Clear Sky Science · nl
Anonimisering en visualisatie van gezondheidsgegevens en biomarkers
Waarom uw medische dossiers zo moeilijk te delen zijn
Moderne geneeskunde leeft van data: hoe meer patiëntendossiers onderzoekers kunnen analyseren, hoe beter ze ziekten kunnen begrijpen en behandelingen kunnen verbeteren. Strikte privacyregels zorgen er echter voor dat veel van deze informatie gesloten blijft, zeker wanneer het gaat om gedetailleerde ziekenhuis- en biobankgegevens. Dit artikel introduceert een praktische methode om realistische “nep”-gezondheidsdatasets te maken die de privacy van individuen beschermen en tegelijk bruikbaar blijven voor onderzoek — mogelijk een veiliger pad naar gegevensdeling wereldwijd.
Vergrendelde dossiers omzetten in veilige dubbelgangers
De onderzoekers bouwden een end-to-end systeem dat gevoelige gezondheidsgegevens omzet in synthetische data — dossiers die statistisch gezien op het echte werk lijken, maar niet overeenkomen met een echt persoon. Hun raamwerk begint met zorgvuldig schoonmaken en organiseren van ziekenhuisjournalen, vragenlijsten, labtesten en kankerregistergegevens van meer dan 50.000 personen in Noord-Zweden. Een enkel configuratiebestand beschrijft welke variabelen bestaan, hoe ze behandeld moeten worden en welke privacygrenzen gelden, zodat elke stap transparant en reproduceerbaar is. Het systeem wordt verspreid als open-source software verpakt in een container, waardoor ziekenhuizen en onderzoekscentra het gemakkelijker kunnen inzetten zonder te worstelen met complexe installatie.
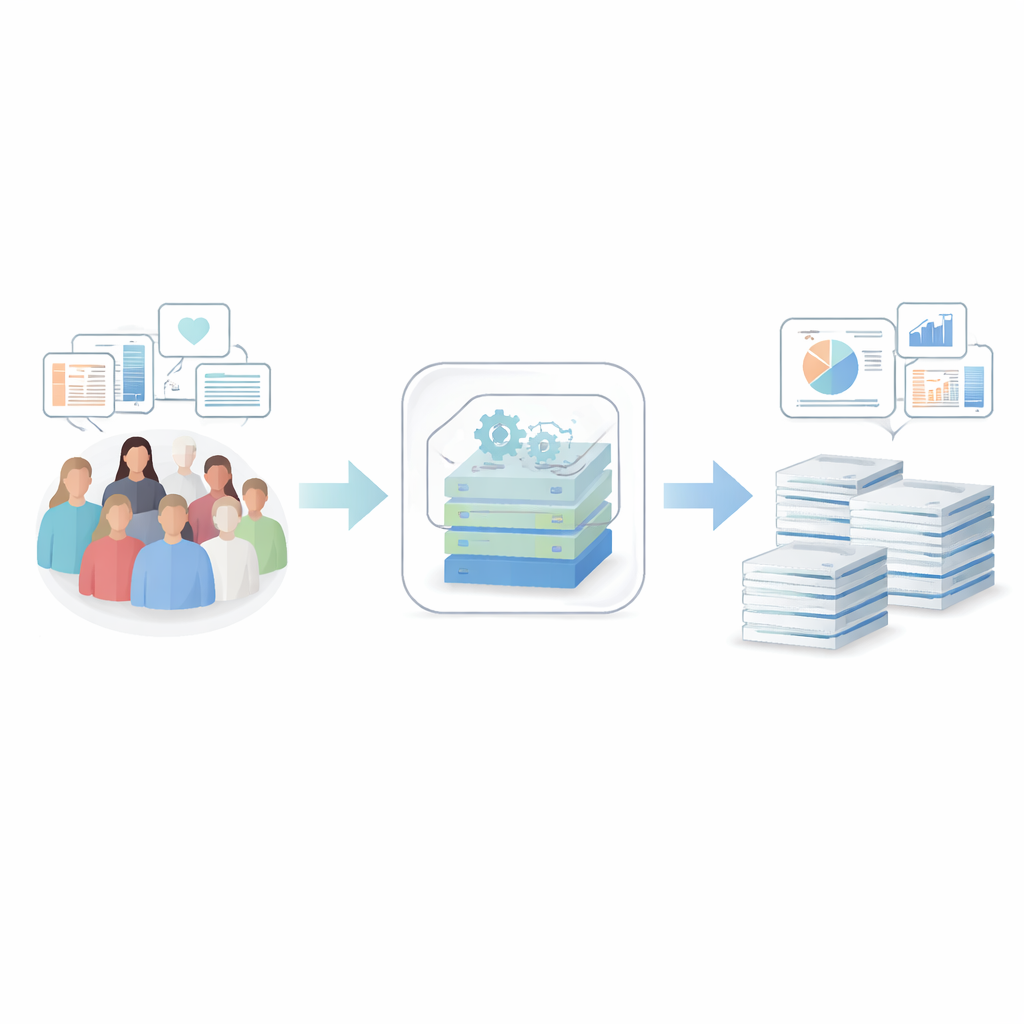
Hoe de synthetische datafabriek werkt
Wanneer de data zijn voorbereid, worden verschillende geavanceerde AI-modellen, waaronder diverse typen deep generative networks, getraind om de patronen in de echte datasets na te bootsen. Het opvallende model, TabSyn genoemd, is een transformer-gebaseerde diffusiemethode die oorspronkelijk ontwikkeld is voor complexe tabellen met getallen en categorieën. Het team breidt het uit met een speciale verliesfunctie, CorrDst, die het model expliciet beloont wanneer zowel de individuele distributies (bijvoorbeeld realistische leeftijds- of bloeddrukbereiken) als de relaties tussen variabelen (zoals de koppeling tussen gewicht en bodymass index) goed worden vastgelegd. Vervolgens gebruiken ze een geautomatiseerde zoekstrategie om modelinstellingen te verfijnen, zodat drie doelen gelijktijdig in balans zijn: nauwkeurigheid, bruikbaarheid voor downstream machine-learningtaken en privacybescherming.
Realistisch houden zonder de privacy te schenden
Om te beoordelen of de gegenereerde data goed genoeg zijn, evalueert het raamwerk elk model langs meerdere assen. Statistische tests vergelijken basale distributies en correlaties tussen echte en synthetische datasets. Machine-learningtests trainen voorspellingsmodellen op synthetische data en testen ze op de echte dossiers om te zien hoe goed kennis overgaat. Tegelijkertijd schatten formele en empirische privacycontroles in hoe waarschijnlijk het is dat een echt persoon kan worden gereïdentificeerd uit de synthetische data. De resultaten tonen aan dat TabSyn gecombineerd met CorrDst consequent beter presteert dan oudere generatieve benaderingen, vooral bij hoog-dimensionale kankerdatasets met veel ontbrekende waarden. Het behoudt belangrijke medische patronen — zoals sekse-specifieke kankers en verbanden tussen roken en longziekten — zonder onwaarschijnlijke extremen te produceren, en dat binnen redelijke rekentijden.
Rommelige medische data bruikbaar maken
Een groot obstakel in gezondheidsonderzoek is dat real-world data rommelig zijn: veel labuitslagen ontbreken, meetmomenten variëren en sommige variabelen moeten strikte biologische regels volgen. De auteurs ontwerpen een op maat gemaakte preprocessing-pijplijn die ontbrekende waarden op een gestructureerde manier imput, scheve numerieke variabelen herschikt naar stabielere vormen en indicatoren toevoegt die expliciet aangeven waar data ontbraken. Deze aanpak vermindert scherp de artefacten die eenvoudiger methoden teisteren, zoals onmogelijke combinaties van leeftijd, gewicht en bodymass index. Na het genereren gebruikt een kwaliteitscontroletap zowel geautomatiseerde checks als deskundige inspectie om synthetische records te verwerpen die medische logica schenden (bijvoorbeeld prostaatkanker toegewezen aan vrouwen).
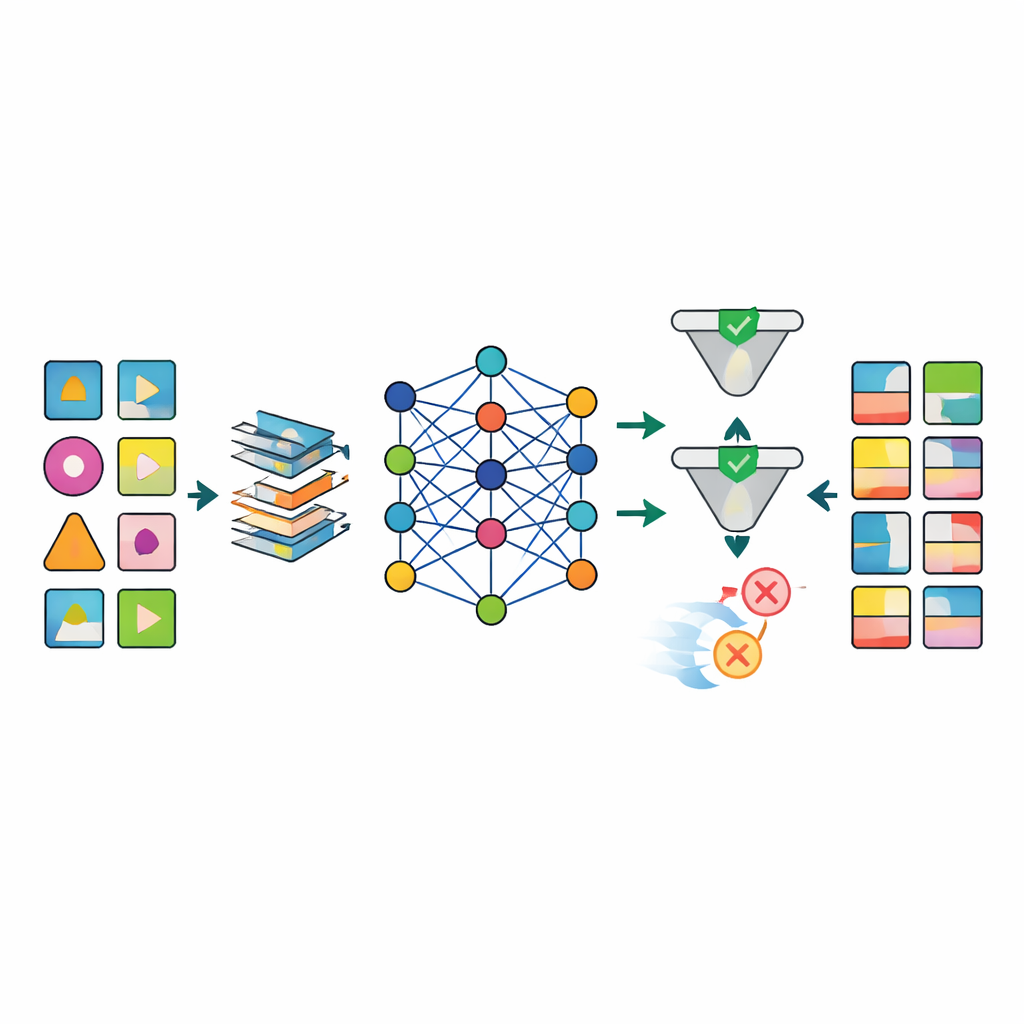
De data zien zonder de personen te zien
Buiten het genereren bouwt het team een interactieve visualisatietool waarmee onderzoekers cohorteigenschappen kunnen verkennen — zoals hoeveel mensen zowel longkanker als obesitas hebben, uitgesplitst naar leeftijd en geslacht — terwijl ze waakzaam blijven voor privacylekken. Een adaptief anonimisationalgoritme gebaseerd op k-anonimiteit maakt filters dynamisch grover of verwijdert ze zodat geen enkele combinatie van instellingen ooit minder dan tien individuen onthult. Dit maakt haalbaarheidscontroles en hypothesegeneratie op rijke gezondheidsdata mogelijk zonder gevoelige details over één persoon bloot te geven.
Wat dit betekent voor patiënten en onderzoekers
Simpel gezegd laat het artikel zien dat het nu mogelijk is om op grote schaal realistische, privacybeschermende stand-ins voor gedetailleerde medische dossiers te produceren. Door slimme preprocessing, een hoogpresterend generatief model, rigoureuze privacytests en menselijke kwaliteitscontrole te combineren, levert het raamwerk synthetische datasets die zich in analyses gedragen als de originelen maar veel veiliger zijn om te delen. Als deze tools breed worden toegepast, zouden ze enorme biobankbronnen kunnen ontsluiten voor samenwerking, studies naar zeldzame ziekten met beperkte patiëntenaantallen kunnen verbeteren en helpen voldoen aan wettelijke eisen zonder wetenschappelijke vooruitgang op te offeren.
Bronvermelding: Vu, M.H., Edler, D., Wibom, C. et al. Anonymization and visualization of health data and biomarkers. npj Digit. Med. 9, 347 (2026). https://doi.org/10.1038/s41746-026-02662-x
Trefwoorden: synthetische gezondheidsgegevens, patiëntprivacy, biobankonderzoek, differentiële privacy, medische AI