Clear Sky Science · en
Anonymization and visualization of health data and biomarkers
Why Your Medical Records Are So Hard to Share
Modern medicine thrives on data: the more patient records researchers can analyze, the better they can understand disease and improve treatments. But strict privacy rules mean that much of this information is locked away, especially when it comes from detailed hospital and biobank records. This article introduces a practical way to create realistic “fake” health datasets that protect individual privacy while remaining useful for research, potentially opening up a safer path to data sharing worldwide.
Turning Locked Records into Safe Look‑Alikes
The researchers built an end‑to‑end system that takes sensitive health records and turns them into synthetic data—records that look and behave like the real thing statistically, but do not correspond to any actual person. Their framework starts with careful cleaning and organizing of hospital journals, questionnaires, lab tests, and cancer registry data from over 50,000 individuals in northern Sweden. A single configuration file describes what variables exist, how they should be handled, and what privacy limits apply, so that every step is transparent and repeatable. The system is distributed as open‑source software packed into a container, making it easier for hospitals and research centers to deploy without wrestling with complex installations. 
How the Synthetic Data Factory Works
Once the data are prepared, several advanced artificial‑intelligence models, including different types of deep generative networks, are trained to imitate the patterns in the real datasets. The standout model, called TabSyn, is a transformer‑based diffusion method originally developed for complex tables of numbers and categories. The team augments it with a special loss function, CorrDst, that explicitly rewards the model for getting both the individual distributions (for example, realistic age or blood‑pressure ranges) and the relationships between variables (such as the link between weight and body‑mass index) right. They then use an automated search strategy to tune model settings so that three goals are balanced at once: accuracy, usefulness for downstream machine‑learning tasks, and privacy protection.
Keeping Realism Without Breaking Privacy
To judge whether the generated data are good enough, the framework evaluates each model along multiple axes. Statistical tests compare basic distributions and correlations between real and synthetic datasets. Machine‑learning tests train prediction models on synthetic data and test them on the real records to see how well knowledge transfers. At the same time, formal and empirical privacy checks estimate how likely it is that a real person could be re‑identified from the synthetic data. The results show that TabSyn combined with CorrDst consistently outperforms older generative approaches, especially on high‑dimensional cancer datasets with many missing values. It preserves key medical patterns—like sex‑specific cancers and links between smoking and lung disease—without producing implausible extremes, and it does so with reasonable computation times.
Making Messy Medical Data Usable
A major obstacle in health research is that real‑world data are messy: many lab results are missing, measurement times vary, and some variables must obey strict biological rules. The authors design a tailored preprocessing pipeline that imputes missing values in a structured way, reshapes skewed numerical variables into more stable forms, and adds indicators that explicitly mark where data were missing. This approach sharply reduces artifacts that plague simpler methods, such as impossible combinations of age, weight, and body‑mass index. After generation, a quality‑control stage uses both automated checks and expert inspection to reject synthetic records that violate medical logic (for example, prostate cancer assigned to women). 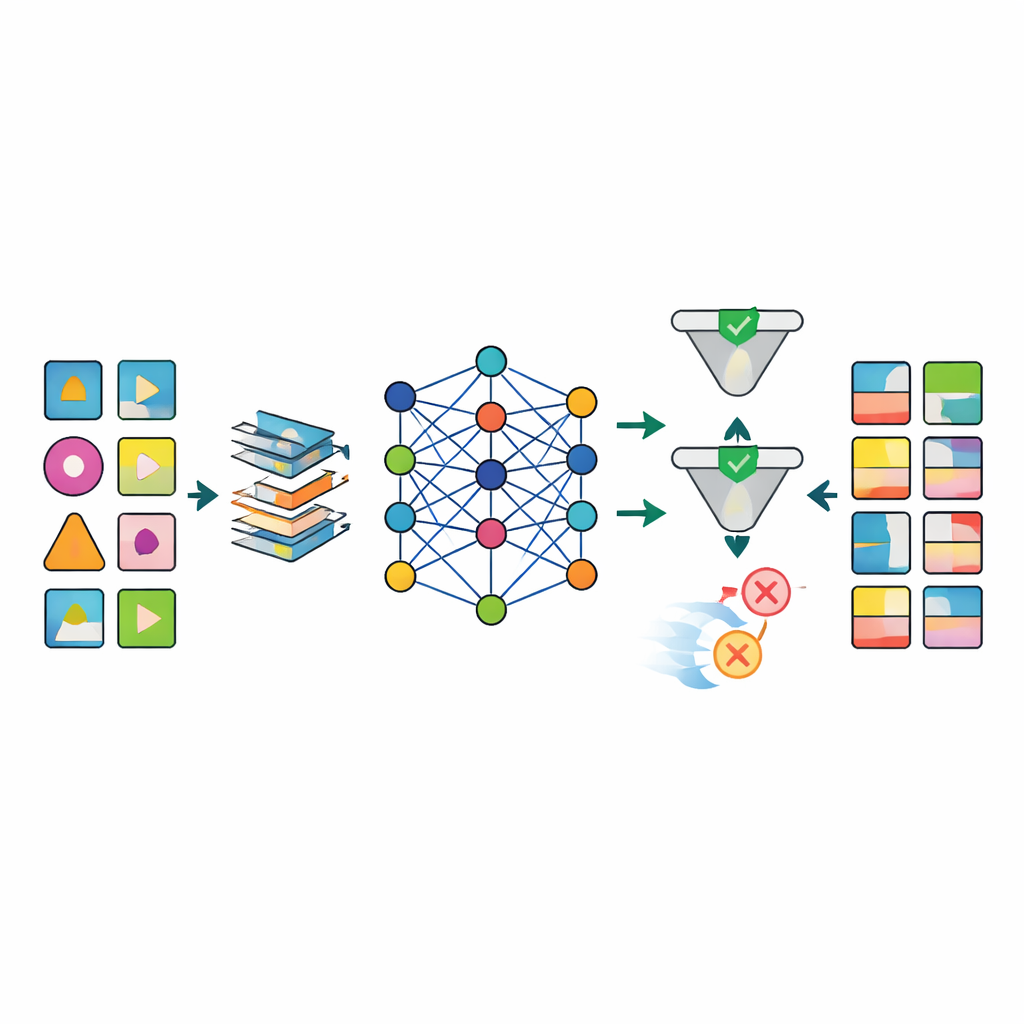
Seeing the Data Without Seeing the People
Beyond generation, the team builds an interactive visualization tool that lets researchers explore cohort characteristics—such as how many people have both lung cancer and obesity, broken down by age and sex—while guarding against privacy leaks. An adaptive anonymization algorithm based on k‑anonymity dynamically coarsens or removes filters so that no combination of settings ever reveals fewer than ten individuals. This enables feasibility checks and hypothesis generation on rich health data without exposing sensitive details about any one person.
What This Means for Patients and Researchers
In plain terms, the article shows that it is now possible to mass‑produce realistic, privacy‑preserving stand‑ins for detailed health records. By combining smart preprocessing, a high‑performing generative model, rigorous privacy testing, and human quality control, the framework delivers synthetic datasets that behave like the originals in analyses but are far safer to share. If adopted widely, such tools could unlock vast biobank resources for collaborative research, improve studies on rare diseases with limited patient numbers, and help meet legal requirements without sacrificing scientific progress.
Citation: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
Keywords: synthetic health data, patient privacy, biobank research, differential privacy, medical AI