Clear Sky Science · fr
Anonymisation et visualisation des données de santé et des biomarqueurs
Pourquoi vos dossiers médicaux sont si difficiles à partager
La médecine moderne repose sur les données : plus les chercheurs peuvent analyser d’enregistrements de patients, mieux ils peuvent comprendre les maladies et améliorer les traitements. Mais des règles strictes de confidentialité signifient qu’une grande partie de ces informations reste enfermée, en particulier lorsqu’elles proviennent de dossiers hospitaliers détaillés et de biobanques. Cet article présente une méthode pratique pour créer des jeux de données de santé « faux » mais réalistes qui protègent la vie privée des individus tout en restant utiles pour la recherche, ouvrant potentiellement une voie plus sûre pour le partage de données à l’échelle mondiale.
Transformer des dossiers verrouillés en sosies sûrs
Les chercheurs ont construit un système de bout en bout qui prend des dossiers de santé sensibles et les transforme en données synthétiques — des enregistrements qui ressemblent statistiquement aux originaux et présentent les mêmes comportements, mais ne correspondent à aucune personne réelle. Leur cadre commence par un nettoyage et une organisation soigneux des journaux hospitaliers, des questionnaires, des analyses de laboratoire et des registres du cancer provenant de plus de 50 000 individus dans le nord de la Suède. Un fichier de configuration unique décrit quelles variables existent, comment elles doivent être traitées et quelles limites de confidentialité s’appliquent, de sorte que chaque étape soit transparente et répétable. Le système est distribué en logiciel open source empaqueté dans un conteneur, ce qui facilite son déploiement par les hôpitaux et les centres de recherche sans avoir à gérer des installations complexes. 
Comment fonctionne l’usine de données synthétiques
Une fois les données préparées, plusieurs modèles d’intelligence artificielle avancés, incluant différents types de réseaux génératifs profonds, sont entraînés pour imiter les motifs présents dans les jeux de données réels. Le modèle phare, appelé TabSyn, est une méthode de diffusion basée sur des transformers initialement développée pour des tableaux complexes de nombres et de catégories. L’équipe l’enrichit d’une fonction de perte spéciale, CorrDst, qui récompense explicitement le modèle lorsqu’il reproduit correctement à la fois les distributions individuelles (par exemple, des tranches d’âge ou des plages de tension artérielle réalistes) et les relations entre variables (comme le lien entre le poids et l’indice de masse corporelle). Ils utilisent ensuite une stratégie de recherche automatisée pour ajuster les paramètres du modèle afin d’équilibrer simultanément trois objectifs : précision, utilité pour des tâches d’apprentissage automatique en aval et protection de la vie privée.
Conserver le réalisme sans compromettre la confidentialité
Pour juger de la qualité des données générées, le cadre évalue chaque modèle selon plusieurs axes. Des tests statistiques comparent les distributions de base et les corrélations entre les ensembles réels et synthétiques. Des tests d’apprentissage automatique entraînent des modèles de prédiction sur des données synthétiques et les évaluent sur les dossiers réels pour mesurer la transférabilité des connaissances. Parallèlement, des contrôles de confidentialité formels et empiriques estiment la probabilité qu’une personne réelle puisse être ré-identifiée à partir des données synthétiques. Les résultats montrent que TabSyn combiné à CorrDst surpasse systématiquement les approches génératives plus anciennes, en particulier sur des jeux de données cancéreuses à haute dimensionnalité et comportant de nombreuses valeurs manquantes. Il préserve des schémas médicaux clés — comme les cancers spécifiques au sexe et les liens entre le tabagisme et les maladies pulmonaires — sans produire d’extrêmes implausibles, et ce avec des temps de calcul raisonnables.
Rendre exploitables des données médicales désordonnées
Un obstacle majeur en recherche sur la santé est que les données du monde réel sont désordonnées : de nombreux résultats de laboratoire sont manquants, les moments de mesure varient et certaines variables doivent respecter des règles biologiques strictes. Les auteurs conçoivent une chaîne de prétraitement sur mesure qui impute les valeurs manquantes de manière structurée, transforme les variables numériques fortement asymétriques en formes plus stables et ajoute des indicateurs marquant explicitement les emplacements des données manquantes. Cette approche réduit fortement les artefacts qui nuisent aux méthodes plus simples, tels que des combinaisons impossibles d’âge, de poids et d’indice de masse corporelle. Après génération, une étape de contrôle qualité utilise à la fois des vérifications automatisées et une inspection experte pour rejeter les enregistrements synthétiques qui violent la logique médicale (par exemple, un cancer de la prostate attribué à des femmes). 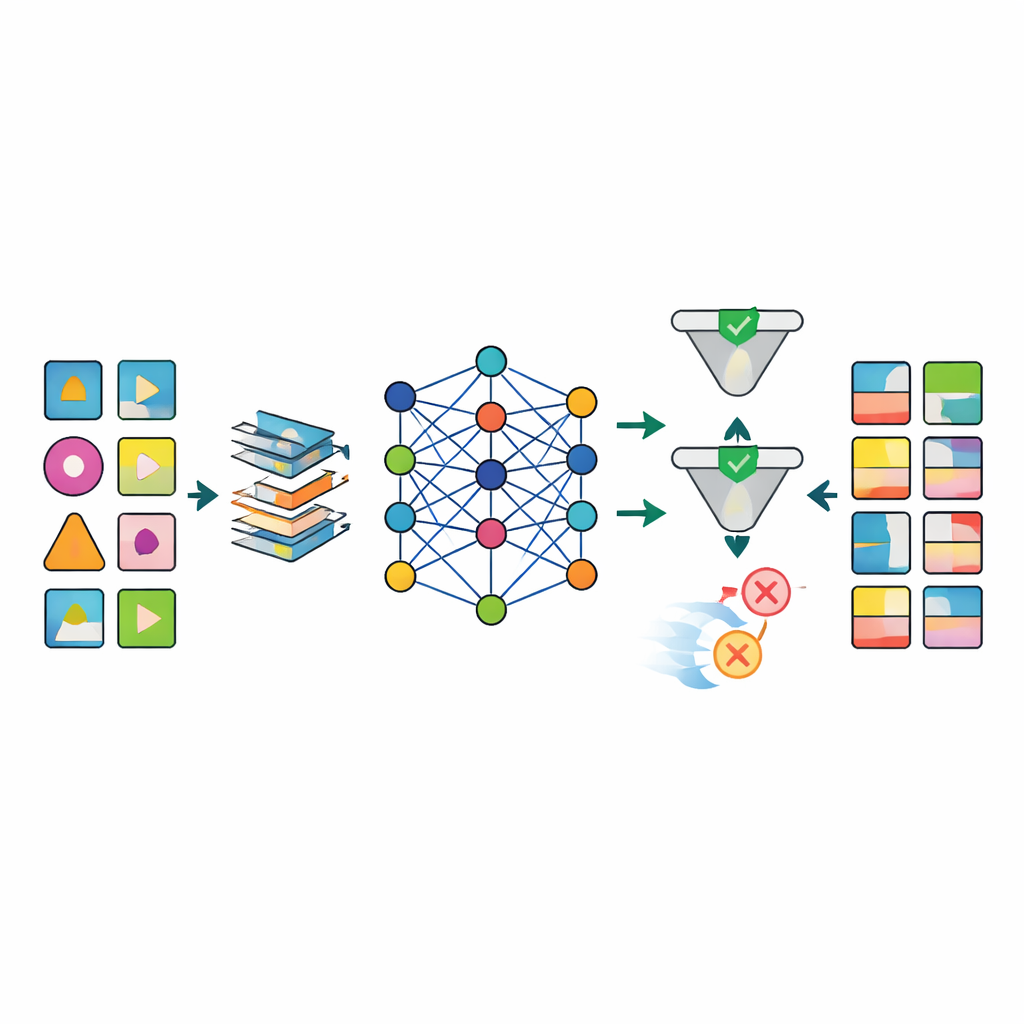
Voir les données sans voir les personnes
Au-delà de la génération, l’équipe a développé un outil de visualisation interactif qui permet aux chercheurs d’explorer les caractéristiques d’une cohorte — par exemple combien de personnes présentent à la fois un cancer du poumon et de l’obésité, ventilées par âge et sexe — tout en protégeant contre les fuites de confidentialité. Un algorithme d’anonymisation adaptatif basé sur la k‑anonymité grossit dynamiquement ou supprime des filtres afin qu’aucune combinaison de paramètres ne révèle jamais moins de dix individus. Cela permet de réaliser des vérifications de faisabilité et de générer des hypothèses sur des données de santé riches sans exposer de détails sensibles sur une personne donnée.
Ce que cela signifie pour les patients et les chercheurs
En termes simples, l’article montre qu’il est désormais possible de produire en masse des doublures réalistes et préservant la vie privée pour des dossiers de santé détaillés. En combinant un prétraitement intelligent, un modèle génératif performant, des tests de confidentialité rigoureux et un contrôle qualité humain, le cadre fournit des jeux de données synthétiques qui se comportent comme les originaux lors des analyses mais sont beaucoup plus sûrs à partager. S’ils sont largement adoptés, de tels outils pourraient débloquer d’importantes ressources de biobanques pour la recherche collaborative, améliorer les études sur les maladies rares avec peu de patients et aider à satisfaire les exigences légales sans sacrifier le progrès scientifique.
Citation: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
Mots-clés: données de santé synthétiques, confidentialité des patients, recherche en biobanque, confidentialité différentielle, IA médicale