Clear Sky Science · es
Anonimización y visualización de datos sanitarios y biomarcadores
Por qué es tan difícil compartir tus historiales médicos
La medicina moderna prospera gracias a los datos: cuantos más expedientes de pacientes puedan analizar los investigadores, mejor comprenderán las enfermedades y mejorarán los tratamientos. Pero las normas estrictas de privacidad hacen que gran parte de esta información permanezca cerrada, sobre todo cuando proviene de registros hospitalarios y biobancos detallados. Este artículo presenta una forma práctica de crear conjuntos de datos sanitarios “falsos” realistas que protegen la privacidad individual y, al mismo tiempo, siguen siendo útiles para la investigación, abriendo potencialmente una vía más segura para compartir datos a escala mundial.
Convertir registros bloqueados en parecidos seguros
Los investigadores construyeron un sistema de extremo a extremo que toma registros sanitarios sensibles y los transforma en datos sintéticos: registros que se parecen y se comportan como los reales desde un punto de vista estadístico, pero que no corresponden a ninguna persona real. Su marco comienza con una limpieza y organización cuidadosas de diarios hospitalarios, cuestionarios, pruebas de laboratorio y datos de registros de cáncer de más de 50.000 individuos del norte de Suecia. Un único archivo de configuración describe qué variables existen, cómo deben tratarse y qué límites de privacidad se aplican, de modo que cada paso sea transparente y repetible. El sistema se distribuye como software de código abierto empaquetado en un contenedor, lo que facilita su despliegue en hospitales y centros de investigación sin lidiar con instalaciones complejas. 
Cómo funciona la fábrica de datos sintéticos
Una vez preparados los datos, varios modelos avanzados de inteligencia artificial, incluidos distintos tipos de redes generativas profundas, se entrenan para imitar los patrones de los conjuntos de datos reales. El modelo destacado, llamado TabSyn, es un método de difusión basado en transformadores desarrollado originalmente para tablas complejas de números y categorías. El equipo lo complementa con una función de pérdida especial, CorrDst, que recompensa explícitamente al modelo por acertar tanto las distribuciones individuales (por ejemplo, rangos realistas de edad o presión arterial) como las relaciones entre variables (como la relación entre el peso y el índice de masa corporal). Luego usan una estrategia de búsqueda automatizada para ajustar los parámetros del modelo de modo que se equilibren tres objetivos a la vez: precisión, utilidad para tareas de aprendizaje automático posteriores y protección de la privacidad.
Mantener el realismo sin romper la privacidad
Para juzgar si los datos generados son suficientemente buenos, el marco evalúa cada modelo a lo largo de múltiples ejes. Pruebas estadísticas comparan distribuciones básicas y correlaciones entre los conjuntos reales y sintéticos. Pruebas de aprendizaje automático entrenan modelos de predicción con datos sintéticos y los evalúan sobre los registros reales para ver qué tan bien se transfiere el conocimiento. Al mismo tiempo, comprobaciones formales y empíricas de privacidad estiman la probabilidad de que una persona real pueda ser reidentificada a partir de los datos sintéticos. Los resultados muestran que TabSyn combinado con CorrDst supera de forma consistente a enfoques generativos anteriores, especialmente en conjuntos de datos oncológicos de alta dimensión con muchos valores faltantes. Conserva patrones médicos clave —como cánceres específicos por sexo y vínculos entre el tabaquismo y las enfermedades pulmonares— sin generar extremos implausibles, y lo hace con tiempos de cálculo razonables.
Hacer utilizables los datos médicos desordenados
Un obstáculo importante en la investigación sanitaria es que los datos del mundo real son desordenados: faltan muchos resultados de laboratorio, los tiempos de medición varían y algunas variables deben obedecer reglas biológicas estrictas. Los autores diseñan una canalización de preprocesamiento a medida que imputa valores faltantes de forma estructurada, transforma variables numéricas sesgadas hacia formas más estables y añade indicadores que marcan explícitamente dónde faltaban datos. Este enfoque reduce drásticamente los artefactos que afectan a métodos más sencillos, como combinaciones imposibles de edad, peso e índice de masa corporal. Tras la generación, una etapa de control de calidad utiliza tanto comprobaciones automatizadas como la inspección de expertos para rechazar registros sintéticos que violen la lógica médica (por ejemplo, asignar cáncer de próstata a mujeres). 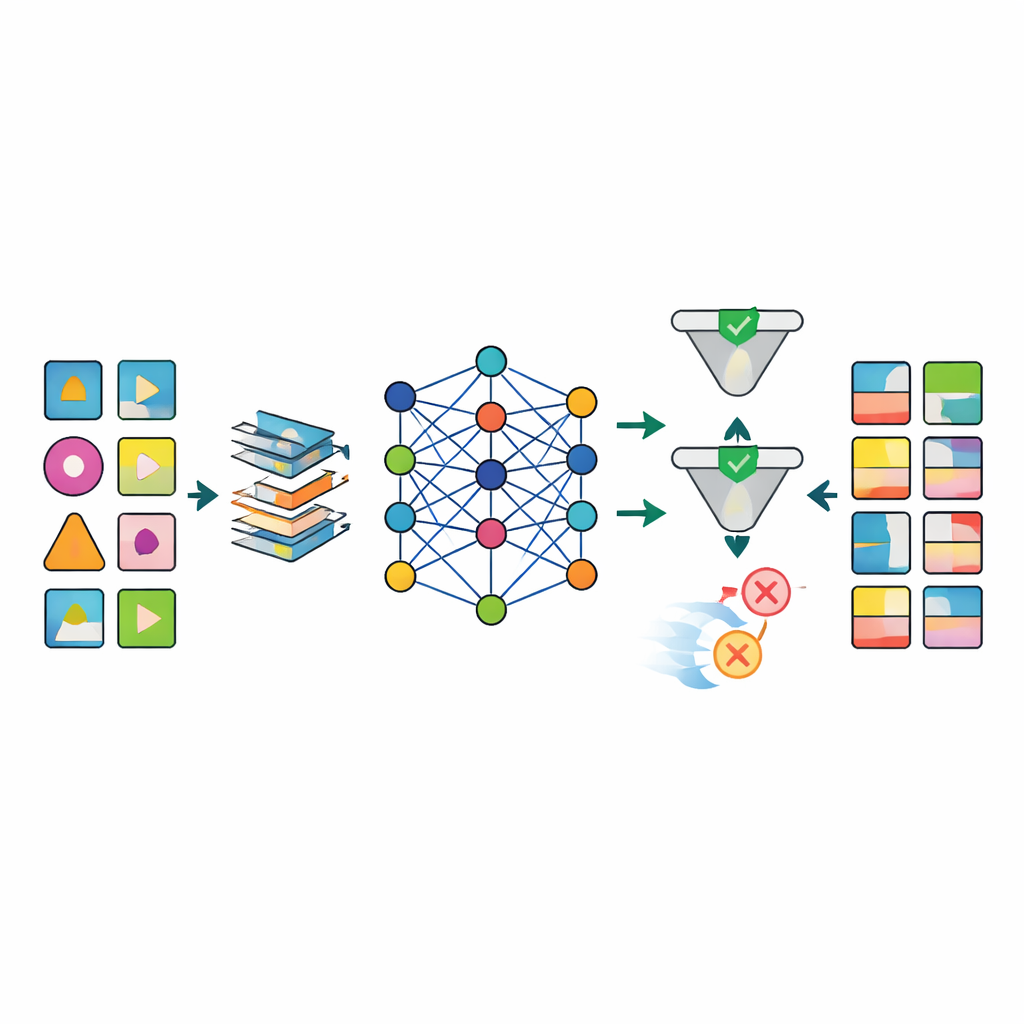
Ver los datos sin ver a las personas
Más allá de la generación, el equipo desarrolla una herramienta de visualización interactiva que permite a los investigadores explorar las características de la cohorte —como cuántas personas tienen simultáneamente cáncer de pulmón y obesidad, desglosadas por edad y sexo— a la vez que protege contra fugas de privacidad. Un algoritmo de anonimización adaptativa basado en k‑anonymity agrupa o elimina filtros dinámicamente para que ninguna combinación de ajustes revele nunca a menos de diez individuos. Esto permite realizar comprobaciones de viabilidad y generar hipótesis sobre datos sanitarios ricos sin exponer detalles sensibles de ninguna persona.
Qué significa esto para pacientes e investigadores
En términos sencillos, el artículo muestra que ahora es posible producir en masa sustitutos realistas y preservadores de la privacidad para registros sanitarios detallados. Al combinar un preprocesamiento inteligente, un modelo generativo de alto rendimiento, pruebas rigurosas de privacidad y control de calidad humano, el marco ofrece conjuntos de datos sintéticos que se comportan como los originales en los análisis pero son mucho más seguros de compartir. Si se adoptan ampliamente, estas herramientas podrían desbloquear vastos recursos de biobancos para la investigación colaborativa, mejorar los estudios sobre enfermedades raras con pocos pacientes y ayudar a cumplir requisitos legales sin sacrificar el progreso científico.
Cita: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
Palabras clave: datos sanitarios sintéticos, privacidad del paciente, investigación en biobancos, privacidad diferencial, IA médica