Clear Sky Science · ja
健康データとバイオマーカーの匿名化と可視化
医療記録が共有しにくい理由
現代医療はデータに依存しています。研究者が解析できる患者記録が多ければ多いほど、病気の理解が深まり治療が改善されます。しかし、厳しいプライバシー規制により、多くの情報は特に詳細な病院記録やバイオバンクの記録からは閉ざされています。本稿は、個人のプライバシーを保護しつつ研究に有用な現実的な「擬似」健康データセットを作成する実践的な方法を紹介し、より安全なデータ共有の道を開く可能性を示します。
閉ざされた記録を安全な類似物に変える
研究チームは、機微な健康記録を合成データに変換するエンドツーエンドのシステムを構築しました。合成データは統計的には実データと似ているが、実在の個人には対応しない記録です。フレームワークは、北スウェーデンの5万人超の個人に関する病院の診療録、質問票、検査結果、がん登録データを慎重にクリーニングして整理することから始まります。単一の設定ファイルで変数の存在、取り扱い方法、適用されるプライバシー制限を記述するため、各工程が透明で再現可能になります。システムはオープンソースソフトウェアとしてコンテナに梱包され配布され、病院や研究機関が複雑なインストールに悩むことなく導入しやすくなっています。 
合成データ工場の仕組み
データが準備されると、深層生成ネットワークを含む複数の高度な人工知能モデルが実データのパターンを模倣するように学習されます。注目すべきモデルはTabSynと呼ばれる、数値とカテゴリを含む複雑な表形式データ向けに開発されたトランスフォーマー基盤の拡散法です。研究チームはこれにCorrDstという特別な損失関数を付加し、個々の分布(たとえば現実的な年齢や血圧範囲)と変数間の関係(体重とBMIの関連など)の両方を正確に再現することに報酬を与えます。さらに、自動化された探索戦略でモデル設定を調整し、精度、下流の機械学習タスクへの有用性、プライバシー保護という三つの目標を同時にバランスさせます。
プライバシーを損なわずに現実性を保つ
生成されたデータが十分かどうかを判断するために、フレームワークは複数の軸で各モデルを評価します。統計的検定で実データと合成データの基本的な分布や相関を比較します。機械学習の試験では合成データで予測モデルを訓練し、実データでテストして知識の移転性を確認します。同時に、形式的および経験的なプライバシーチェックで、合成データから実在の人物が再特定される可能性を推定します。結果は、TabSynにCorrDstを組み合わせた手法が、とくに欠損の多い高次元のがんデータセットで従来の生成手法を一貫して上回ることを示しています。性別特有のがんや喫煙と肺疾患の関連といった重要な医療パターンを保持しながら、あり得ない極端値を生み出さず、計算時間も妥当な範囲に収まります。
扱いにくい医療データを使える形にする
ヘルスリサーチの大きな障害は、実世界のデータが散漫であることです。多くの検査値が欠損し、測定時刻もばらつき、一部の変数は厳格な生物学的ルールに従わねばなりません。著者らは、欠損値を構造化された方法で補完し、歪んだ数値変数を安定した形へリシェイプし、どこが欠損だったかを明示するインジケータを追加するという専用の前処理パイプラインを設計しました。このアプローチは、年齢・体重・BMIのあり得ない組み合わせのような単純な手法を悩ますアーティファクトを大幅に減らします。生成後の品質管理段階では、自動チェックと専門家による点検の両方を用いて医療的に矛盾する合成記録(例:女性に割り当てられた前立腺がん)を除外します。 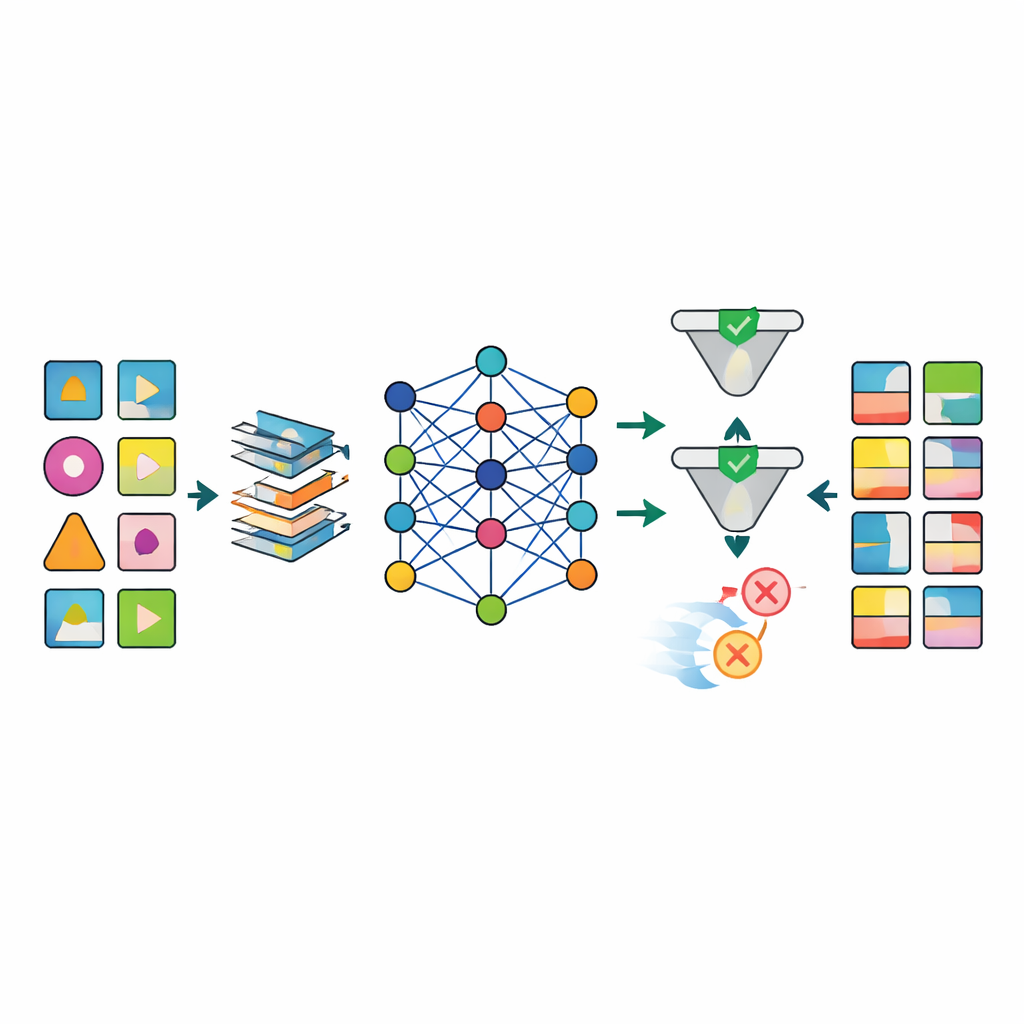
人を見ずにデータを観察する
生成に加え、チームは研究者が年齢・性別ごとに肺がんと肥満の両方を持つ人数のようなコホート特性を探索できるインタラクティブな可視化ツールを構築しつつ、プライバシー漏洩を防いでいます。k-匿名性に基づく適応的匿名化アルゴリズムがフィルタを動的に粗くしたり除去したりして、どの設定の組み合わせでも常に10人未満が特定されないようにします。これにより、個人の機微な情報を曝すことなく、豊富な健康データ上で実現可能性の確認や仮説生成が可能になります。
患者と研究者にとっての意味
簡潔に言えば、この記事は詳細な医療記録の現実的でプライバシー保護された代替データを大量生産することが可能になったことを示しています。洗練された前処理、高性能な生成モデル、厳格なプライバシーテスト、および人的な品質管理を組み合わせることで、このフレームワークは解析上は元データと同等に振る舞うが共有に当たってははるかに安全な合成データセットを提供します。広く採用されれば、こうしたツールは共同研究のために膨大なバイオバンク資源を解放し、患者数が限られる希少疾患の研究を改善し、法的要件を満たしつつ科学的進展を損なわない手助けになる可能性があります。
引用: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
キーワード: 合成健康データ, 患者のプライバシー, バイオバンク研究, 差分プライバシー, 医療用AI