Clear Sky Science · zh
用于临床决策任务的大型语言模型代理系统基准研究
更聪明的医疗 AI,但代价是什么?
人工智能越来越多地被期望帮助医生梳理复杂信息并做出更优决策。一项新研究提出了一个简单却至关重要的问题:当今最先进的“具代理性”的 AI 系统——设计用来逐步推理并使用在线工具——在现实风格的医学任务中,是否确实优于标准聊天机器人?它们是否值得为之付出更多时间和计算资源?
从简单聊天机器人到可执行任务的代理
大多数人将大型语言模型视为一次性回答问题的聊天机器人。具代理性的系统在这些模型基础上扩展,将其变为能够制定计划、调用外部工具(如网页浏览器或代码运行器)并协调多个专门子代理的数字“工作者”。在本研究中,研究者比较了两种这样的代理系统——Manus 及其开源同类 OpenManus——与主要 AI 实验室的领先语言模型。所有系统都接受了三类测试:在多轮对话中展开的模拟医患就诊、极为困难的医学考试与教科书问题,以及混合文本与图像的挑战,比如在病例描述的同时解读临床照片。
这些代理的实际表现如何?
在这些基准测试中,代理系统确实比其所基于的语言模型略有领先,但差距很小。在模拟诊断对话中,将 OpenManus 调整为表现得像医师助理并更积极使用工具,使其准确率较基础模型提高了约 7–9 个百分点。在一组要求高、知识密集的复杂问题上,OpenManus 再次略优于其骨干模型,并与顶级专有系统大致相当。然而绝对分数仍然有限:在一些旨在避免走捷径的最难医学问题上,即便是表现最好的代理,答对率也不到十分之一,远低于能在临床中无需监督使用的水平。
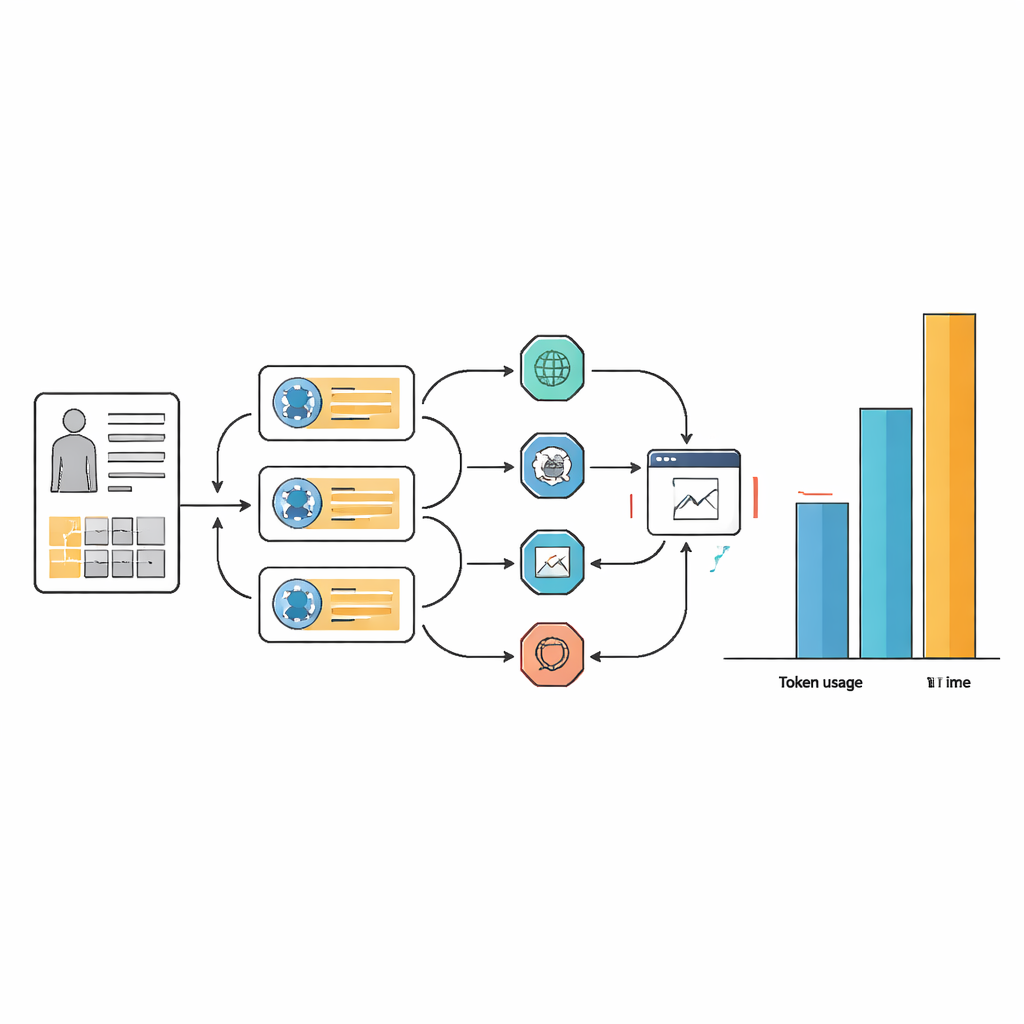
隐含代价:时间、复杂性与计算量
这些微小的准确度提升伴随着资源和工作流复杂性的高昂代价。在许多任务中,代理系统使用的文本 token 数是基础语言模型的 10 到 100 倍,响应时间通常也超过两倍。这种开销源自代理反复进行计划、网络检索、信息提取并重新考虑答案的工作方式。虽然精心设计的提示使代理工作流更精简并在工具选择上更一致,但并未消除需要多次内部步骤的本质。实际而言,每个病例都要耗费超过一分钟并需要大量计算资源的 AI 助手,在繁忙的医院或资源有限的环境中很难令人信服。
虚构细节的问题
另一个关注点是幻觉——当 AI 自信地编造未提供的患者症状或检验结果时。研究者发现几乎每个由代理处理的病例都包含某些幻觉,尤其是杜撰的患者陈述或检验数值。研究组加入了安全层来后处理代理输出,改写提示以阻止猜测,并提供正确行为的示例。这些干预几乎阻止了近 90% 的幻觉内容,并将幻觉影响最终诊断的病例比例降低到约三分之一。有趣的是,含有与不含幻觉的病例在总体准确率上并无明显差异,可能是因为虚构细节有时会触发额外的核查步骤,从而纠正最初的错误。
这对未来临床 AI 意味着什么
对非专业读者而言,结论是:当今更复杂的医学 AI 代理并不是对强大聊天机器人的魔法式升级。通过分步推理并使用在线工具,它们可以被引导取得略微更好的表现,但其当前准确性仍然偏低,对时间和计算资源的需求又过高,无法在没有严格人工监督的情况下常规用于临床。研究认为,进展的方向不仅应是将分数稍微推高,更应致力于让系统更快、资源占用更少、减少编造信息并更好地基于真实患者数据。只有在这些方面取得改进后,具代理性的 AI 才能准备好在日常医疗中安全可靠地协助临床人员。
引用: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
关键词: 临床人工智能, 大型语言模型, 医学决策支持, AI 代理, 医疗基准测试