Clear Sky Science · pt
Anonimização e visualização de dados e biomarcadores de saúde
Por que seus prontuários médicos são tão difíceis de compartilhar
A medicina moderna prospera com dados: quanto mais prontuários os pesquisadores podem analisar, melhor conseguem entender doenças e aprimorar tratamentos. Mas regras rígidas de privacidade significam que grande parte dessas informações fica inacessível, especialmente quando vem de registros detalhados de hospitais e biobancos. Este artigo apresenta uma forma prática de criar conjuntos de dados de saúde “falsos” realistas que protegem a privacidade individual, mantendo utilidade para pesquisa e abrindo um caminho mais seguro para o compartilhamento de dados em todo o mundo.
Transformando registros bloqueados em equivalentes seguros
Os pesquisadores construíram um sistema ponta a ponta que recebe registros de saúde sensíveis e os transforma em dados sintéticos — registros que se parecem e se comportam como os reais em termos estatísticos, mas não correspondem a nenhuma pessoa real. A estrutura começa com limpeza e organização cuidadosas de diários hospitalares, questionários, exames laboratoriais e dados de registros de câncer de mais de 50.000 indivíduos do norte da Suécia. Um único arquivo de configuração descreve quais variáveis existem, como devem ser tratadas e quais limites de privacidade se aplicam, de modo que cada etapa seja transparente e reproduzível. O sistema é distribuído como software de código aberto empacotado em um contêiner, facilitando para hospitais e centros de pesquisa a implantação sem lidar com instalações complexas. 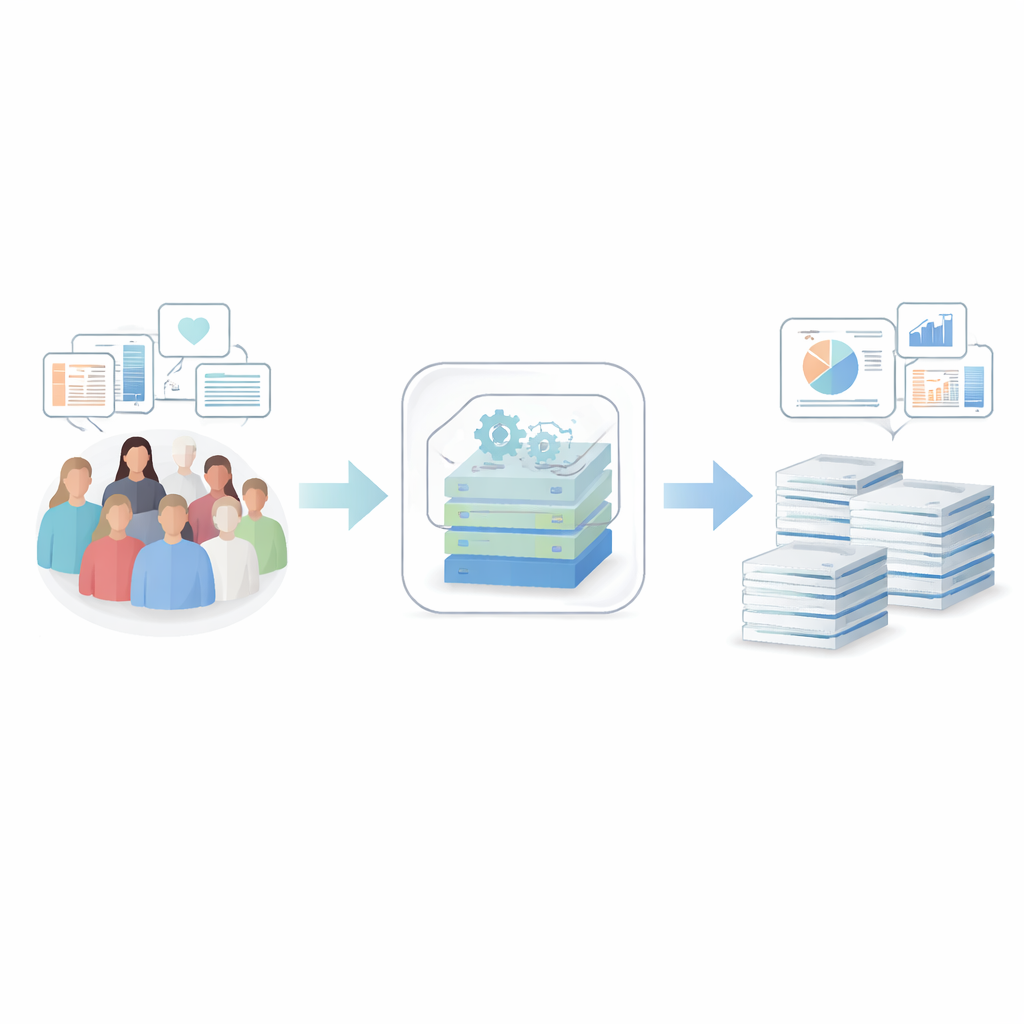
Como funciona a fábrica de dados sintéticos
Uma vez que os dados estão preparados, vários modelos avançados de inteligência artificial, incluindo diferentes tipos de redes generativas profundas, são treinados para imitar os padrões dos conjuntos de dados reais. O modelo de destaque, chamado TabSyn, é um método de difusão baseado em transformers originalmente desenvolvido para tabelas complexas de números e categorias. A equipe o complementa com uma função de perda especial, CorrDst, que recompensa explicitamente o modelo por reproduzir tanto as distribuições individuais (por exemplo, faixas realistas de idade ou pressão arterial) quanto as relações entre variáveis (como a ligação entre peso e índice de massa corporal). Em seguida, usam uma estratégia automatizada de busca para ajustar as configurações do modelo de modo que três objetivos sejam equilibrados ao mesmo tempo: acurácia, utilidade para tarefas de aprendizado de máquina subsequentes e proteção da privacidade.
Preservando o realismo sem comprometer a privacidade
Para avaliar se os dados gerados são bons o suficiente, a estrutura avalia cada modelo em múltiplos eixos. Testes estatísticos comparam distribuições básicas e correlações entre os conjuntos de dados reais e sintéticos. Testes de aprendizado de máquina treinam modelos de predição em dados sintéticos e os testam nos registros reais para ver quão bem o conhecimento se transfere. Ao mesmo tempo, verificações de privacidade formais e empíricas estimam qual a probabilidade de uma pessoa real ser reidentificada a partir dos dados sintéticos. Os resultados mostram que o TabSyn combinado com CorrDst supera consistentemente abordagens gerativas antigas, especialmente em conjuntos de dados oncológicos de alta dimensionalidade com muitos valores faltantes. Ele preserva padrões médicos chave — como cânceres específicos por sexo e ligações entre tabagismo e doenças pulmonares — sem produzir extremos implausíveis, e faz isso com tempos de computação razoáveis.
Tornando dados médicos bagunçados utilizáveis
Um grande obstáculo na pesquisa em saúde é que os dados do mundo real são bagunçados: muitos resultados laboratoriais estão ausentes, os horários de medição variam e algumas variáveis devem obedecer a regras biológicas estritas. Os autores projetaram um pipeline de pré‑processamento sob medida que imputa valores ausentes de forma estruturada, remodela variáveis numéricas assimétricas para formas mais estáveis e adiciona indicadores que marcam explicitamente onde os dados estavam faltando. Essa abordagem reduz fortemente artefatos que afligem métodos mais simples, como combinações impossíveis de idade, peso e índice de massa corporal. Após a geração, uma etapa de controle de qualidade usa tanto checagens automatizadas quanto inspeção por especialistas para rejeitar registros sintéticos que violem a lógica médica (por exemplo, câncer de próstata atribuído a mulheres). 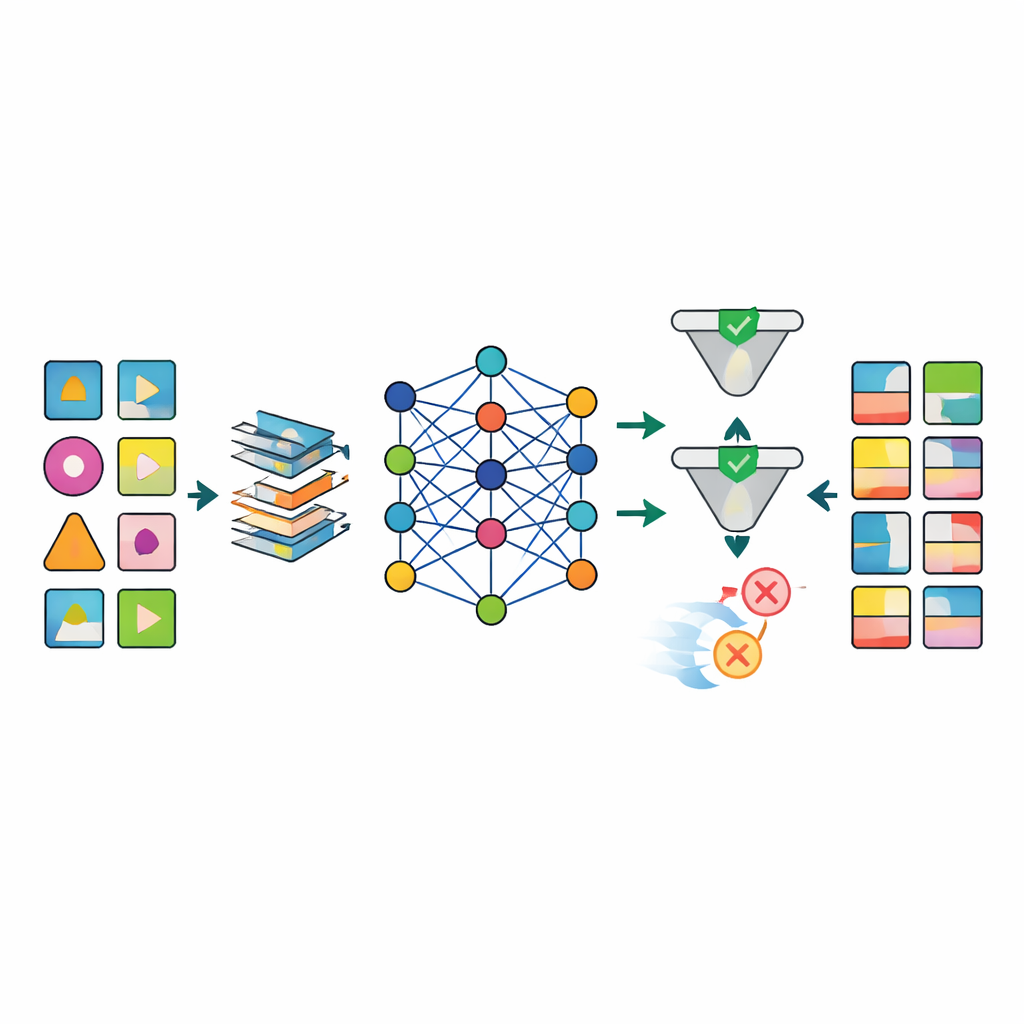
Ver os dados sem ver as pessoas
Além da geração, a equipe construiu uma ferramenta interativa de visualização que permite aos pesquisadores explorar características de coorte — como quantas pessoas têm simultaneamente câncer de pulmão e obesidade, estratificadas por idade e sexo — enquanto impede vazamentos de privacidade. Um algoritmo de anonimização adaptativa baseado em k‑anonimato torna dinamicamente mais grosseiros ou remove filtros para que nenhuma combinação de configurações revele menos do que dez indivíduos. Isso possibilita checagens de viabilidade e geração de hipóteses em dados de saúde ricos sem expor detalhes sensíveis sobre qualquer pessoa.
O que isso significa para pacientes e pesquisadores
Em termos simples, o artigo mostra que agora é possível produzir em massa substitutos realistas e que preservam a privacidade para prontuários de saúde detalhados. Combinando pré‑processamento inteligente, um modelo gerativo de alto desempenho, testes rigorosos de privacidade e controle de qualidade humano, a estrutura entrega conjuntos de dados sintéticos que se comportam como os originais em análises, mas são muito mais seguros para compartilhar. Se amplamente adotadas, tais ferramentas poderiam desbloquear vastos recursos de biobancos para pesquisa colaborativa, melhorar estudos sobre doenças raras com números limitados de pacientes e ajudar a cumprir exigências legais sem sacrificar o progresso científico.
Citação: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
Palavras-chave: dados de saúde sintéticos, privacidade do paciente, pesquisa com biobancos, privacidade diferencial, IA médica