Clear Sky Science · tr
Sağlık verilerinin ve biyobelirteçlerin anonimleştirilmesi ve görselleştirilmesi
Tıbbi Kayıtlarınızın Neden Paylaşılması Bu Kadar Zor?
Modern tıp veriye dayanır: araştırmacıların inceleyebileceği hasta kayıtları ne kadar fazlaysa, hastalıkları anlamaları ve tedavileri geliştirmeleri o kadar kolay olur. Ancak sıkı gizlilik kuralları birçok bilginin, özellikle ayrıntılı hastane ve biyobank kayıtlarının, erişime kapalı kalmasına yol açar. Bu makale, bireysel gizliliği korurken araştırma için yararlı kalabilen gerçekçi “sahte” sağlık veri kümeleri oluşturmanın pratik bir yolunu tanıtıyor; böylece veri paylaşımı için daha güvenli bir yol açılabilir.
Kilitli Kayıtları Güvenli Benzerlerine Dönüştürmek
Araştırmacılar, hassas sağlık kayıtlarını sentetik verilere dönüştüren uçtan uca bir sistem geliştirdiler—istatistiksel olarak gerçek veriye benzeyen ve benzer davranan ama hiçbir gerçek kişiye karşılık gelmeyen kayıtlar. Çerçeve, kuzey İsveç’te 50.000’den fazla kişinin hastane günlükleri, anketler, laboratuvar testleri ve kanser kayıtlarından elde edilen verilerin dikkatli temizlenmesi ve düzenlenmesiyle başlıyor. Tek bir yapılandırma dosyası hangi değişkenlerin mevcut olduğunu, nasıl işleneceğini ve hangi gizlilik sınırlamalarının uygulanacağını tanımlıyor; böylece her adım şeffaf ve tekrarlanabilir oluyor. Sistem, karmaşık kurulumlarla uğraşmadan hastaneler ve araştırma merkezleri için dağıtımı kolaylaştıran bir kapsayıcı içinde paketlenmiş açık kaynak yazılım olarak sunuluyor. 
Sentetik Veri Fabrikası Nasıl Çalışıyor
Veriler hazırlandıktan sonra, farklı türde derin üretici ağlar da dahil olmak üzere birkaç gelişmiş yapay zeka modeli gerçek veri setlerindeki desenleri taklit edecek şekilde eğitiliyor. Öne çıkan model TabSyn adını taşıyor; sayılar ve kategorilerden oluşan karmaşık tablolar için orijinal olarak geliştirilen dönüştürücü (transformer) tabanlı bir difüzyon yöntemi. Ekip, modeli hem bireysel dağılımları (örneğin gerçekçi yaş veya kan basıncı aralıkları) hem de değişkenler arasındaki ilişkileri (örneğin kilo ile vücut kitle indeksi arasındaki bağlantı) doğru yakalamaya özellikle ödül veren CorrDst adlı özel bir kayıp fonksiyonu ile güçlendiriyor. Ardından doğruluk, sonlandırılmış makine öğrenimi görevleri için kullanılabilirlik ve gizlilik koruması olmak üzere üç hedefin aynı anda dengelendiği otomatik bir arama stratejisiyle model ayarlarını ince ayarlıyorlar.
Gizliliği Bozmayacak Şekilde Gerçekçiliği Korumak
Üretilen verilerin yeterince iyi olup olmadığını değerlendirmek için çerçeve her modeli birden fazla eksende test ediyor. İstatistiksel testler gerçek ve sentetik veri kümeleri arasındaki temel dağılımları ve korelasyonları karşılaştırıyor. Makine öğrenimi testleri, sentetik veriler üzerinde eğitim yapılan tahmin modellerinin gerçek kayıtlar üzerinde nasıl performans gösterdiğini ölçerek bilgi aktarımını değerlendiriyor. Aynı zamanda, hem kuramsal hem de ampirik gizlilik kontrolleri, sentetik verilerden gerçek bir kişinin yeniden tanımlanma olasılığını tahmin ediyor. Sonuçlar, CorrDst ile birleştirilen TabSyn’in özellikle çok eksik değere sahip yüksek boyutlu kanser veri setlerinde eski üretici yaklaşımları düzenli olarak geride bıraktığını gösteriyor. Cinsiyete özgü kanserler ve sigara ile akciğer hastalığı arasındaki bağlantılar gibi önemli tıbbi desenleri koruyor, mantıksız uç değerler üretmiyor ve makul hesaplama süreleri içinde çalışıyor.
Dağınık Tıbbi Verileri Kullanılabilir Hale Getirmek
Sağlık araştırmalarında büyük bir engel gerçek dünya verilerinin dağınık olmasıdır: birçok laboratuvar sonucu eksik, ölçüm zamanları değişken ve bazı değişkenler sıkı biyolojik kurallara uymak zorundadır. Yazarlar, eksik değerleri yapılandırılmış biçimde tahmin eden, çarpık sayısal değişkenleri daha stabil formlara dönüştüren ve verinin eksik olduğu yerleri açıkça işaretleyen göstergeler ekleyen özel bir ön işleme hattı tasarlıyor. Bu yaklaşım, yaş, kilo ve vücut kitle indeksi gibi imkansız kombinasyonlar üreten daha basit yöntemleri bulanıklaştıran artefaktları büyük ölçüde azaltıyor. Üretim sonrasında, kalite kontrol aşaması otomatik kontrollerle birlikte uzman incelemesi kullanarak tıbbi mantığa aykırı sentetik kayıtları (örneğin kadınlara atanan prostat kanseri) reddediyor. 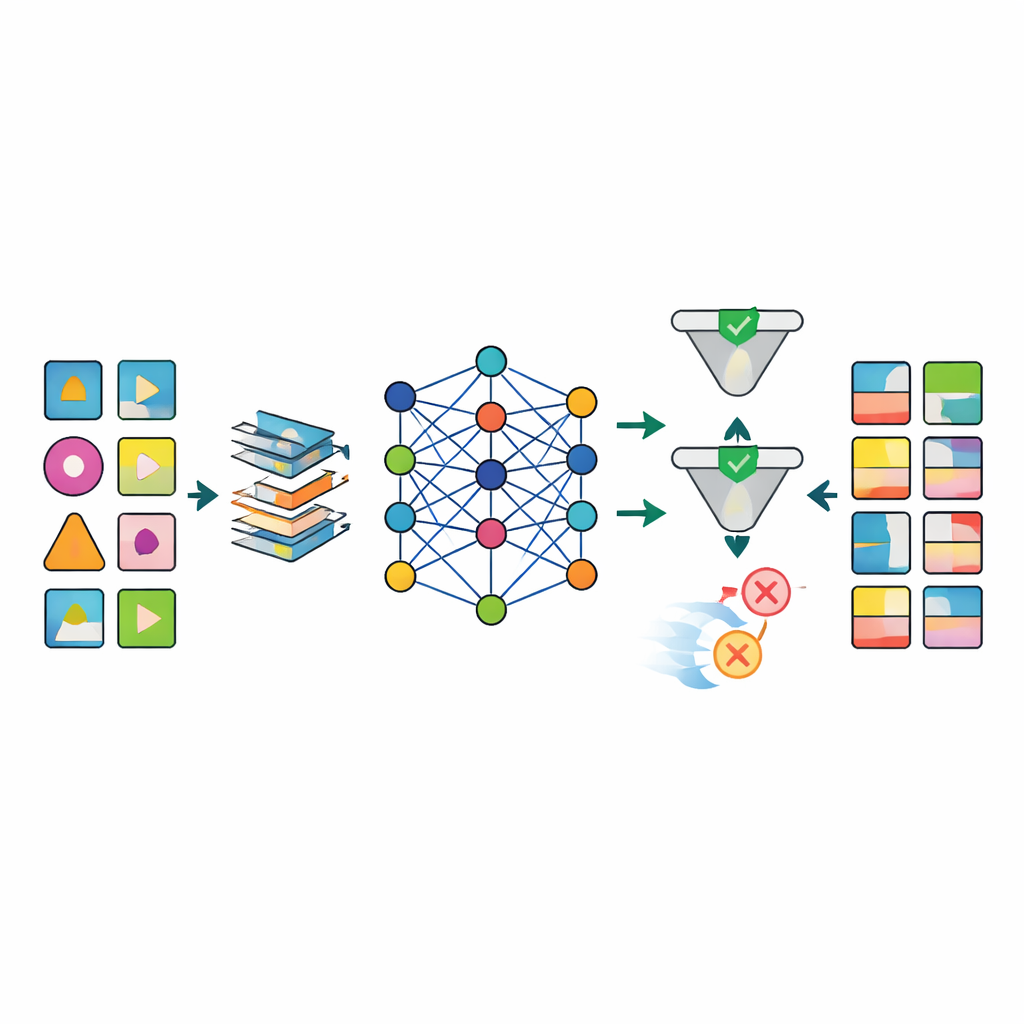
İnsanları Görmeden Veriyi Görmek
Üretimin ötesinde, ekip araştırmacıların kohort özelliklerini—örneğin yaş ve cinsiyete göre kaç kişinin hem akciğer kanseri hem de obeziteye sahip olduğunu—keşfetmesine olanak veren etkileşimli bir görselleştirme aracı geliştiriyor; bu sırada gizlilik sızıntılarına karşı koruma sağlanıyor. k-anonimiteye dayalı uyarlanabilir bir anonimleştirme algoritması, hiçbir ayar kombinasyonunun ondan az bireyi ortaya çıkarmayacak şekilde filtreleri dinamik olarak kabalaştırıyor veya kaldırıyor. Bu, zengin sağlık verileri üzerinde birimlerin hassas ayrıntılarını açığa çıkarmadan uygulanabilirlik kontrolleri ve hipotez oluşturmayı mümkün kılıyor.
Bu Hastalar ve Araştırmacılar İçin Ne Anlama Geliyor?
Basitçe söylemek gerekirse, makale artık ayrıntılı sağlık kayıtlarının gerçekçi, gizliliği koruyan temsilcilerini seri şekilde üretebilmenin mümkün olduğunu gösteriyor. Akıllı ön işleme, yüksek performanslı bir üretici model, titiz gizlilik testleri ve insan kalite kontrolünü birleştirerek çerçeve, orijinaller gibi analizlerde davranan ancak paylaşılması çok daha güvenli olan sentetik veri kümeleri sunuyor. Geniş çapta benimsenirse, bu tür araçlar işbirlikçi araştırmalar için geniş biyobank kaynaklarının kilidini açabilir, hasta sayısının sınırlı olduğu nadir hastalık çalışmalarını iyileştirebilir ve bilimsel ilerlemeyi feda etmeden yasal gerekliliklerin karşılanmasına yardımcı olabilir.
Atıf: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
Anahtar kelimeler: sentetik sağlık verileri, hasta gizliliği, biyobank araştırması, diferansiyel gizlilik, tıbbi yapay zeka