Clear Sky Science · ru
Анонимизация и визуализация данных о здоровье и биомаркерах
Почему ваши медицинские записи так сложно передавать
Современная медицина базируется на данных: чем больше записей пациентов могут проанализировать исследователи, тем лучше они понимают болезни и улучшают методы лечения. Но строгие правила конфиденциальности означают, что многие данные остаются недоступными, особенно когда речь идёт о подробных записях госпиталей и биобанков. В этой статье представлен практичный способ создания правдоподобных «фальшивых» наборов медицинских данных, которые защищают приватность отдельных лиц, оставаясь полезными для исследований — что может открыть более безопасный путь для обмена данными по всему миру.
Превращая закрытые записи в безопасные аналоги
Авторы разработали сквозную систему, которая принимает чувствительные медицинские записи и преобразует их в синтетические данные — записи, которые статистически выглядят и ведут себя как реальные, но не соответствуют никакому конкретному человеку. Их фреймворк начинается с тщательной очистки и упорядочивания больничных журналов, анкет, лабораторных тестов и данных регистров рака от более чем 50 000 человек с севера Швеции. Один конфигурационный файл описывает, какие переменные существуют, как их следует обрабатывать и какие ограничения приватности применяются, чтобы каждый шаг был прозрачен и воспроизводим. Система распространяется как программное обеспечение с открытым исходным кодом в контейнере, что упрощает развертывание в больницах и исследовательских центрах без сложных установок. 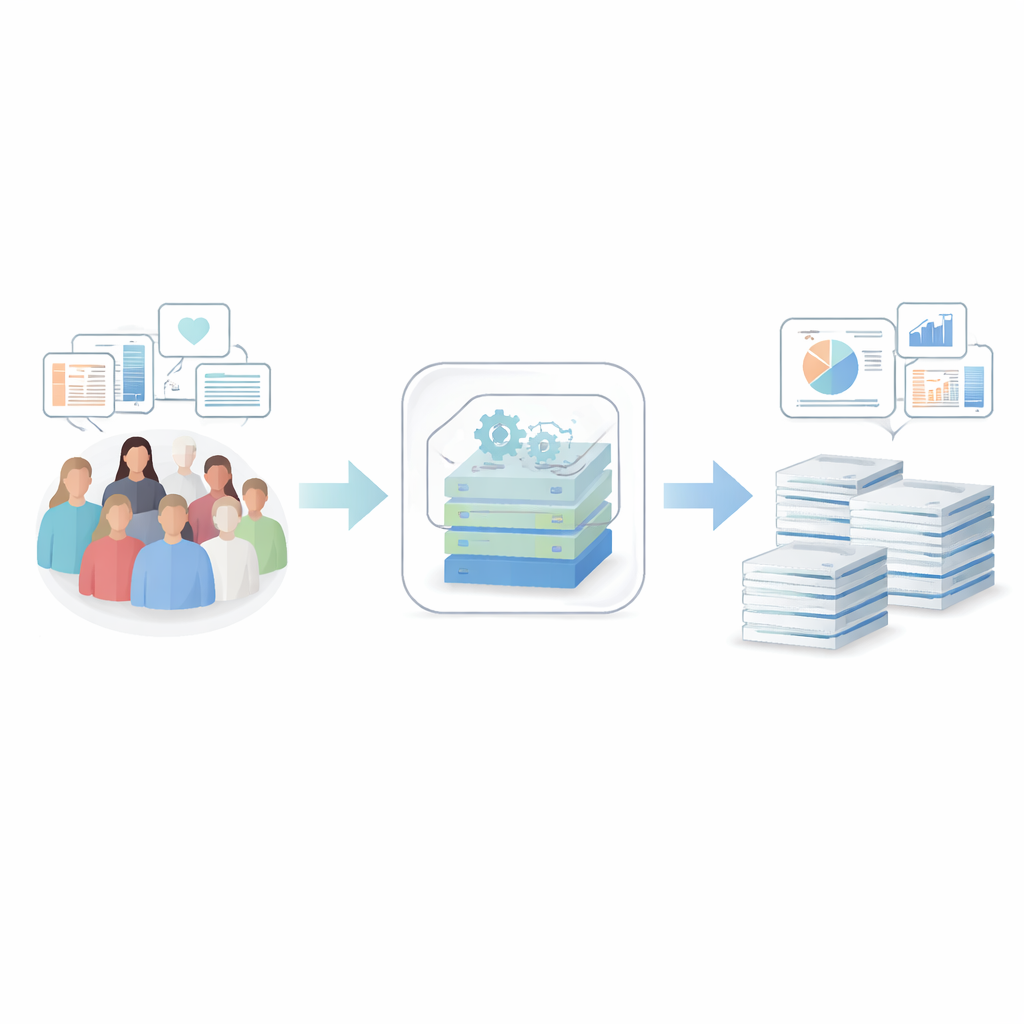
Как работает фабрика синтетических данных
После подготовки данных несколько продвинутых моделей искусственного интеллекта, включая различные типы глубоких генеративных сетей, обучаются имитировать закономерности в реальных наборах. Выдающаяся модель, названная TabSyn, — это метод диффузии на основе трансформера, первоначально разработанный для сложных таблиц с числовыми и категориальными данными. Команда дополняет её специальной функцией потерь CorrDst, которая явно поощряет модель корректно воссоздавать как отдельные распределения (например, реалистичные диапазоны возраста или давления), так и взаимосвязи между переменными (например, связь между весом и индексом массы тела). Затем они используют автоматизированный поиск для настройки параметров модели так, чтобы одновременно сбалансировать три цели: точность, полезность для задач машинного обучения и защиту приватности.
Сохранение реалистичности без нарушения приватности
Чтобы оценить, насколько сгенерированные данные соответствуют требованиям, фреймворк проверяет каждую модель по нескольким осям. Статистические тесты сравнивают базовые распределения и корреляции между реальными и синтетическими наборами. Тесты на машинном обучении обучают предиктивные модели на синтетических данных и проверяют их на реальных записях, чтобы понять, насколько хорошо знания переносятся. Одновременно формальные и эмпирические проверки приватности оценивают вероятность того, что реальный человек может быть восстановлен по синтетическим данным. Результаты показывают, что TabSyn в сочетании с CorrDst стабильно превосходит старые генеративные подходы, особенно на высокоразмерных онкологических наборах с множеством пропусков. Модель сохраняет ключевые медицинские закономерности — например, специфичные для пола виды рака и связи между курением и заболеваниями лёгких — не производя неправдоподобных крайностей, при этом требуя разумного времени вычислений.
Делая беспорядочные медицинские данные пригодными для работы
Главная проблема в медицинских исследованиях — это то, что данные из реального мира часто «грязные»: многих лабораторных результатов нет, времена измерений варьируются, а некоторые переменные должны подчиняться строгим биологическим правилам. Авторы разработали индивидуальную конвейерную обработку, которая структурированно заполняет пропуски, преобразует скошенные числовые переменные в более стабильные формы и добавляет индикаторы, явно отмечающие, где данные отсутствовали. Такой подход резко сокращает артефакты, характерные для более простых методов, например невозможные комбинации возраста, веса и индекса массы тела. После генерации этап контроля качества использует как автоматические проверки, так и экспертную инспекцию для отбраковки синтетических записей, нарушающих медицинскую логику (например, диагноз рак простаты, назначенный женщинам). 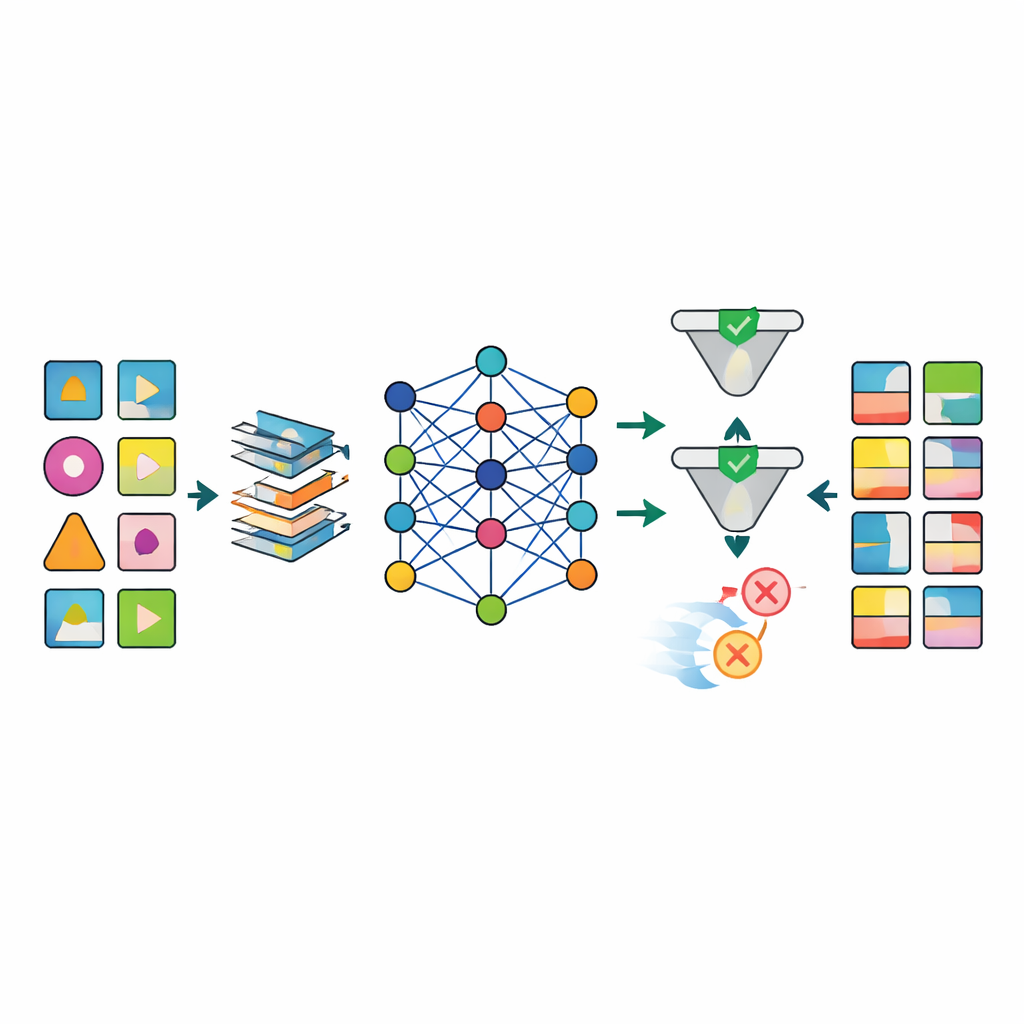
Видеть данные, не видя людей
Помимо генерации команда создала интерактивный инструмент визуализации, который позволяет исследователям изучать характеристики когорты — например, сколько людей имеют одновременно рак лёгких и ожирение, распределённых по возрасту и полу — при этом предотвращая утечки приватности. Адаптивный алгоритм анонимизации на основе k‑анонимности динамически упрощает или удаляет фильтры так, чтобы никакая комбинация настроек не раскрывала менее десяти человек. Это позволяет проводить проверки реализуемости и генерировать гипотезы на богатых медицинских данных, не подвергая риску конфиденциальные сведения о конкретных людях.
Что это значит для пациентов и исследователей
Проще говоря, статья показывает, что теперь можно массово производить реалистичные, защищающие приватность заменители подробных медицинских записей. Комбинируя продуманную предобработку, высокоэффективную генеративную модель, строгие тесты приватности и человеческий контроль качества, фреймворк даёт синтетические наборы данных, которые ведут себя как оригиналы в анализах, но гораздо безопаснее для обмена. При широком внедрении такие инструменты могли бы открыть огромные ресурсы биобанков для совместных исследований, улучшить изучение редких заболеваний с ограниченным числом пациентов и помочь выполнить законодательные требования без ущерба для научного прогресса.
Цитирование: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
Ключевые слова: синтетические медицинские данные, конфиденциальность пациентов, исследования биобанков, дифференциальная приватность, медицинский ИИ