Clear Sky Science · ar
إخفاء الهوية وتصوير بيانات الصحة والمؤشرات الحيوية
لماذا سجلاتك الطبية صعبة المشاركة إلى هذا الحد
تازدهر الطب الحديث بفضل البيانات: فكلما تمكن الباحثون من تحليل مزيد من السجلات المرضية، ازداد فهمهم للأمراض وتحسّن علاجها. لكن القواعد الصارمة لحماية الخصوصية تعني أن كثيراً من هذه المعلومات مغلقة، خصوصاً عند الاعتماد على سجلات المستشفيات وبيانات حاضنات العينات التفصيلية. يقدم هذا المقال طريقة عملية لإنشاء مجموعات بيانات صحية «مزيفة» واقعية تحمي خصوصية الأفراد بينما تظل مفيدة للبحث، ما قد يفتح طريقاً أكثر أماناً لمشاركة البيانات على مستوى العالم.
تحويل السجلات المقفلة إلى نُسخ آمنة شبيهة
بنَى الباحثون نظاماً شاملاً يأخذ السجلات الصحية الحسّاسة ويحوّلها إلى بيانات تركيبية — سجلات تبدو وتتصرف مثل الحقيقية من الناحية الإحصائية، لكنها لا تطابق أي شخص فعلي. يبدأ إطار العمل بتنظيف وتنظيم دقيق لسجلات المستشفيات، والاستبيانات، والاختبارات المخبرية، وبيانات سجل السرطان لأكثر من 50,000 فرد في شمال السويد. يصف ملف إعداد واحد المتغيرات الموجودة، وكيفية التعامل معها، وما هي حدود الخصوصية المطبقة، بحيث تكون كل خطوة شفافة وقابلة لإعادة التنفيذ. يُوزَّع النظام كبرنامج مفتوح المصدر في حاوية، مما يسهل على المستشفيات ومراكز البحث نشره دون عناء التعامل مع تثبيتات معقدة. 
كيف يعمل مصنع البيانات التركيبية
بعد تحضير البيانات، تُدرَّب عدة نماذج متقدمة للذكاء الاصطناعي، بما في ذلك أنواع مختلفة من الشبكات التوليدية العميقة، على تقليد الأنماط في مجموعات البيانات الحقيقية. النموذج البارز، المسمى TabSyn، هو طريقة انتشارية تعتمد على المحولات طوِّرَت أصلاً للجداول المعقدة من الأرقام والفئات. يعزّز الفريق هذا النموذج بدالة خسارة خاصة، CorrDst، تكافئ النموذج صراحةً عندما يطابق كلّاً من التوزيعات الفردية (مثلاً نطاقات العمر أو ضغط الدم الواقعية) والعلاقات بين المتغيرات (مثل العلاقة بين الوزن ومؤشر كتلة الجسم). ثم يستخدمون استراتيجية بحث آلية لضبط إعدادات النموذج بحيث تتوازن ثلاثة أهداف في آن واحد: الدقة، والفائدة لمهام التعلم الآلي اللاحقة، وحماية الخصوصية.
الحفاظ على الواقعية دون انتهاك الخصوصية
لتقييم جودة البيانات المُولَّدة، يقوِّم إطار العمل كل نموذج عبر محاور متعددة. تقارن الاختبارات الإحصائية التوزيعات الأساسية والارتباطات بين مجموعات البيانات الحقيقية والتركيبية. تختبر تجارب التعلم الآلي مدى انتقال المعرفة عبر تدريب نماذج تنبؤ على البيانات التركيبية واختبارها على السجلات الحقيقية. في الوقت نفسه، تقدر الاختبارات الرسمية والتجريبية للخصوصية احتمالية إمكانية إعادة تحديد هوية شخص حقيقي من البيانات التركيبية. تظهر النتائج أن TabSyn المدمج مع CorrDst يتفوق باستمرار على الأساليب التوليدية الأقدم، خصوصاً في مجموعات بيانات السرطان عالية الأبعاد والتي تحتوي على كثير من القيم المفقودة. يحافظ على الأنماط الطبية الرئيسية — مثل أنواع السرطان الخاصة بالجنس والعلاقات بين التدخين وأمراض الرئة — دون إنتاج قيم متطرفة غير معقولة، كما يحقق ذلك في أوقات حسابية معقولة.
جعل البيانات الطبية المضطربة قابلة للاستخدام
عقبة رئيسية في أبحاث الصحة هي أن بيانات العالم الحقيقي فوضوية: العديد من نتائج المختبر مفقودة، وتختلف أوقات القياس، ويجب أن تلتزم بعض المتغيرات بقواعد بيولوجية صارمة. صمّم المؤلفون خط معالجة مسبق مخصّصاً يعوّض القيم المفقودة بطريقة منظمة، ويعيد تشكيل المتغيرات العددية المشوهة إلى أشكال أكثر استقراراً، ويضيف مؤشرات تحدد صراحةً أماكن فقدان البيانات. يخفض هذا النهج بقوة الآثار الجانبية التي تعاني منها الطرق الأبسط، مثل التراكيب المستحيلة للعمر والوزن ومؤشر كتلة الجسم. بعد التوليد، يستخدم مرحلة مراقبة الجودة كلاً من الفحوصات الآلية وفحص الخبراء لرفض السجلات التركيبية التي تنتهك المنطق الطبي (على سبيل المثال، تعيين سرطان البروستاتا للإناث). 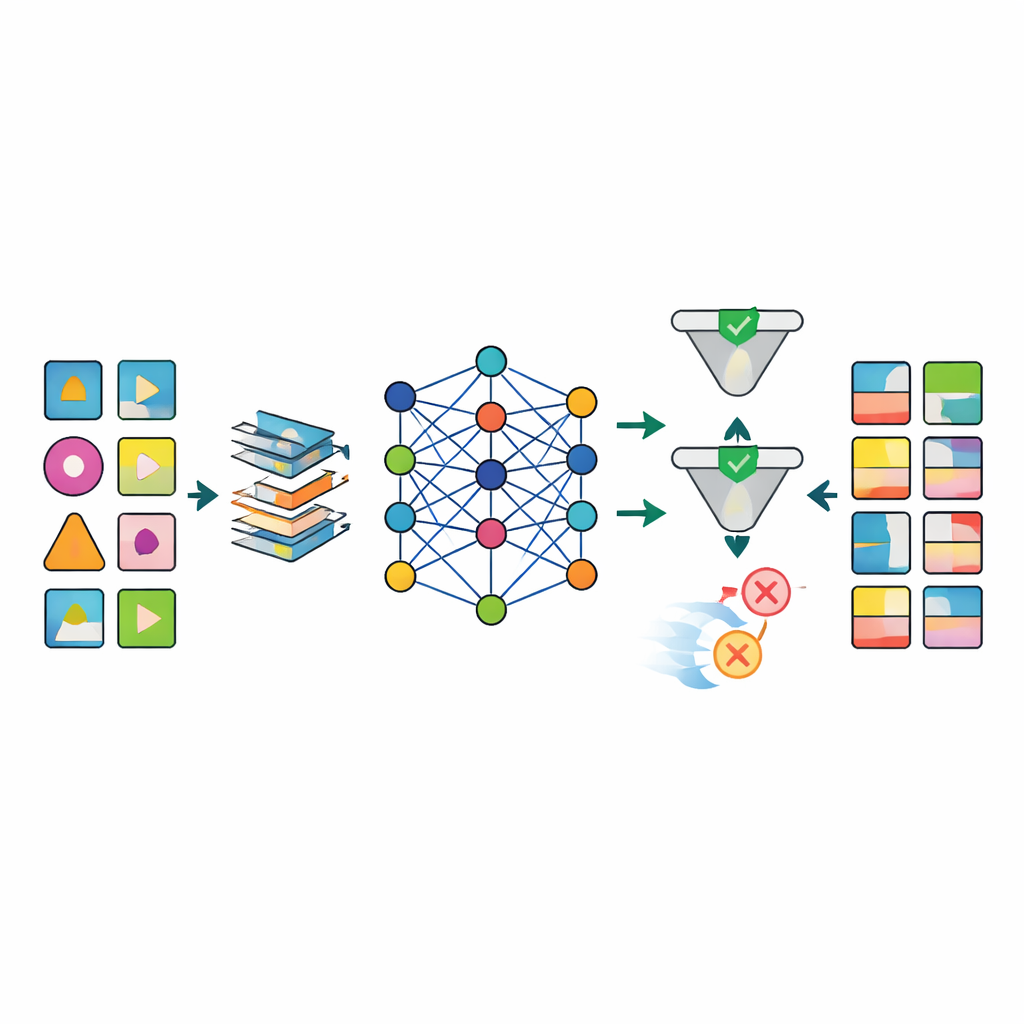
رؤية البيانات دون رؤية الأشخاص
تجاوزاً للتوليد، بنى الفريق أداة تصور تفاعلية تتيح للباحثين استكشاف خصائص العينة — مثل عدد الأشخاص الذين يعانون من كل من سرطان الرئة والسمنة، مفصَّلاً حسب العمر والجنس — مع الحماية من تسرب الخصوصية. خوارزمية إخفاء هوية تكيفية مبنية على k‑anonymity تُخشن أو تزيل عوامل التصفية ديناميكياً بحيث لا تكشف أي مجموعة من الإعدادات عن أقل من عشرة أفراد. يتيح ذلك اختبارات الجدوى وتوليد الفرضيات على بيانات صحية غنية دون الكشف عن تفاصيل حسّاسة عن أي شخص واحد.
ماذا يعني هذا للمرضى والباحثين
بعبارات بسيطة، يبيّن المقال أنه بات بالإمكان الآن إنتاج بدائل تركيبية واقعية ومحافظة على الخصوصية لسجلات صحية تفصيلية على نطاق واسع. من خلال الجمع بين معالجة مسبقة ذكية، ونموذج توليدي ذي أداء عالٍ، واختبارات صارمة للخصوصية، ومراقبة جودة بشرية، يقدّم الإطار مجموعات بيانات تركيبية تتصرف مثل النسخ الأصلية في التحليلات لكنها أكثر أماناً للمشاركة. إذا تم اعتماد هذه الأدوات على نطاق واسع، فيمكنها فتح موارد هائلة من حاضنات العينات للبحث التعاوني، وتحسين الدراسات حول الأمراض النادرة ذات أعداد المرضى المحدودة، والمساعدة في تلبية المتطلبات القانونية دون التضحية بالتقدم العلمي.
الاستشهاد: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
الكلمات المفتاحية: بيانات صحية تركيبية, خصوصية المرضى, أبحاث حاضنات العينات, الخصوصية التفاضلية, الذكاء الاصطناعي الطبي