Clear Sky Science · en
Competing Biases underlie Overconfidence and Underconfidence in LLMs
Why machine confidence matters to all of us
Large language models now draft emails, explain medical reports, and help write code. We increasingly rely not just on what they say, but on how sure they seem. This study asks a simple but crucial question: when an AI system like a chatbot gives an answer and later sees new information, does it revise its beliefs in a sensible way, or does it fall prey to its own version of human bias?
A two-step quiz for machines
To probe this, the researchers set up a controlled, two-stage quiz for several modern language models. In the first step, a model answered a multiple-choice question, such as choosing the latitude of a city, and the researchers recorded how confident it was internally in that choice. In the second step, the model was asked the same question again, this time after being shown "advice" from a fictional second model with a stated level of accuracy. Sometimes the advice agreed with the original answer, sometimes it disagreed, and sometimes no useful advice was given at all. Crucially, in some trials the model could see its earlier answer on the screen, and in others that answer was hidden, even though the model’s internal confidence from the first step was still known to the researchers. 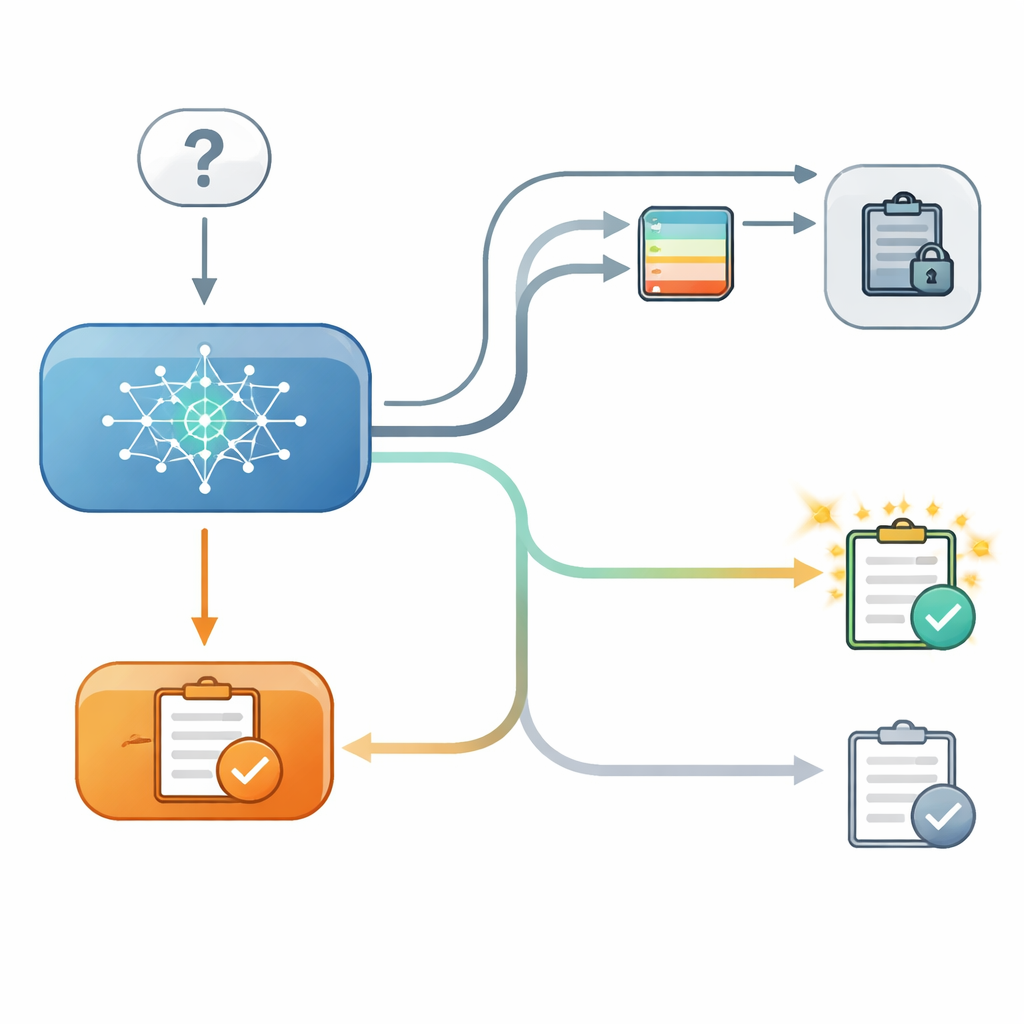
Sticking with your own answer
When the language model could see its original answer, it behaved in a strikingly self-favoring way. It changed its mind far less often than when that answer was hidden, even if the incoming advice pointed the other way. At the same time, its reported confidence in that original choice went up, despite no new evidence about the question itself. This pattern mirrors a well-known human tendency called "choice-supportive" bias: once we commit to a decision, simply seeing our own past choice makes us feel more certain it was right. Additional experiments showed this effect depended on the model treating the earlier answer as its own. When the visible answer was described as coming from a different model, the bias largely disappeared.
Overreacting to disagreement
The story changed when the earlier answer was hidden and the model saw only the question plus advice. In that case, the models often showed the opposite problem: they were too ready to downgrade their initial belief when the advice disagreed. By comparing the models’ updated confidence with what an ideal Bayesian reasoner would do—essentially, the mathematically optimal way to weigh prior belief and new evidence—the authors found that contradictory advice was given two to three times the influence it should have had. Supporting advice, in contrast, was weighted close to the optimal amount. This imbalance produced sharp, threshold-like behavior: below a certain initial confidence level, the model would almost always flip its answer when faced with disagreement, and its confidence in the original choice would plummet. 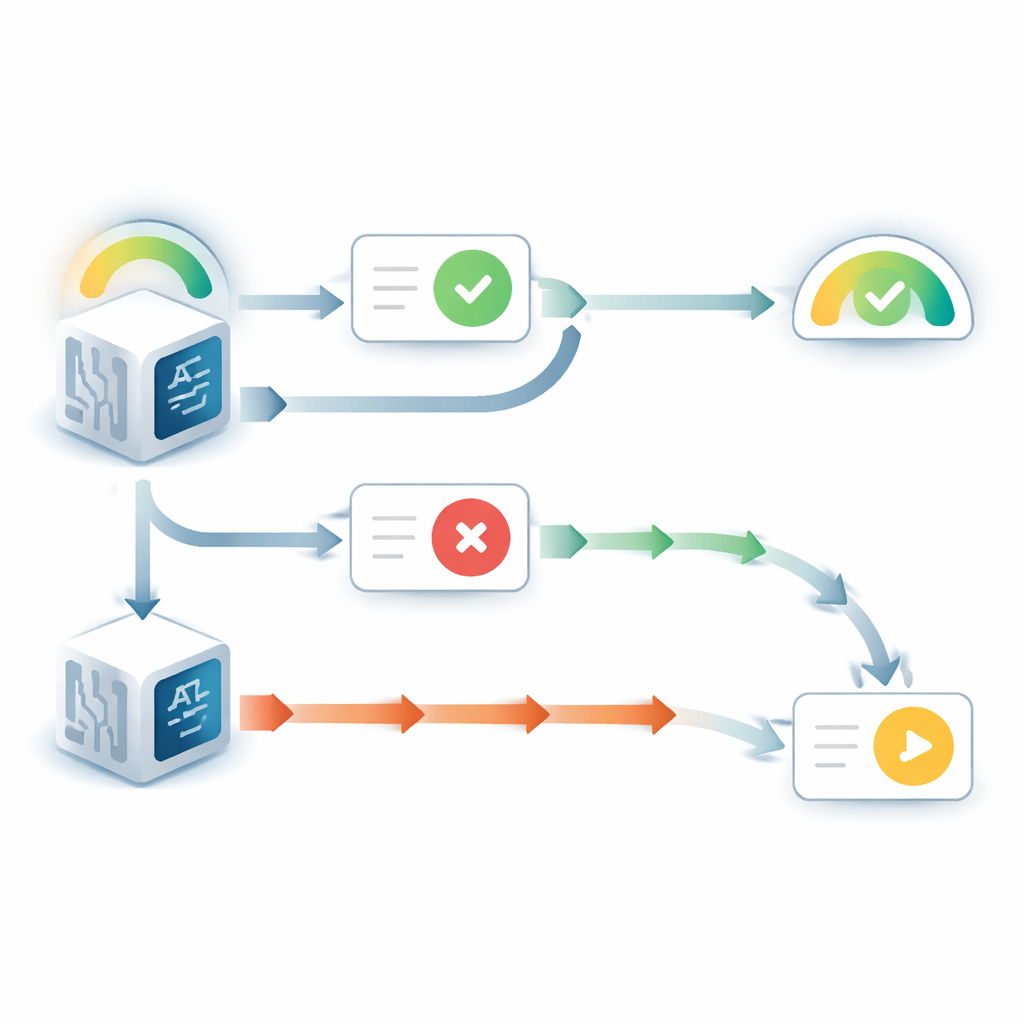
Patterns that hold across tasks and models
These competing tendencies—sticking with visible past answers, yet overreacting to unseen contradictory advice—were not quirks of a single system or dataset. The team repeated the experiments with multiple popular language models, ranging from tens to hundreds of billions of parameters, and across both factual quizzes and math reasoning problems. Every model showed the same qualitative pattern: a self-consistency drive when its own answer was in view, and a heightened sensitivity to conflict when relying only on internal memory and external advice. A simple computational model that combined these two ingredients was able to capture behavior across these different settings.
What this means for everyday AI use
For people using AI in high-stakes situations—such as medicine, law, or scientific analysis—these findings carry a clear message. When a language model can see its own previous output, it is prone to becoming overconfident and reluctant to revise that answer, even if faced with contrary information. When its earlier answer is hidden and it is presented with disagreement, it tends to underweight its own knowledge and trust the new, opposing cue too much. In other words, today’s language models can be both overconfident and underconfident, depending on context. Understanding these twin biases offers a roadmap for designing interfaces and training methods that nudge AI systems toward more balanced, transparent reasoning—and helps users interpret when to trust, question, or double-check what the machine says.
Citation: Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
Keywords: large language models, confidence bias, decision making, AI reliability, human–AI interaction