Clear Sky Science · he
השוואת מערכות סוכנים מבוססות מודלי שפה גדולים למשימות החלטה קליניות
בינה רפואית חכמה יותר — אך במחיר מה?
בינה מלאכותית נתבקשת יותר ויותר לסייע לרופאים למיין מידע מורכב ולקבל החלטות טובות יותר. מחקר חדש שואל שאלה פשוטה אך חיונית: האם מערכות ה"סוכניות" המתקדמות של היום — שנועדו להסיק מסקנות בשלבים ולהשתמש בכלים מקוונים — אכן עובדות טוב יותר מצ'אטבוטים סטנדרטיים במשימות רפואיות בסגנון העולם האמיתי, והאם הן שוות את הזמן והעיבוד הנוספים שהן דורשות?
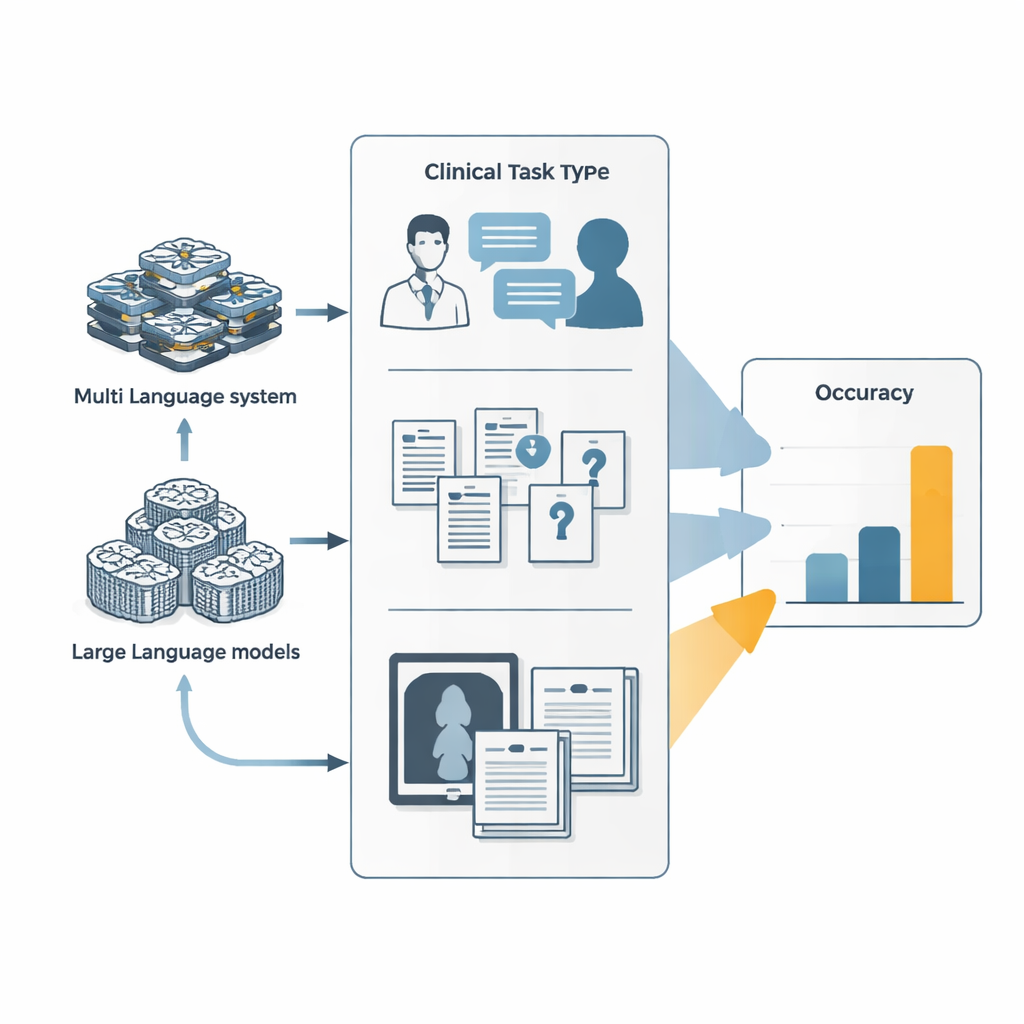
מצ'אטבוטים פשוטים לסוכנים שמריצים מטלות
רוב האנשים מכירים מודלי שפה גדולים כצ'אטבוטים שעונים על שאלות במעבר יחיד. מערכות סוכניות בונות על מודלים אלה על ידי הפיכתם לעובדים דיגיטליים שיכולים לתכנן, לקרוא לכלים חיצוניים כמו דפדפני אינטרנט או מריצי קוד, ולתאם כמה תת־סוכנים מתמחים. במחקר זה השוו החוקרים שתי מערכות סוכניות כאלו — Manus וגרסתה בקוד פתוח OpenManus — מול מודלי שפה בולטים ממעבדות AI מרכזיות. כל המערכות התמודדו עם שלוש משפחות מבחנים: ביקורים מדומים בין רופא לחולה המתפתחים על פני סבבים רבים של שיחה, שאלות קשה מאוד מתוך בחינות רפואיות וספרי לימוד, ואתגרים מעורבים של טקסט ותמונה כגון פרשנות של תמונות קליניות לצד תיאור מקרה.
כמה טובים היו הסוכנים בפועל?
בכל הבחנים הללו, מערכות הסוכנים עלו במעט על מודלי היסוד שלהן, אך רק במידה מועטה. בשיחות אבחוניות מדומות, כוונון OpenManus כדי להתנהג כעוזר רופא ולהשתמש בכלים באופן פעיל העלה את הדיוק שלו בכ־7–9 נקודות אחוז יחסית למודל הבסיס. במערך תובעני של שאלות מורכבות ועשירות בידע, OpenManus שוב הציג ביצועים מעט טובים יותר ממודל היסוד שלו ובקירוב שווה למערכות קנייניות מובילות. עם זאת, הציונים האבסולוטיים נותרו צנועים: בחלק מהשאלות הקשות ביותר, שנועדו למנוע קיצורי דרך, אפילו הסוכנים הטובים ביותר ענו נכון בפחות מאחת מכל עשר, רחוק ממה שנדרש לשימוש בלתי מפוקח במרפאות.
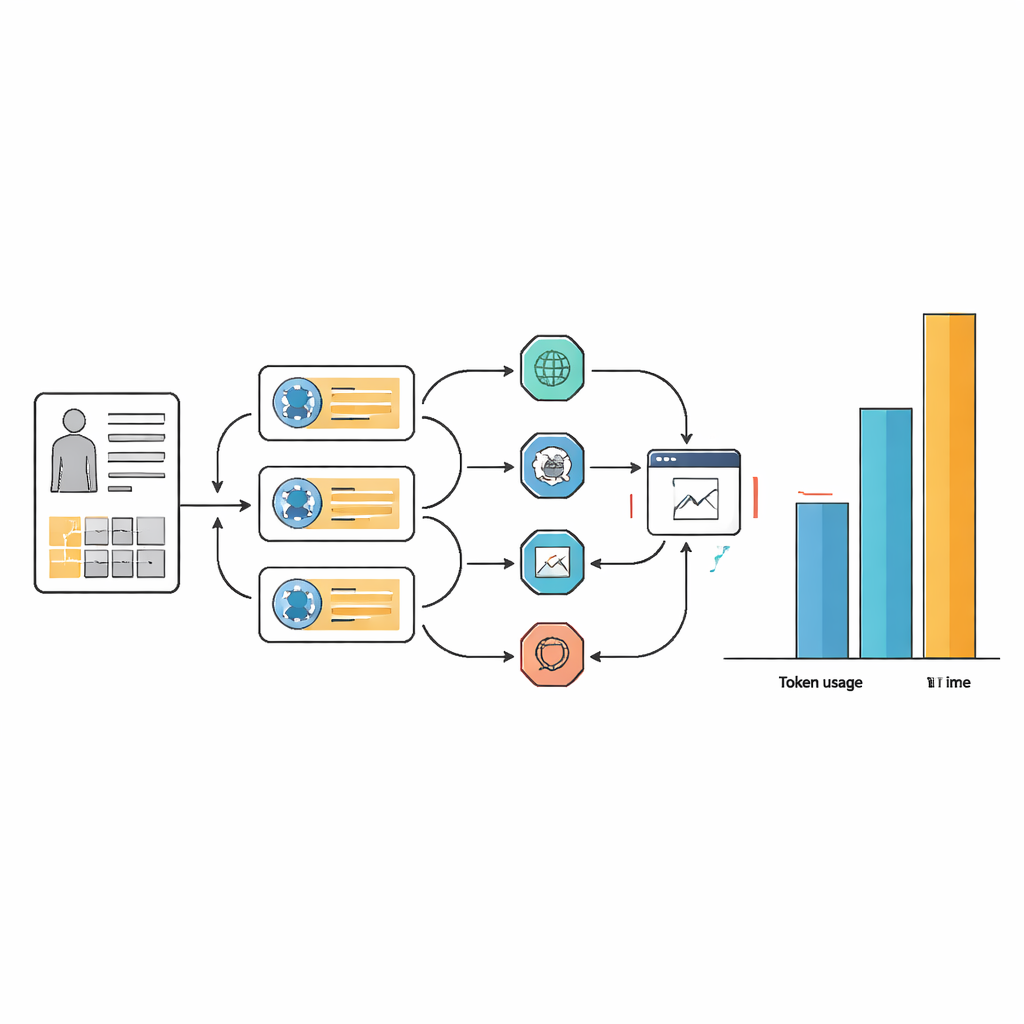
המחיר הנסתר: זמן, מורכבות וחישוב
אותן רווחים קטנים בדיוק באו במחיר כבד במשאבים ובמורכבות של זרימת העבודה. למשימות רבות השתמשו מערכות הסוכנים פי 10 עד 100 יותר טוקנים של טקסט מאשר המודל הבסיסי לבדו, ולעתים לקחו יותר מפעמיים זמן תגובה. הנטל הזה נובע מהאופן שבו סוכנים חוזרים באופן מחזורי על שלבי תכנון, חיפוש אינטרנטי, חילוץ מידע ושיקול מחודש של התשובות. בעוד עיצוב פרומפטים קפדני הפך את זרימות העבודה של הסוכנים ליותר חלקות ועקביות בבחירת הכלים, הוא לא ביטל את הצורך הבסיסי במספר רב של שלבים פנימיים. במונחים מעשיים, עוזר בינה מלאכותית שלוקח מעל דקה ומשאבי מחשוב עצומים לכל מקרה עלול להיות קשה להצדקה בבתי חולים עמוסים או בהקשרים עם משאבים מוגבלים.
בעיית הפרטים המצוצים מהאוויר
חשש נוסף היה הזיית מידע — כאשר ה-AI ממציא בביטחון תסמינים של חולה או תוצאות בדיקה שלא סופקו מעולם. החוקרים מצאו שכמעט בכל מקרה שהופעל על ידי סוכן היה גונב־מידע כלשהו, במיוחד הצהרות מפוברקות של חולים או ערכי בדיקות. הם הוסיפו שכבות בטיחות שעיבדו את פלט הסוכנים לאחר מכן, שינו פרומפטים כדי להמעיט בניחושים וסיפקו דוגמאות להתנהגות נכונה. התערבויות אלו חסמו כמעט 90% מהתוכן המהוזה והקטינו את השיעור של מקרים שבהם הזיות השפיעו על האבחנה הסופית לכדי כשליש. מעניין שאין הבדל ברור בדיוק הכללי בין מקרים עם הזיות וללא, אולי כי פרטים מומצאים לעתים עוררו שלבי בדיקה נוספים שתיקנו שגיאות ראשוניות.
מה משמעות הדבר לעתיד ה-AI במרפאות?
ללא־מומחים, המסקנה היא שמערכות ה-AI הרפואיות המורכבות יותר של היום אינן שדרוג קסום על פני צ'אטבוטים חזקים. אפשר לדחוף אותן לבצע טוב יותר במידה מסוימת על ידי חשיבה בשלבים ושימוש בכלים מקוונים, אבל הדיוק הנוכחי שלהן עדיין נמוך מדי, ותיאבןן לזמן ולעיבוד גבוהה מדי לשימוש שגרתי בלי השגחה צמודה של בני־אדם. המחקר טוען שההתקדמות צריכה להתמקד לא רק בהעלאת הציונים במעט, אלא גם בהפיכת המערכות למהירות יותר, חסכוניות במשאבים, פחות נוטות להמציא פרטים וטובות יותר בעיגון בנתוני חולים אמיתיים. רק אז תהיה ל-AI סוכני באמת מוכנה לסייע בבטחה ובמהימנות לרופאים בטיפול היומיומי.
ציטוט: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
מילות מפתח: בינה מלאכותית קלינית, מודלי שפה גדולים, תמיכה בהחלטות רפואיות, סוכני בינה מלאכותית, השוואת ביצועים במערכת הבריאות