Clear Sky Science · sv
Anonymisering och visualisering av hälsodata och biomarkörer
Varför dina medicinska journaler är så svåra att dela
Modern medicin bygger på data: ju fler patientjournaler forskare kan analysera, desto bättre kan de förstå sjukdomar och förbättra behandlingar. Men strikta integritetsregler innebär att mycket av denna information är låst, särskilt när den kommer från detaljerade sjukhus- och biobanksjournaler. Den här artikeln presenterar ett praktiskt sätt att skapa realistiska ”fejkade” hälsodatamängder som skyddar individers integritet samtidigt som de förblir användbara för forskning — vilket potentiellt öppnar en säkrare väg för datadelning globalt.
Förvandla låsta journaler till säkra liknelser
Forskarna byggde ett ända‑till‑ända‑system som tar känsliga hälsoregister och omvandlar dem till syntetiska data — poster som statistiskt sett ser ut och beter sig som verkliga, men som inte motsvarar någon faktisk person. Deras ramverk börjar med noggrann rensning och organisering av sjukhusjournaler, frågeformulär, laboratorietester och cancerregisterdata från över 50 000 individer i norra Sverige. En enda konfigurationsfil beskriver vilka variabler som finns, hur de ska hanteras och vilka integritetsgränser som gäller, så att varje steg är transparent och reproducerbart. Systemet distribueras som öppen källkod inpackat i en container, vilket gör det lättare för sjukhus och forskningscentra att driftsätta utan att brottas med komplex installation. 
Hur den syntetiska datafabriken fungerar
När data har förberetts tränas flera avancerade artificiella intelligensmodeller, inklusive olika typer av djupa generativa nätverk, för att imitera mönstren i de verkliga datasetten. Den framstående modellen, kallad TabSyn, är en transformerbaserad diffusionsmetod som ursprungligen utvecklats för komplexa tabeller med tal och kategorier. Teamet kompletterar den med en särskild förlustfunktion, CorrDst, som uttryckligen belönar modellen för att både få rätt på de individuella fördelningarna (till exempel realistiska ålders- eller blodtrycksområden) och sambanden mellan variabler (som kopplingen mellan vikt och kroppsmassindex). De använder sedan en automatiserad sökstrategi för att justera modellinställningarna så att tre mål balanseras samtidigt: noggrannhet, användbarhet för efterföljande maskininlärningsuppgifter och integritetsskydd.
Behålla realism utan att bryta integriteten
För att bedöma om de genererade uppgifterna är tillräckligt bra utvärderar ramverket varje modell längs flera axlar. Statistiska tester jämför grundläggande fördelningar och korrelationer mellan verkliga och syntetiska dataset. Maskininlärningstester tränar prediktionsmodeller på syntetiska data och testar dem på de verkliga registren för att se hur väl kunskap överförs. Samtidigt uppskattar formella och empiriska integritetskontroller hur sannolikt det är att en verklig person kan återidentifieras från de syntetiska uppgifterna. Resultaten visar att TabSyn kombinerat med CorrDst konsekvent överträffar äldre generativa metoder, särskilt på högdimensionella cancerdataset med många saknade värden. Den bevarar viktiga medicinska mönster — som könsspecifika cancersjukdomar och kopplingar mellan rökning och lungsjukdom — utan att producera osannolika extremvärden, och gör det med rimliga beräkningstider.
Göra röriga medicinska data användbara
Ett stort hinder i hälsoresearch är att verkliga data är röriga: många laboratorieresultat saknas, mättider varierar och vissa variabler måste följa strikt biologisk logik. Författarna utformar ett skräddarsytt förbehandlingsflöde som imputerar saknade värden på ett strukturerat sätt, omformar skeva numeriska variabler till mer stabila representationer och lägger till indikatorer som uttryckligen markerar var data saknades. Denna strategi minskar kraftigt artefakter som plågar enklare metoder, såsom omöjliga kombinationer av ålder, vikt och kroppsmassindex. Efter genereringen använder en kvalitetskontrollfas både automatiska kontroller och expertgranskning för att avvisa syntetiska poster som bryter mot medicinsk logik (till exempel prostatacancer tilldelad kvinnor). 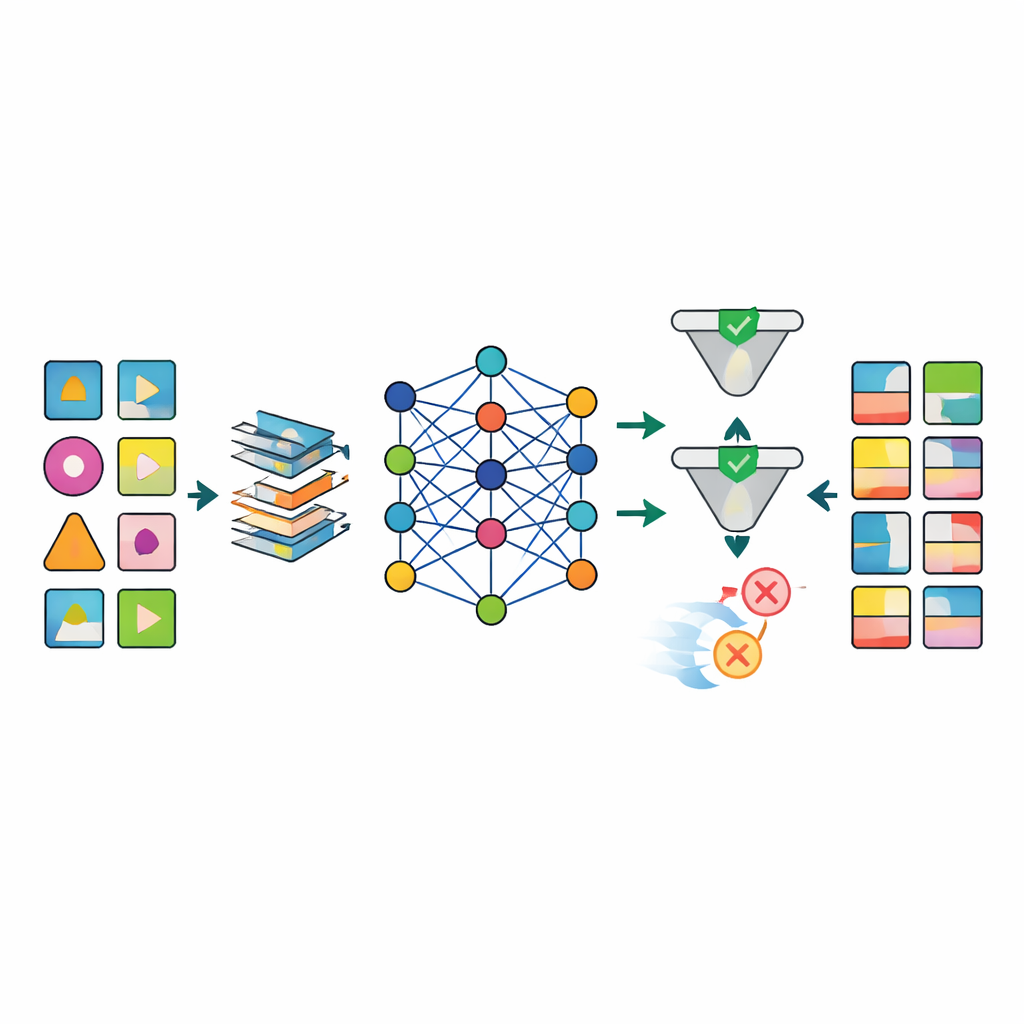
Se data utan att se människorna
Utöver generering bygger teamet ett interaktivt visualiseringsverktyg som låter forskare utforska kohortegenskaper — till exempel hur många som har både lungcancer och fetma, uppdelat efter ålder och kön — samtidigt som det skyddar mot integritetsläckor. En adaptiv anonymiseringsalgoritm baserad på k‑anonymitet förfinar eller tar bort filter dynamiskt så att ingen kombination av inställningar någonsin avslöjar färre än tio individer. Detta möjliggör genomförbarhetskontroller och hypotesgenerering på rika hälsodata utan att exponera känsliga detaljer om någon enskild person.
Vad detta innebär för patienter och forskare
Kortfattat visar artikeln att det nu är möjligt att massproducera realistiska, integritetsskyddande ställföreträdare för detaljerade journaler. Genom att kombinera smart förbehandling, en högpresterande generativ modell, rigorösa integritetsprov och mänsklig kvalitetskontroll levererar ramverket syntetiska dataset som beter sig som originalen i analyser men som är mycket säkrare att dela. Om sådana verktyg antas i stor skala kan de låsa upp omfattande biobanksresurser för samarbetsforskning, förbättra studier av sällsynta sjukdomar med få patienter och hjälpa till att uppfylla lagkrav utan att offra vetenskaplig framsteg.
Citering: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
Nyckelord: syntetiska hälsodata, patientintegritet, biobanksforskning, differentialsekretess, medicinsk AI