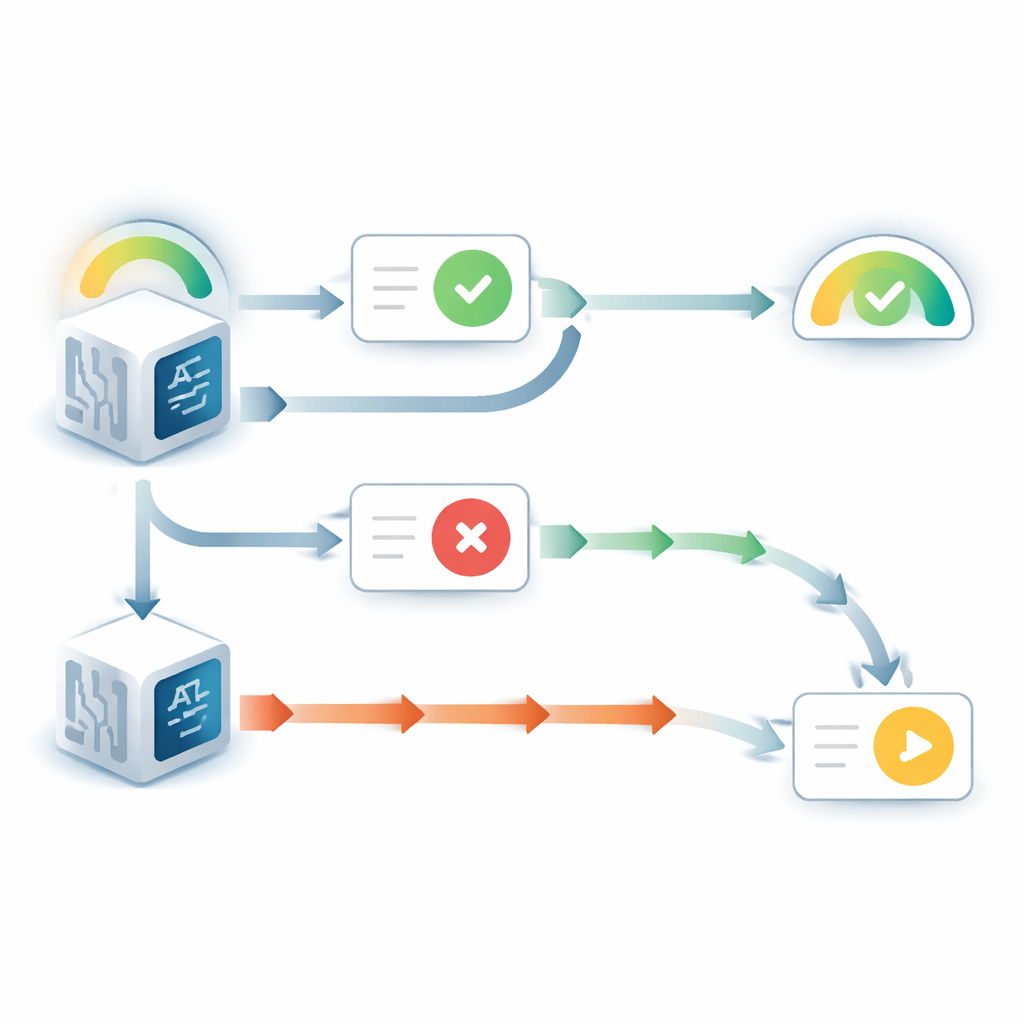
أنماط ثابتة عبر المهام والنماذج
لم تكن هاتان النزعتان المتنافستان—التمسّك بالإجابات السابقة الظاهرة، والمبالغة في الاستجابة للنصائح المتعارضة غير المرئية—سمات خاصة بنظام واحد أو مجموعة بيانات بعينها. كرر الفريق التجارب مع عدة نماذج لغوية شائعة، تتراوح أحجامها من عشرات إلى مئات المليارات من المعاملات، وعبر اختبارات معلوماتية ومسائل استدلال رياضي. أظهر كل نموذج نفس النمط النوعي: دافع نحو الثبات الذاتي عندما كانت إجابته في متناول الرؤية، وحساسية متزايدة للصراع عند الاعتماد فقط على الذاكرة الداخلية والنصيحة الخارجية. استطاع نموذج حسابي بسيط يجمع هذين المكوّنَين أن يلتقط سلوك النماذج عبر هذه الإعدادات المختلفة.
ما معنى هذا لاستخدامات الذكاء الاصطناعي اليومية
بالنسبة للأشخاص الذين يستخدمون الذكاء الاصطناعي في مواقف ذات مخاطر عالية—مثل الطب أو القانون أو التحليل العلمي—تحمل هذه النتائج رسالة واضحة. عندما يمكن للنموذج اللغوي رؤية مخرجه السابق، فإنه معرض لأن يصبح واثقًا بشكل مفرط ومترددًا في مراجعة تلك الإجابة، حتى عند مواجهته بمعلومات معارضة. وعندما تكون إجابته السابقة مخفية ويُعرض عليه اختلاف، فإنه يميل إلى التقليل من قيمة معرفته الخاصة ويثق في الإشارة المعارضة الجديدة أكثر من اللازم. بعبارة أخرى، يمكن لنماذج اللغات الحالية أن تكون واثقة زيادةً أو ناقصةً اعتمادًا على السياق. إن فهم هذين التحيزين المزدوجين يوفر خارطة طريق لتصميم واجهات وطرق تدريب تُوجّه أنظمة الذكاء الاصطناعي نحو استدلال أكثر توازنًا وشفافية—وتساعد المستخدمين على تفسير متى يثقون، ومتى يشكّون، أو يتأكدون من صحة ما يقوله الجهاز.
الاستشهاد: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
الكلمات المفتاحية: النماذج اللغوية الكبيرة, تحيّز الثقة, اتخاذ القرار, موثوقية الذكاء الاصطناعي, تفاعل الإنسان–الذكاء الاصطناعي