Clear Sky Science · zh
健康数据与生物标志物的匿名化与可视化
为什么你的病历这么难以共享
现代医学依赖数据:研究者能分析的病历越多,就越能理解疾病并改进治疗方法。但严格的隐私规定导致大量信息被封存,尤其是来自医院和生物样本库的详细记录。本文介绍了一种实用方法,用以创建看起来真实的“假”健康数据集,在保护个人隐私的同时仍对研究有用,可能为全球范围内更安全的数据共享开辟路线。
将封锁记录变成安全的“相似体”
研究团队构建了一个端到端系统,将敏感健康记录转换为合成数据——这些记录在统计上看起来与真实数据一致,但不对应任何实际个人。该框架从对超过5万名瑞典北部个体的医院病例、问卷、化验和癌症登记数据进行细致清洗与组织开始。一个单一的配置文件描述了存在的变量、应如何处理以及适用的隐私限制,使每一步都透明且可复现。该系统作为开源软件打包在容器中分发,使医院和研究中心更容易部署,无需处理复杂安装。 
合成数据工厂如何工作
数据准备好后,多种先进的人工智能模型(包括不同类型的深度生成网络)被训练以模拟真实数据集中的模式。最突出的是名为TabSyn的模型——一种基于变换器的扩散方法,最初为复杂的数值和类别表格开发。团队为其增加了一个特殊的损失函数CorrDst,该函数明确奖励模型既正确再现单变量分布(例如合理的年龄或血压范围),又恢复变量间的关系(例如体重与体质指数之间的联系)。随后他们使用自动化搜索策略调优模型设置,以在准确性、对后续机器学习任务的有用性和隐私保护这三项目标之间取得平衡。
保持真实性而不泄露隐私
为了评估生成数据是否足够好,框架在多个维度上评估每个模型。统计测试比较真实与合成数据的基本分布和相关性。机器学习测试在合成数据上训练预测模型,并在真实记录上测试,以检验知识迁移效果。与此同时,形式化与经验性的隐私检测评估从合成数据中重新识别出真实个人的可能性。结果显示,TabSyn与CorrDst的组合在表现上持续优于较早的生成方法,尤其是在包含大量缺失值的高维癌症数据集上。它保留了关键的医学模式——例如性别特异性癌症以及吸烟与肺部疾病之间的联系——而不会生成不可信的极端值,并且计算时间处于合理范围内。
让杂乱的医疗数据可用
健康研究的一大障碍是现实世界数据往往杂乱:许多化验结果缺失、测量时间不一致、且某些变量必须遵守严格的生物学规则。作者设计了一个定制的预处理流程,以结构化方式填补缺失值,将偏态数值变量重塑为更稳定的形式,并添加明确标记缺失位置的指示器。这种方法大幅减少了困扰简单方法的伪影,例如年龄、体重与体质指数之间不可能的组合。在生成后,质量控制阶段结合自动检查与专家审查,拒绝违反医学逻辑的合成记录(例如分配给女性的前列腺癌)。 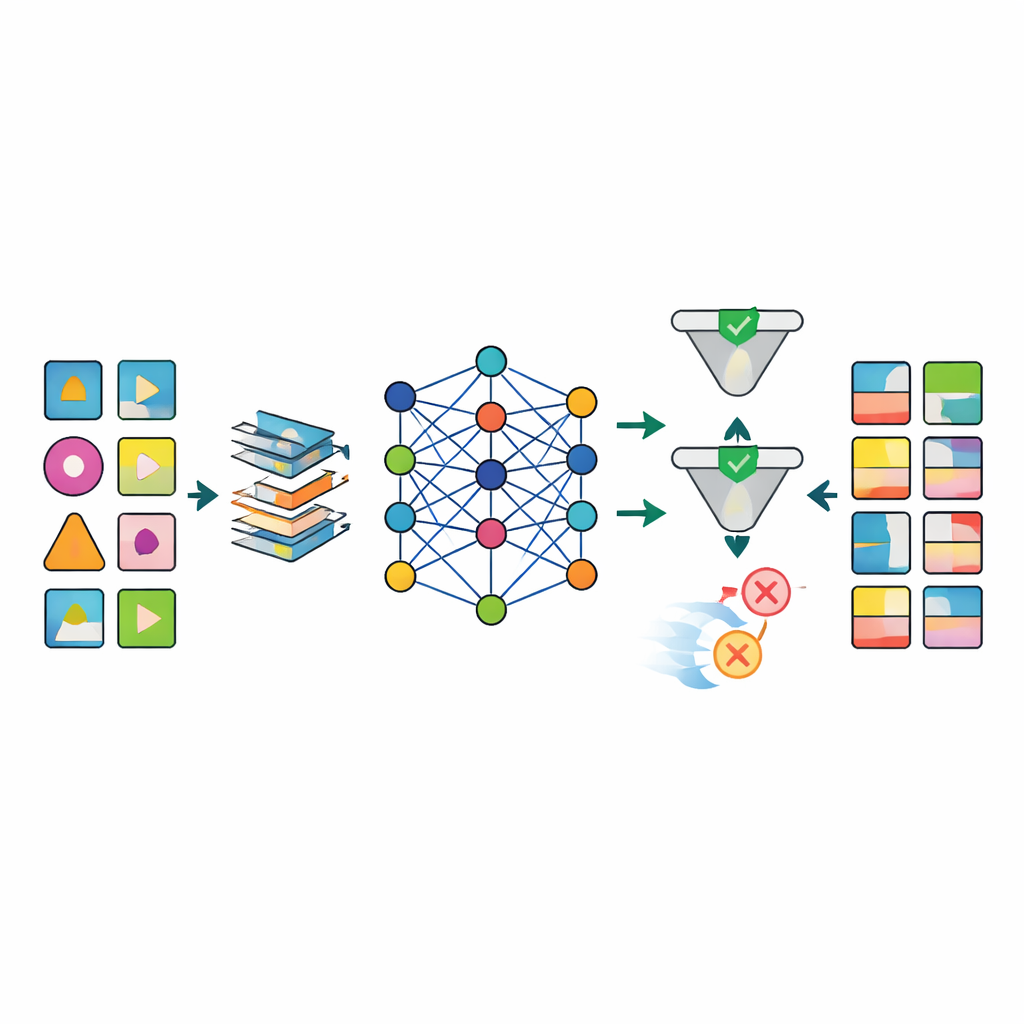
在看数据的同时看不见个人
除了生成之外,团队构建了一个交互式可视化工具,允许研究者在保护隐私的同时探索队列特征——例如分年龄和性别统计同时患有肺癌和肥胖的人数。一个基于k-匿名性的自适应匿名化算法动态地粗化或移除筛选条件,确保任何设置组合都不会泄露少于十个个体的信息。这使得在不暴露任何单个敏感细节的前提下,对丰富的健康数据进行可行性检查和假设生成成为可能。
这对患者与研究者意味着什么
简而言之,文章表明现在可以大规模生成现实且具隐私保护的详细病历替代品。通过结合智能预处理、高性能生成模型、严格的隐私测试与人工质控,该框架提供了在分析中表现如原始数据但更安全分享的合成数据集。如果广泛采用,这类工具可以解锁大量生物样本库资源以促进合作研究、改进样本量有限的罕见病研究,并在不妨碍科学进展的情况下帮助满足法律要求。
引用: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
关键词: 合成健康数据, 患者隐私, 生物样本库研究, 差分隐私, 医疗人工智能