Clear Sky Science · pl
Anonimizacja i wizualizacja danych zdrowotnych i biomarkerów
Dlaczego Twoje dokumenty medyczne są tak trudne do udostępnienia
Współczesna medycyna opiera się na danych: im więcej kart pacjentów badacze mogą przeanalizować, tym lepiej rozumieją choroby i poprawiają leczenie. Surowe przepisy dotyczące prywatności oznaczają jednak, że wiele z tych informacji jest zablokowanych, zwłaszcza jeśli pochodzą z szczegółowych rejestrów szpitalnych i biobanków. Artykuł przedstawia praktyczny sposób tworzenia realistycznych „fałszywych” zbiorów danych zdrowotnych, które chronią prywatność jednostek, a jednocześnie pozostają użyteczne do badań, potencjalnie otwierając bezpieczniejszą drogę do udostępniania danych na całym świecie.
Przekształcanie zablokowanych zapisów w bezpieczne podobieństwa
Badacze zbudowali system typu end‑to‑end, który przetwarza wrażliwe zapisy zdrowotne na dane syntetyczne — rekordy, które statystycznie wyglądają i zachowują się jak prawdziwe, ale nie odpowiadają żadnej rzeczywistej osobie. Ich ramy zaczynają się od starannego oczyszczenia i uporządkowania dzienników szpitalnych, kwestionariuszy, badań laboratoryjnych oraz danych z rejestru nowotworów pochodzących od ponad 50 000 osób z północnej Szwecji. Pojedynczy plik konfiguracyjny opisuje, jakie zmienne istnieją, jak należy je traktować i jakie limity prywatności obowiązują, dzięki czemu każdy etap jest przejrzysty i powtarzalny. System jest dostarczany jako oprogramowanie open‑source spakowane w kontener, co ułatwia wdrożenie w szpitalach i ośrodkach badawczych bez konieczności zmagania się ze skomplikowanymi instalacjami. 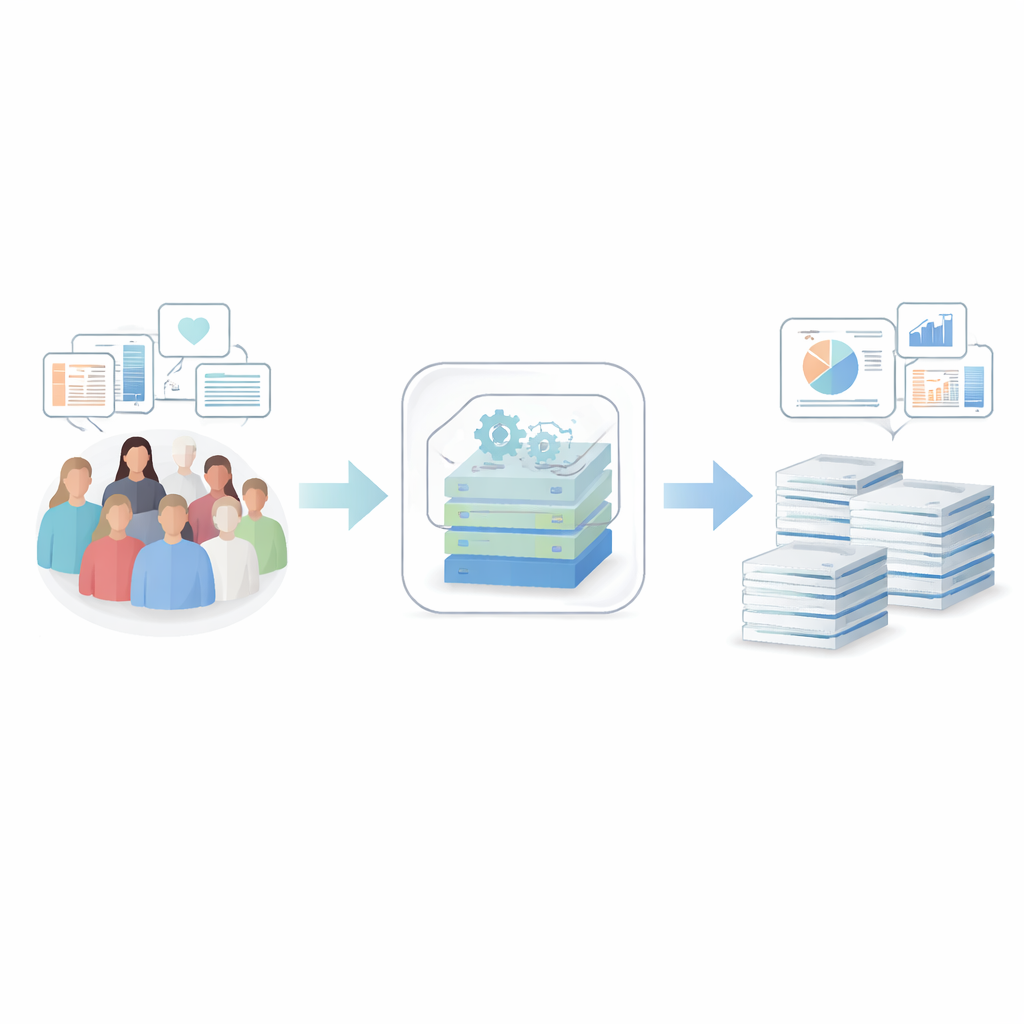
Jak działa fabryka danych syntetycznych
Gdy dane są przygotowane, kilka zaawansowanych modeli sztucznej inteligencji, w tym różne typy głębokich sieci generatywnych, jest trenowanych do naśladowania wzorców w rzeczywistych zestawach danych. Wyróżniającym się modelem jest TabSyn — metoda dyfuzji oparta na transformatorach, pierwotnie opracowana do złożonych tabel liczb i kategorii. Zespół uzupełnia ją o specjalną funkcję straty, CorrDst, która wyraźnie nagradza model za poprawne odwzorowanie zarówno rozkładów poszczególnych zmiennych (na przykład realistycznych zakresów wieku czy ciśnienia krwi), jak i zależności między zmiennymi (takich jak związek między wagą a wskaźnikiem masy ciała). Następnie korzystają z zautomatyzowanej strategii przeszukiwania, aby dostroić ustawienia modeli tak, by jednocześnie zrównoważyć trzy cele: dokładność, użyteczność do zadań uczenia maszynowego i ochronę prywatności.
Utrzymanie realizmu bez naruszania prywatności
Aby ocenić, czy wygenerowane dane są wystarczająco dobre, system testuje każdy model w wielu wymiarach. Testy statystyczne porównują podstawowe rozkłady i korelacje między rzeczywistymi a syntetycznymi zbiorami. Testy uczenia maszynowego trenują modele predykcyjne na danych syntetycznych i sprawdzają je na prawdziwych zapisach, by zobaczyć, jak dobrze wiedza się przenosi. Równocześnie formalne i empiryczne kontrole prywatności szacują, jak prawdopodobne jest, że rzeczywista osoba mogłaby zostać ponownie zidentyfikowana na podstawie danych syntetycznych. Wyniki pokazują, że TabSyn połączony z CorrDst konsekwentnie przewyższa starsze podejścia generatywne, zwłaszcza w przypadku wysokowymiarowych zestawów onkologicznych z wieloma brakującymi wartościami. Zachowuje kluczowe wzorce medyczne — takie jak nowotwory specyficzne dla płci czy związki między paleniem a chorobami płuc — bez generowania nieprawdopodobnych ekstremów, i robi to w rozsądnym czasie obliczeniowym.
Uczynienie nieuporządkowanych danych medycznych użytecznymi
Główną przeszkodą w badaniach zdrowotnych jest to, że dane ze świata rzeczywistego są chaotyczne: wiele wyników laboratoryjnych jest brakujących, czasy pomiarów się różnią, a niektóre zmienne muszą spełniać ścisłe reguły biologiczne. Autorzy opracowali dopasowany pipeline przetwarzania wstępnego, który strukturalnie imputuje brakujące wartości, przekształca skośne zmienne numeryczne w bardziej stabilne formy i dodaje wskaźniki, które wyraźnie oznaczają, gdzie dane były brakujące. Podejście to znacząco redukuje artefakty nękające prostsze metody, takie jak niemożliwe kombinacje wieku, wagi i wskaźnika masy ciała. Po generacji etap kontroli jakości wykorzystuje zarówno automatyczne sprawdzenia, jak i inspekcję ekspercką, aby odrzucać syntetyczne rekordy naruszające logikę medyczną (na przykład przypisanie raka prostaty kobietom). 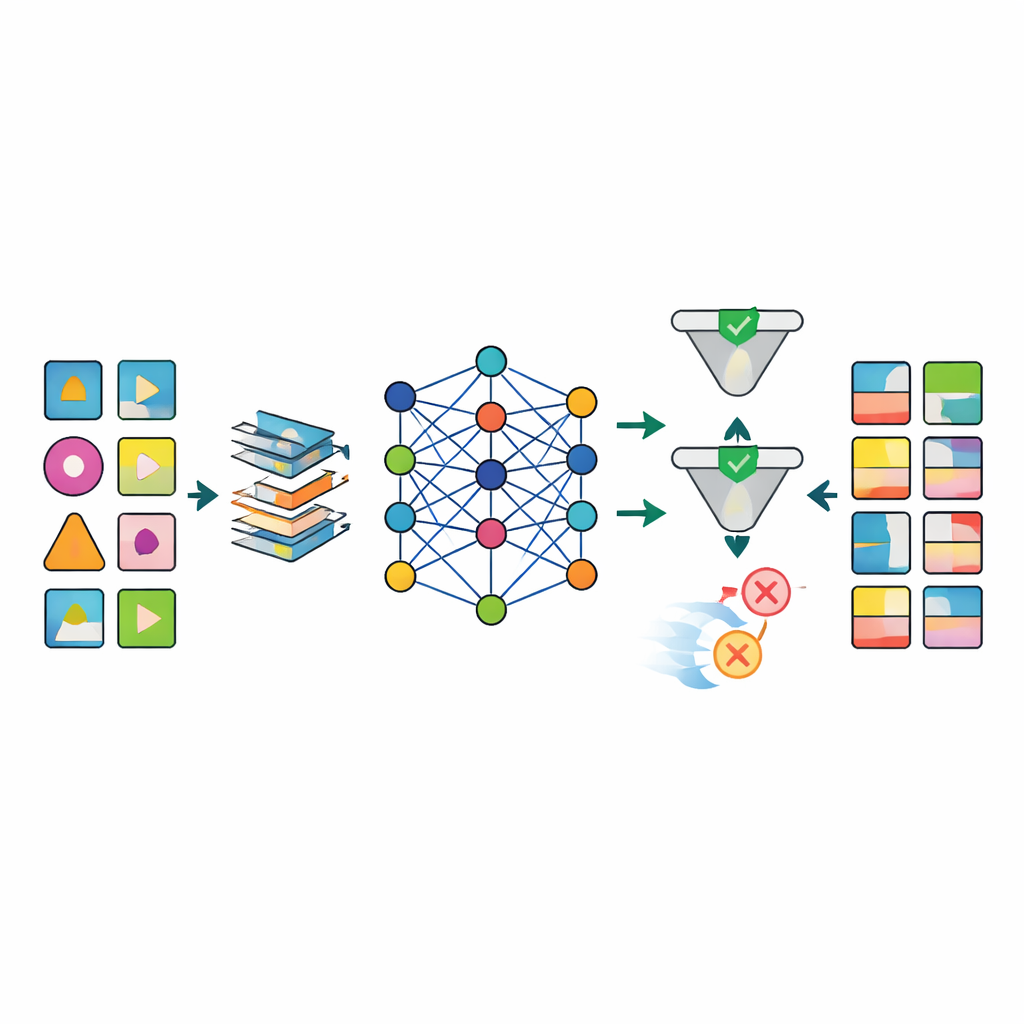
Widzieć dane, nie widząc ludzi
Ponad samą generacją zespół stworzył interaktywne narzędzie wizualizacyjne, które pozwala badaczom badać cechy kohort — na przykład, ile osób ma jednocześnie raka płuc i otyłość, rozbitych według wieku i płci — przy jednoczesnej ochronie przed wyciekami prywatności. Adaptacyjny algorytm anonimizacji oparty na k‑anonimowości dynamicznie zgrubnia lub usuwa filtry tak, aby żadna kombinacja ustawień nie ujawniała mniej niż dziesięciu osób. Umożliwia to sprawdzenie wykonalności i generowanie hipotez na bogatych danych zdrowotnych bez ujawniania wrażliwych szczegółów dotyczących konkretnej osoby.
Co to oznacza dla pacjentów i badaczy
Mówiąc prosto, artykuł pokazuje, że obecnie możliwe jest masowe wytwarzanie realistycznych, chroniących prywatność substytutów szczegółowych zapisów zdrowotnych. Poprzez połączenie inteligentnego przetwarzania wstępnego, wysoko wydajnego modelu generatywnego, rygorystycznych testów prywatności i kontroli jakości wykonywanej przez ludzi, ramy dostarczają syntetyczne zbiory danych, które w analizach zachowują się jak oryginały, a jednocześnie są znacznie bezpieczniejsze do udostępniania. Jeśli zostaną szeroko przyjęte, takie narzędzia mogłyby odblokować ogromne zasoby biobanków dla badań współpracujących, poprawić badania nad rzadkimi chorobami z ograniczoną liczbą pacjentów i pomóc spełnić wymogi prawne bez poświęcania postępu naukowego.
Cytowanie: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
Słowa kluczowe: syntetyczne dane zdrowotne, prywatność pacjenta, badania biobankowe, różnicowa prywatność, medyczna AI