Clear Sky Science · he
אנונימיזציה והמחשה של נתוני בריאות וביומרגשים
מדוע קשה כל כך לשתף את התיקים הרפואיים שלכם
הרפואה המודרנית נשענת על נתונים: ככל שיהיו לחוקרים יותר רשומות מטופלים לנתח, הם יוכלו להבין מחלות ולשפר טיפולים ביתר דיוק. אך כללי פרטיות מחמירים משאירים חלק גדול מהמידע נעול, במיוחד כשמדובר ברשומות בית חולים וביובנקים מפורטים. מאמר זה מציג דרך מעשית ליצירת מערכי נתונים רפואיים "מזויפים" וראליסטיים שמגנים על פרטיות היחידים ועדיין שימושיים למחקר — ובכך פוטנציאלית פותחים נתיב בטוח יותר לשיתוף נתונים ברחבי העולם.
הפיכת רשומות נעולות לחיקויים בטוחים
החוקרים בנו מערכת מקצה אל קצה שלוקחת רשומות בריאות רגישות והופכת אותן לנתונים סינתטיים — רשומות שנראות ומתנהגות סטטיסטית כמו הנתונים האמיתיים, אך אינן מתאימות לאף אדם אמיתי. המסגרת שלהם מתחילה בניקוי וסידור קפדני של יומני בית חולים, שאלונים, בדיקות מעבדה ונתוני רישום סרטן מיותר מ‑50,000 אנשים מצפון שבדיה. קובץ תצורה יחיד מתאר אילו משתנים קיימים, כיצד יש לטפל בהם ואילו גבולות פרטיות חלים, כך שכל שלב הוא שקוף וחוזר על עצמו. המערכת מופצת כתוכנה קוד‑פתוח באריזה מנותבת (container), מה שמקל על בתי חולים ומרכזי מחקר לפרוס אותה ללא מאבק בהתקנות מורכבות. 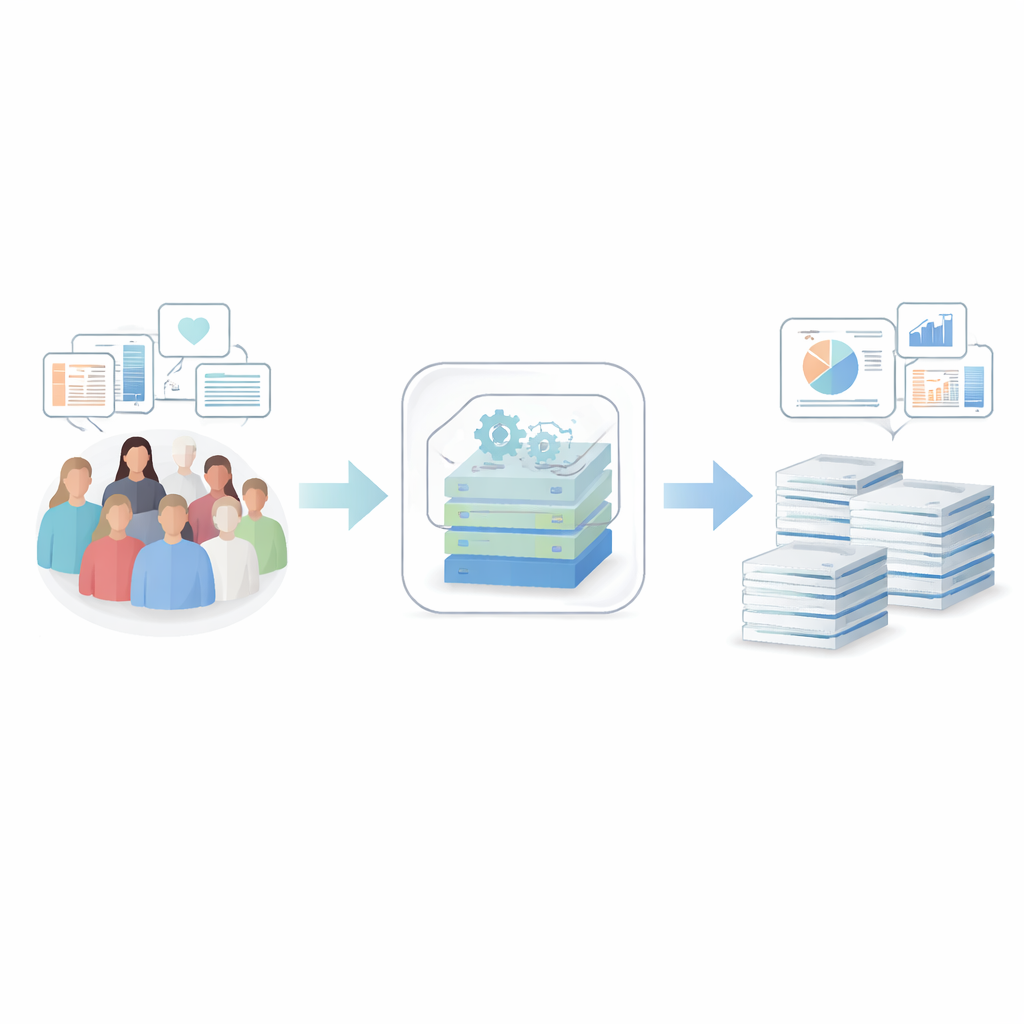
איך מפעל הנתונים הסינתטיים עובד
לאחר הכנת הנתונים, מאומנים מספר מודלים מתקדמים של בינה מלאכותית, כולל סוגים שונים של רשתות גנרטיביות עמוקות, לחקות את הדפוסים במערכי הנתונים האמיתיים. המודל הבולט, שנקרא TabSyn, הוא שיטה מבוססת טרנספורמר ודיפוזיה שתוכננה במקור לטבלאות מורכבות של מספרים וקטגוריות. הצוות מעשיר אותו עם פונקציית אובדן מיוחדת, CorrDst, שמתגמלת במפורש את המודל על כך שהוא משחזר גם את ההתפלגויות של ערכים בודדים (למשל טווחי גיל או לחץ דם מציאותיים) וגם את הקשרים בין משתנים (כמו הקשר בין משקל ומדד מסת גוף). אחר כך הם משתמשים באסטרטגיית חיפוש אוטומטית לכיוון פרמטרי המודל כך שכל שלוש המטרות יתאזנו בו־זמנית: דיוק, שימושיות למשימות למידת מכונה מעקביות והגנה על פרטיות.
שמירה על ריאליזם בלי לפגוע בפרטיות
כדי לשפוט האם הנתונים המיוצרים מספיקים, המסגרת מעריכה כל מודל לאורך כמה מערכים. בדיקות סטטיסטיות משוות התפלגויות בסיסיות וקורלציות בין מערכי הנתונים האמיתיים לסינתטיים. בדיקות למידת מכונה מאמנות מודלים חזויים על נתונים סינתטיים ובודקות אותם על הרשומות האמיתיות כדי לראות עד כמה הידע עובר. במקביל, בדיקות פרטיות פורמליות ואמפיריות מעריכות מה הסיכוי שאדם אמיתי יאותר מתוך הנתונים הסינתטיים. התוצאות מראות ש‑TabSyn בשילוב עם CorrDst מתעלה בעקביות על גישות גנרטיביות ישנות יותר, במיוחד במערכי נתונים אונקולוגיים בעלי ממדים גבוהים וריבוי ערכים חסרים. הוא שומר על דפוסים רפואיים מרכזיים — כמו סוגי סרטן המאפיינים מין מסוים וקישורים בין עישון למחלות ריאה — מבלי לייצר קיצונים בלתי סבירים, ועל כך בזמני חישוב סבירים.
הפיכת נתוני רפואה מבולגנים לשימושיים
מכשול מרכזי במחקר בריאות הוא שנתוני העולם האמיתי מבולגנים: תוצאות מעבדה רבות חסרות, זמני מדידה משתנים, וחלק מהמשתנים חייבים לציית לחוקים ביולוגיים נוקשים. המחברים תכננו צינור עיבוד מוקדם מותאם שממלא ערכים חסרים באופן מובנה, מעצב מחדש משתנים מספריים מוטים לצורות יציבות יותר, ומוסיף אינדיקטורים המסמנים במפורש היכן הנתונים היו חסרים. גישה זו מצמצמת באופן חד ארטיפקטים שמטרידים שיטות פשוטות יותר, כגון קומבינציות בלתי אפשריות של גיל, משקל ומדד מסת גוף. לאחר ההפקה, שלב בקרת איכות משתמש בבדיקות אוטומטיות ובבדיקה מומחית כדי לדחות רשומות סינתטיות המפרות לוגיקה רפואית (למשל, שיוך סרטן הערמונית לנשים). 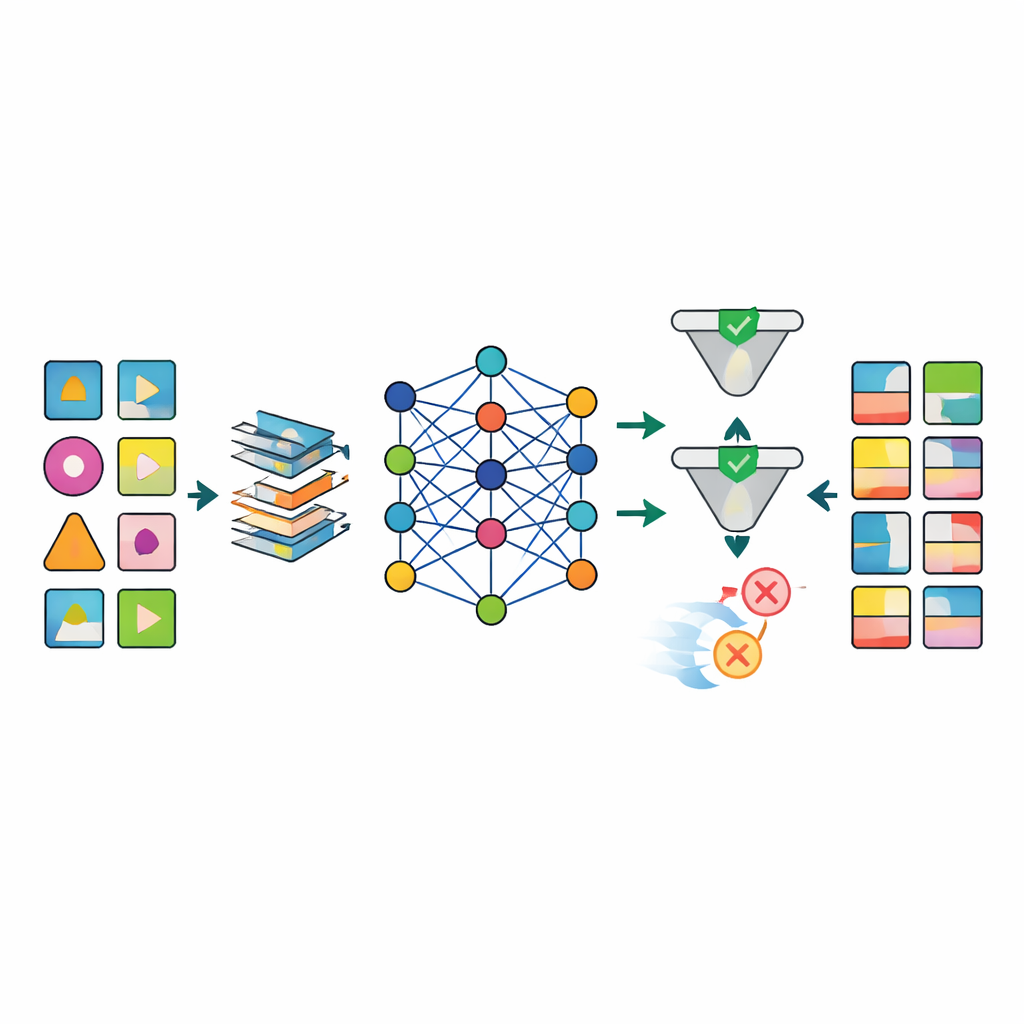
לראות את הנתונים בלי לראות את האנשים
מעבר להפקה, הצוות בונה כלי ויזואליזציה אינטראקטיבי שמאפשר לחוקרים לחקור מאפייני Kohort — כגון כמה אנשים סובלים גם מסרטן ריאה וגם מהשמנת יתר, מפולח לפי גיל ומין — תוך שמירה מפני דליפות פרטיות. אלגוריתם אנונימיזציה אדפטיבי המבוסס על k‑אנונימיות מעבה או מסיר באופן דינמי פילטרים כך שאף שילוב של הגדרות לא יחשוף פחות מעשר פרטים. זה מאפשר בדיקות הישימות וגיבוש השערות על נתוני בריאות עשירים ללא חשיפת פרטים רגישים של אדם בודד.
מה זה אומר למטופלים ולחוקרים
במילים פשוטות, המאמר מראה שאפשר כיום לייצר בהמוניו תחליפים ריאליסטיים ששומרים על פרטיות עבור רשומות בריאות מפורטות. על‑ידי שילוב של עיבוד מוקדם חכם, מודל גנרטיבי בעל ביצועים גבוהים, בדיקות פרטיות קפדניות ובקרת איכות אנושית, המסגרת מספקת מערכי נתונים סינתטיים שמתנהגים כמו המקור בניתוחים אך בטוחים הרבה יותר לשיתוף. אם יאמץ הדבר באופן נרחב, כלים כאלה יכולים לפתוח מקורות ביובנק עצומים לשיתוף פעולה מחקרי, לשפר מחקרים על מחלות נדירות עם מספרי מטופלים מוגבלים, ולעזור לעמוד בדרישות החוקיות מבלי לקרוע את ההתקדמות המדעית.
ציטוט: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
מילות מפתח: נתוני בריאות סינתטיים, פרטיות המטופל, מחקר ביובנק, פרטיות דיפרנציאלית, בינה רפואית