Clear Sky Science · en
Benchmarking large language model-based agent systems for clinical decision tasks
Smarter Medical AI, But At What Cost?
Artificial intelligence is increasingly being asked to help doctors sort through complex information and make better decisions. A new study asks a simple but vital question: do today’s most advanced “agentic” AI systems—designed to reason step by step and use online tools—actually perform better than standard chatbots in real-world style medical tasks, and are they worth the extra time and computing power they require?
From Simple Chatbots to Task-Running Agents
Most people know large language models as chatbots that answer questions in a single pass. Agentic systems build on these models by turning them into digital workers that can plan, call external tools like web browsers or code runners, and coordinate several specialized sub-agents. In this study, researchers compared two such agent systems—Manus and its open-source cousin OpenManus—with leading language models from major AI labs. All systems tackled three families of tests: simulated doctor–patient visits that unfold over many conversational turns, extremely difficult medical exam and textbook questions, and mixed text-and-image challenges such as interpreting clinical photos alongside case descriptions.
How Well Did the Agents Actually Do?
Across these benchmarks, the agent systems did edge out their underlying language models, but only slightly. In simulated diagnostic conversations, tuning OpenManus to behave like a physician’s assistant and to use tools more actively increased its accuracy by about 7–9 percentage points compared with its base model. On a demanding set of complex, knowledge-heavy questions, OpenManus again performed somewhat better than its backbone model and roughly on par with top proprietary systems. Yet absolute scores stayed modest: on some of the hardest medical questions designed to defeat shortcuts, even the best agents answered fewer than one in ten correctly, far below what would be needed for unsupervised use in clinics.
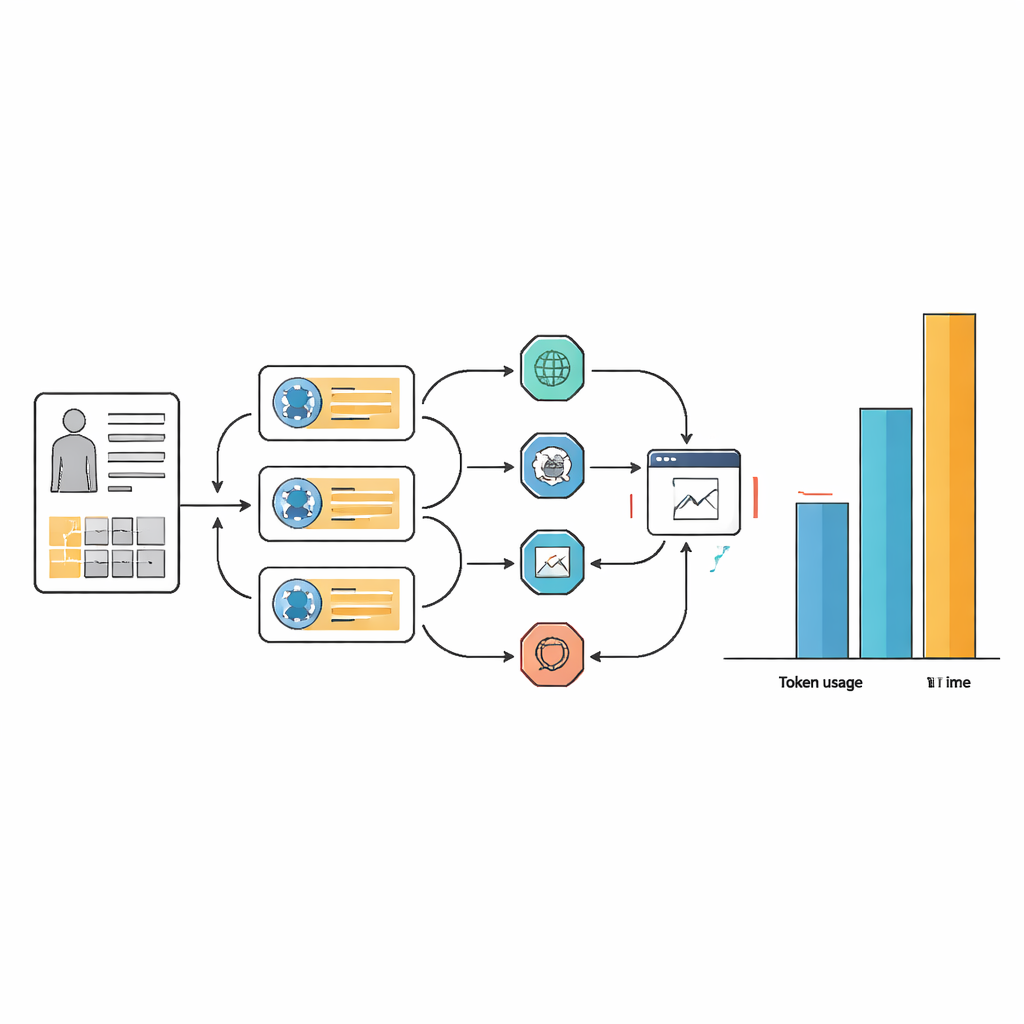
The Hidden Price: Time, Complexity, and Compute
Those small gains in accuracy came at a steep cost in resources and workflow complexity. For many tasks, the agent systems used 10 to 100 times more text tokens than the underlying language model alone, and often took more than twice as long to respond. This overhead stems from the way agents repeatedly loop through planning, searching the web, extracting information, and reconsidering their answers. While careful prompt design made agent workflows more streamlined and consistent in their choice of tools, it did not remove the basic need for many internal steps. In practical terms, an AI assistant that takes over a minute and huge computing power per case may be hard to justify in busy hospitals or resource-limited settings.
The Problem of Made-Up Details
Another concern was hallucination—when an AI confidently invents patient symptoms or lab results that were never provided. The researchers found that almost every agent-run case contained some hallucinations, especially fabricated patient statements or test values. They added safety layers that post-processed the agents’ output, rewrote prompts to discourage guessing, and provided examples of correct behavior. These interventions blocked nearly 90% of hallucinated content and reduced the fraction of cases where hallucinations affected the final diagnosis to about one third. Interestingly, there was no clear difference in overall accuracy between cases with and without hallucinations, perhaps because invented details sometimes triggered additional checking steps that corrected initial errors.
What This Means for Future AI in Clinics
For non-specialists, the takeaway is that today’s more elaborate medical AI agents are not magic upgrades over strong chatbots. They can be nudged to do somewhat better by reasoning in stages and using online tools, but their current accuracy is still too low, and their appetite for time and computing power is too high, for routine clinical use without close human supervision. The study argues that progress should focus not only on pushing scores slightly higher, but also on making systems faster, less resource-hungry, less prone to making things up, and better grounded in real patient data. Only then will agentic AI be ready to safely and reliably assist clinicians in everyday care.
Citation: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
Keywords: clinical AI, large language models, medical decision support, AI agents, healthcare benchmarking