Clear Sky Science · de
Anonymisierung und Visualisierung von Gesundheitsdaten und Biomarkern
Warum sich Ihre Krankenakten so schwer teilen lassen
Die moderne Medizin lebt von Daten: Je mehr Patientenakten Forschende auswerten können, desto besser lassen sich Krankheiten verstehen und Behandlungen verbessern. Strenge Datenschutzregeln sorgen allerdings dafür, dass viele dieser Informationen nicht frei zugänglich sind, besonders wenn sie aus detaillierten Krankenhaus‑ und Biobankaufzeichnungen stammen. Dieser Artikel stellt einen praktischen Weg vor, realistische „gefälschte“ Gesundheitsdatensätze zu erzeugen, die die Privatsphäre einzelner schützen und zugleich für Forschungszwecke nützlich bleiben — und damit weltweit einen sichereren Pfad zum Datenaustausch eröffnen können.
Aus gesperrten Akten sichere Nachbildungen machen
Die Forschenden haben ein End‑to‑End‑System entwickelt, das sensible Gesundheitsakten in synthetische Daten verwandelt — Datensätze, die statistisch wie die Originale aussehen und sich ähnlich verhalten, aber keiner realen Person entsprechen. Ihr Rahmenwerk beginnt mit sorgfältigem Säubern und Strukturieren von Krankenakten, Fragebögen, Laborwerten und Krebsregisterdaten von über 50.000 Personen im Norden Schwedens. Eine einzelne Konfigurationsdatei beschreibt, welche Variablen existieren, wie sie behandelt werden sollen und welche Datenschutzgrenzen gelten, sodass jeder Schritt transparent und reproduzierbar ist. Das System wird als Open‑Source‑Software in einem Container ausgeliefert, was Krankenhäusern und Forschungszentren die Bereitstellung erleichtert, ohne sich mit komplizierten Installationen herumschlagen zu müssen. 
Wie die Fabrik für synthetische Daten arbeitet
Sobald die Daten vorbereitet sind, werden mehrere fortgeschrittene KI‑Modelle, darunter verschiedene Arten tiefer generativer Netze, trainiert, um die Muster in den Real‑Datensätzen nachzuahmen. Das herausragende Modell, TabSyn genannt, ist eine transformerbasierte Diffusionsmethode, die ursprünglich für komplexe Tabellen mit Zahlen und Kategorien entwickelt wurde. Das Team ergänzt sie um eine spezielle Verlustfunktion, CorrDst, die das Modell explizit dafür belohnt, sowohl die Einzelverteilungen (beispielsweise realistische Alters‑ oder Blutdruckbereiche) als auch die Beziehungen zwischen Variablen (etwa die Verbindung zwischen Gewicht und Body‑Mass‑Index) korrekt abzubilden. Anschließend nutzen sie eine automatisierte Suchstrategie, um die Modelleinstellungen so zu optimieren, dass drei Ziele gleichzeitig ausbalanciert werden: Genauigkeit, Nutzbarkeit für nachgelagerte Machine‑Learning‑Aufgaben und Datenschutz.
Realismus bewahren, ohne die Privatsphäre zu verletzen
Um zu beurteilen, ob die erzeugten Daten ausreichend gut sind, bewertet das Framework jedes Modell entlang mehrerer Achsen. Statistische Tests vergleichen Grundverteilungen und Korrelationen zwischen Original‑ und synthetischen Datensätzen. Machine‑Learning‑Tests trainieren Vorhersagemodelle auf synthetischen Daten und prüfen sie an den realen Aufzeichnungen, um zu sehen, wie gut Wissen übertragbar ist. Gleichzeitig schätzen formale und empirische Datenschutzprüfungen, wie wahrscheinlich es ist, dass eine reale Person aus den synthetischen Daten re‑identifiziert werden könnte. Die Ergebnisse zeigen, dass TabSyn in Kombination mit CorrDst ältere generative Verfahren durchweg übertrifft, insbesondere bei hochdimensionalen Krebsdatensätzen mit vielen fehlenden Werten. Es bewahrt wichtige medizinische Muster — etwa geschlechtsspezifische Krebsarten und Zusammenhänge zwischen Rauchen und Lungenerkrankungen — ohne unplausible Extremwerte zu erzeugen, und das bei moderaten Rechenzeiten.
Unordentliche medizinische Daten nutzbar machen
Ein großes Hindernis in der Gesundheitsforschung sind reale Daten, die unordentlich sind: Viele Laborwerte fehlen, Messzeitpunkte variieren und manche Variablen müssen strenge biologische Regeln einhalten. Die Autor:innen entwerfen eine maßgeschneiderte Vorverarbeitungspipeline, die fehlende Werte strukturiert imputiert, schiefe numerische Variablen in stabilere Formen überführt und Indikatoren hinzufügt, die explizit markieren, wo Daten fehlten. Dieser Ansatz reduziert Artefakte, die einfachere Methoden stark belasten — etwa unmögliche Kombinationen von Alter, Gewicht und Body‑Mass‑Index. Nach der Generierung verwendet eine Qualitätskontrollstufe sowohl automatisierte Prüfungen als auch Experteninspektion, um synthetische Datensätze zu verwerfen, die medizinische Logik verletzen (zum Beispiel Prostatakrebs, der Frauen zugewiesen wurde). 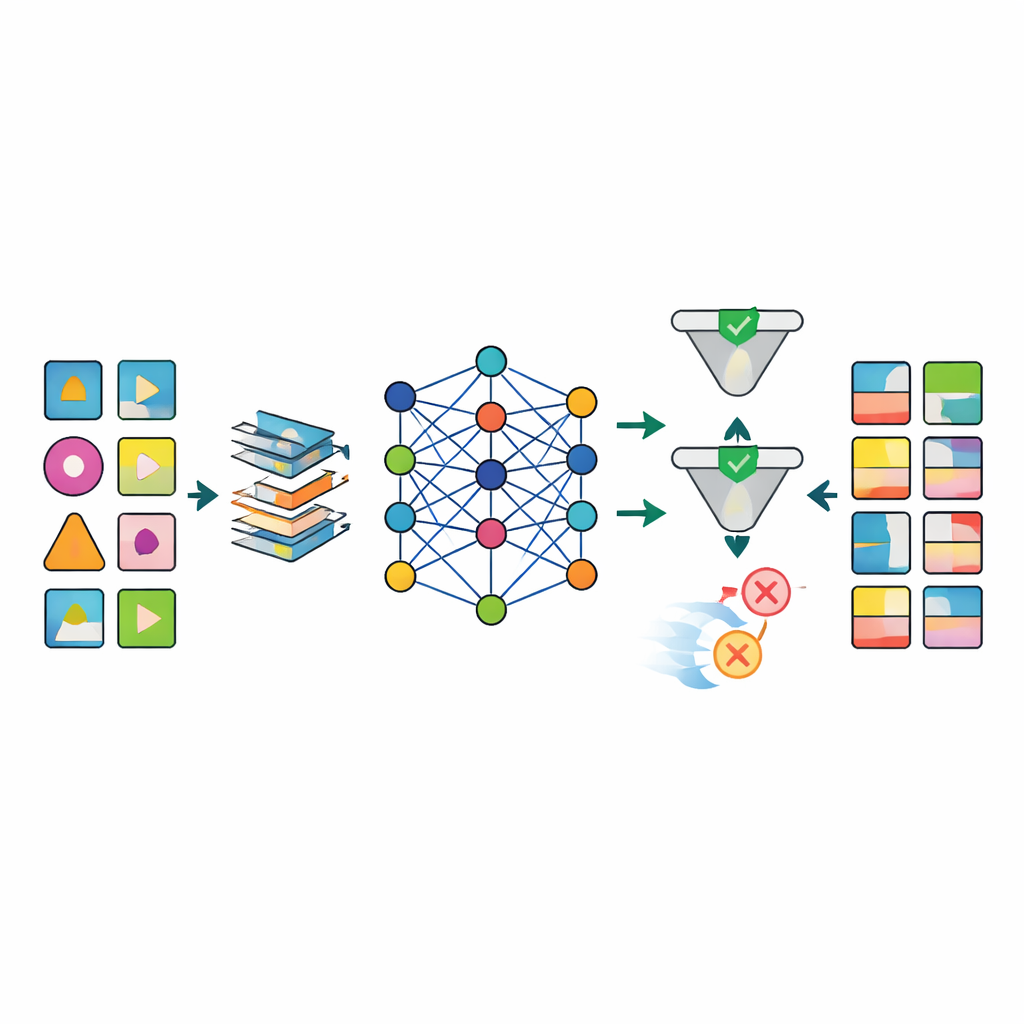
Die Daten sehen, ohne die Personen zu sehen
Über die Generierung hinaus entwickelt das Team ein interaktives Visualisierungstool, mit dem Forschende Kohortenmerkmale erkunden können — zum Beispiel wie viele Personen sowohl Lungenkrebs als auch Adipositas haben, aufgeschlüsselt nach Alter und Geschlecht — und gleichzeitig vor Datenschutzlecks geschützt sind. Ein adaptiver Anonymisierungsalgorithmus auf Basis von k‑Anonymität vergröbert oder entfernt dynamisch Filter, sodass keine Kombination von Einstellungen jemals weniger als zehn Personen offenlegt. Das ermöglicht Machbarkeitsprüfungen und Hypothesenbildung an reichhaltigen Gesundheitsdaten, ohne sensible Details zu einzelnen Personen preiszugeben.
Was das für Patient:innen und Forschende bedeutet
Einfach gesagt zeigt der Artikel, dass es inzwischen möglich ist, realistische, den Datenschutz bewahrende Stellvertreter für detaillierte Gesundheitsakten in großem Maßstab zu erzeugen. Durch die Kombination aus intelligenter Vorverarbeitung, einem leistungsstarken generativen Modell, strengen Datenschutztests und menschlicher Qualitätskontrolle liefert das Framework synthetische Datensätze, die sich in Analysen wie die Originale verhalten, aber deutlich sicherer zu teilen sind. Bei breiter Anwendung könnten solche Werkzeuge riesige Biobank‑Ressourcen für kooperative Forschung öffnen, Studien zu seltenen Erkrankungen mit wenigen Patient:innen verbessern und rechtliche Anforderungen erfüllen, ohne den wissenschaftlichen Fortschritt zu opfern.
Zitation: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
Schlüsselwörter: synthetische Gesundheitsdaten, Patientenschutz, Biobank‑Forschung, differenzielle Privatsphäre, medizinische KI