Clear Sky Science · it
Anonimizzazione e visualizzazione di dati sanitari e biomarcatori
Perché i tuoi fascicoli medici sono così difficili da condividere
La medicina moderna si nutre di dati: più cartelle cliniche i ricercatori possono analizzare, meglio possono comprendere le malattie e migliorare i trattamenti. Ma regole di privacy stringenti significano che gran parte di queste informazioni resta bloccata, soprattutto quando proviene da registri ospedalieri dettagliati e da biobanche. Questo articolo presenta un modo pratico per creare dataset sanitari “falsi” ma realistici che proteggono la privacy degli individui pur restando utili per la ricerca, aprendo potenzialmente una strada più sicura per la condivisione dei dati a livello globale.
Trasformare registri chiusi in somiglianze sicure
I ricercatori hanno costruito un sistema end‑to‑end che prende registrazioni sanitarie sensibili e le trasforma in dati sintetici—record che somigliano e si comportano come gli originali dal punto di vista statistico, ma non corrispondono a persone reali. Il loro framework comincia con una pulizia e un’organizzazione attente di cartelle ospedaliere, questionari, analisi di laboratorio e dati di registro dei tumori provenienti da oltre 50.000 individui nel nord della Svezia. Un singolo file di configurazione descrive quali variabili esistono, come devono essere trattate e quali limiti di privacy si applicano, in modo che ogni passaggio sia trasparente e ripetibile. Il sistema è distribuito come software open‑source impacchettato in un container, rendendo più facile il dispiegamento per ospedali e centri di ricerca senza dover affrontare installazioni complesse. 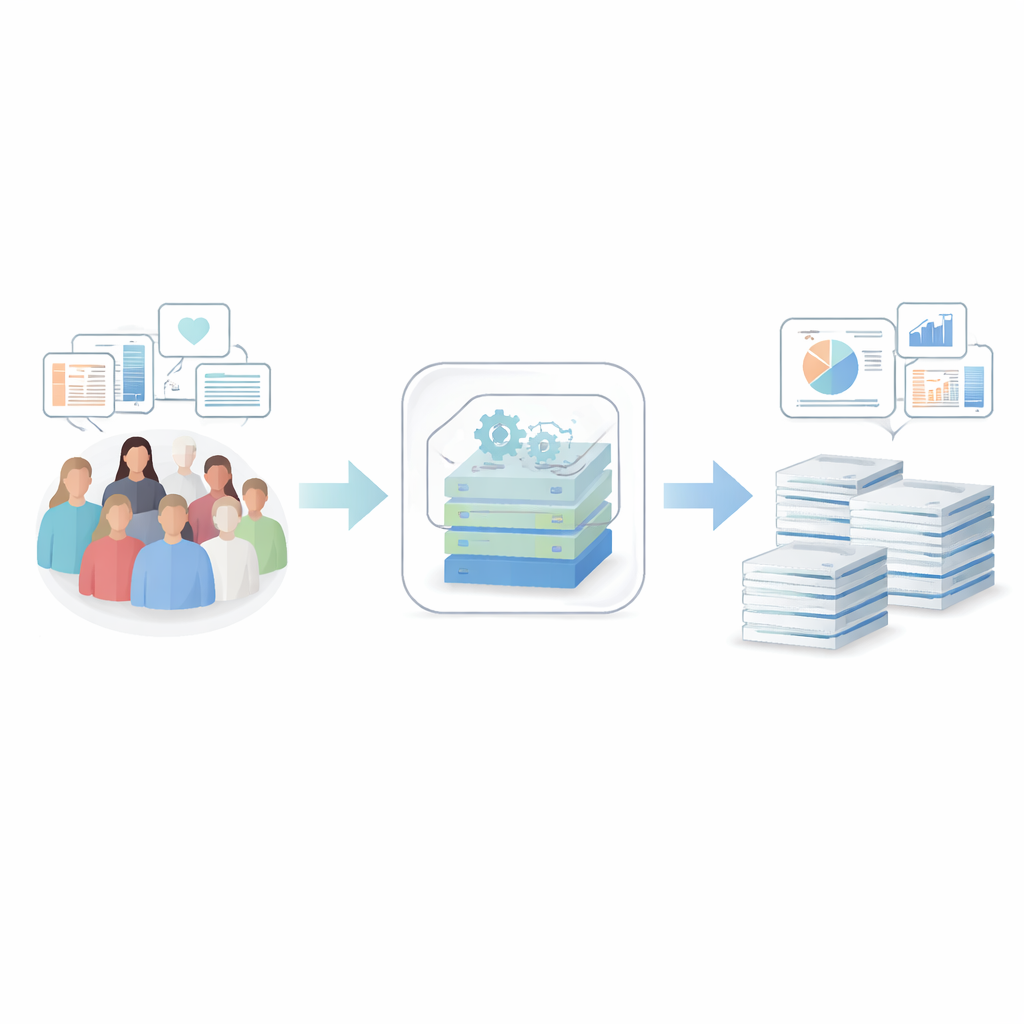
Come funziona la fabbrica di dati sintetici
Una volta preparati i dati, diversi modelli avanzati di intelligenza artificiale, inclusi vari tipi di reti generative profonde, vengono addestrati a imitare i modelli presenti nei dataset reali. Il modello di punta, chiamato TabSyn, è un metodo di diffusione basato su transformer sviluppato originariamente per tabelle complesse di numeri e categorie. Il team lo integra con una funzione di perdita speciale, CorrDst, che premia esplicitamente il modello quando riproduce correttamente sia le distribuzioni individuali (per esempio, range realistici di età o pressione sanguigna) sia le relazioni tra variabili (come il legame tra peso e indice di massa corporea). Usano poi una strategia di ricerca automatizzata per sintonizzare i parametri del modello in modo da bilanciare tre obiettivi contemporaneamente: accuratezza, utilità per compiti di machine learning a valle e protezione della privacy.
Mantenere il realismo senza infrangere la privacy
Per valutare se i dati generati sono sufficientemente validi, il framework valuta ogni modello su più assi. Test statistici confrontano distribuzioni di base e correlazioni tra dataset reali e sintetici. Test di machine learning addestrano modelli predittivi sui dati sintetici e li testano sui record reali per vedere quanto bene si trasferisce la conoscenza. Allo stesso tempo, controlli di privacy formali ed empirici stimano quanto sia probabile che una persona reale possa essere re‑identificata dai dati sintetici. I risultati mostrano che TabSyn combinato con CorrDst supera costantemente approcci generativi più vecchi, soprattutto su dataset oncologici ad alta dimensionalità con molti valori mancanti. Mantiene i principali schemi medici—come i tumori specifici per sesso e i legami tra fumo e malattie polmonari—senza generare estremi implausibili, e lo fa con tempi di calcolo ragionevoli.
Rendere utilizzabili i dati sanitari disordinati
Un ostacolo importante nella ricerca sanitaria è che i dati del mondo reale sono disordinati: molti risultati di laboratorio mancano, i tempi di misura variano e alcune variabili devono rispettare regole biologiche rigide. Gli autori progettano una pipeline di preprocessing su misura che imputa i valori mancanti in modo strutturato, rimodella variabili numeriche asimmetriche in forme più stabili e aggiunge indicatori che segnalano esplicitamente dove i dati erano assenti. Questo approccio riduce nettamente gli artefatti che affliggono metodi più semplici, come combinazioni impossibili di età, peso e indice di massa corporea. Dopo la generazione, una fase di controllo qualità utilizza sia controlli automatizzati sia ispezione esperta per rifiutare record sintetici che violano la logica medica (per esempio, assegnare un cancro alla prostata a donne). 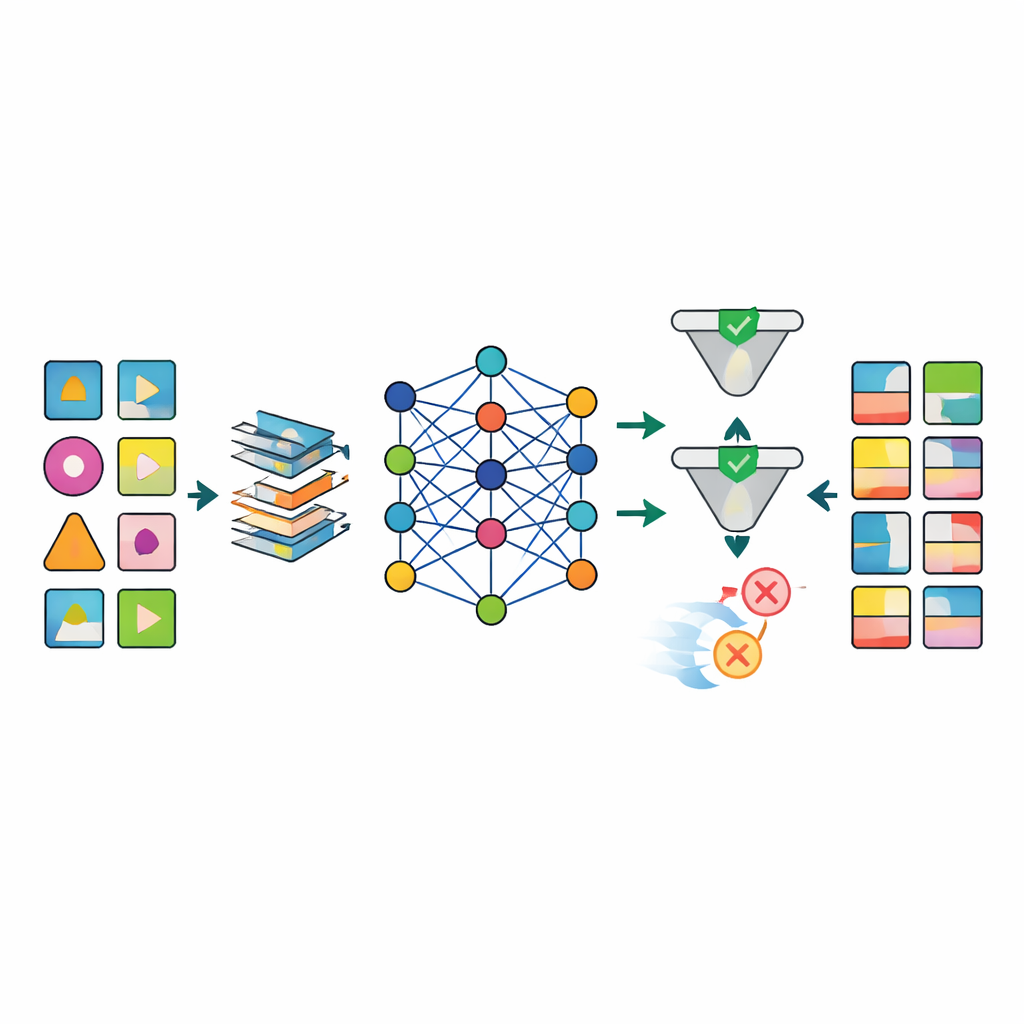
Vedere i dati senza vedere le persone
Oltre alla generazione, il team costruisce uno strumento di visualizzazione interattivo che permette ai ricercatori di esplorare le caratteristiche di coorti—per esempio quante persone hanno sia cancro ai polmoni sia obesità, scomposte per età e sesso—proteggendo allo stesso tempo dalla fuoriuscita di informazioni sensibili. Un algoritmo di anonimizzazione adattivo basato su k‑anonymity corregge dinamicamente il livello di dettaglio o rimuove filtri in modo che nessuna combinazione di impostazioni riveli mai meno di dieci individui. Questo consente controlli di fattibilità e generazione di ipotesi su dati sanitari ricchi senza esporre dettagli sensibili su nessuna persona.
Cosa significa questo per pazienti e ricercatori
In termini semplici, l’articolo dimostra che oggi è possibile produrre in massa sostituti realistici e rispettosi della privacy per cartelle cliniche dettagliate. Combinando un preprocessing intelligente, un modello generativo performante, test rigorosi di privacy e controllo qualità umano, il framework consegna dataset sintetici che si comportano come gli originali nelle analisi ma sono molto più sicuri da condividere. Se adottati su larga scala, tali strumenti potrebbero sbloccare vaste risorse di biobanche per la ricerca collaborativa, migliorare gli studi su malattie rare con numeri di pazienti limitati e aiutare a rispettare requisiti legali senza sacrificare il progresso scientifico.
Citazione: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
Parole chiave: dati sanitari sintetici, privacy dei pazienti, ricerca su biobanche, privacy differenziale, IA medica