Clear Sky Science · pt
Benchmarking de sistemas agentes baseados em grandes modelos de linguagem para tarefas de decisão clínica
IA médica mais inteligente — mas a que custo?
A inteligência artificial vem sendo cada vez mais solicitada para ajudar médicos a processar informações complexas e tomar decisões melhores. Um novo estudo faz uma pergunta simples, porém vital: os sistemas de IA “agentivos” mais avançados de hoje — projetados para raciocinar passo a passo e usar ferramentas online — realmente desempenham melhor do que chatbots padrão em tarefas médicas no estilo do mundo real, e valem o tempo e o poder de computação adicionais que exigem?
De chatbots simples a agentes que executam tarefas
A maioria das pessoas conhece os grandes modelos de linguagem como chatbots que respondem perguntas em uma única passada. Sistemas agentivos ampliam esses modelos, transformando-os em trabalhadores digitais que podem planejar, chamar ferramentas externas como navegadores web ou ambientes de execução de código e coordenar vários subagentes especializados. Neste estudo, os pesquisadores compararam dois desses sistemas agentes — Manus e seu equivalente open-source OpenManus — com modelos de linguagem de ponta de grandes laboratórios de IA. Todos os sistemas enfrentaram três famílias de testes: simulações de consultas médico–paciente que se desenvolvem por várias trocas conversacionais, questões de exame médico e de livro didático extremamente difíceis, e desafios mistos de texto e imagem, como interpretar fotos clínicas junto a descrições de casos.
Quão bem os agentes realmente se saíram?
Ao longo desses benchmarks, os sistemas agentes superaram seus modelos de linguagem subjacentes, mas apenas ligeiramente. Em conversas diagnósticas simuladas, ajustar o OpenManus para agir como assistente de médico e usar ferramentas de forma mais ativa aumentou sua precisão em cerca de 7–9 pontos percentuais em comparação com seu modelo base. Em um conjunto exigente de perguntas complexas e ricas em conhecimento, o OpenManus novamente teve desempenho um pouco melhor que seu modelo base e aproximadamente no mesmo nível dos principais sistemas proprietários. Ainda assim, as pontuações absolutas permaneceram modestas: em algumas das perguntas médicas mais difíceis, projetadas para vencer atalhos, até os melhores agentes acertaram menos de uma em dez, bem abaixo do necessário para uso não supervisionado em clínicas.
O preço oculto: tempo, complexidade e custo computacional
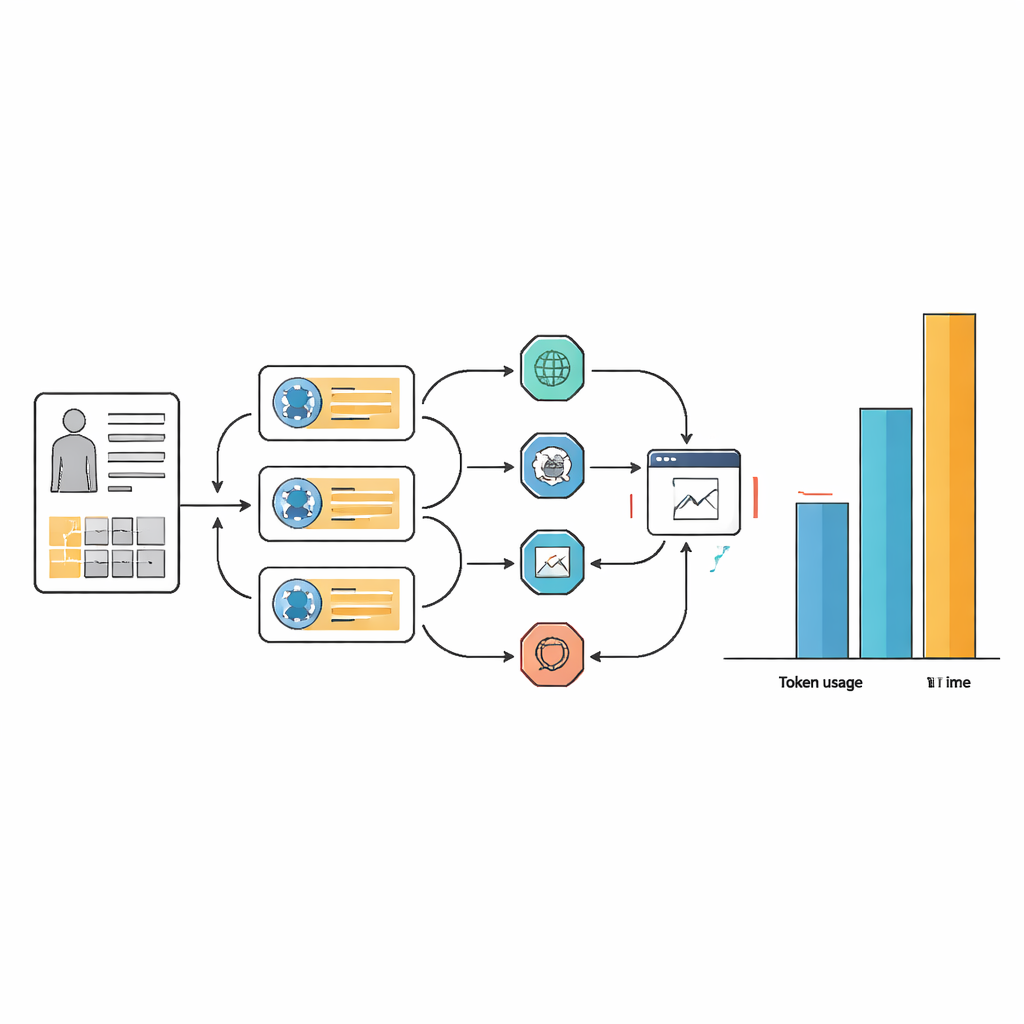
Esses pequenos ganhos em precisão vieram com um custo elevado em recursos e complexidade de fluxo de trabalho. Em muitas tarefas, os sistemas agentes utilizaram de 10 a 100 vezes mais tokens de texto do que o modelo de linguagem subjacente sozinho e frequentemente demoraram mais do que o dobro para responder. Essa sobrecarga decorre do modo como os agentes repetidamente passam por ciclos de planejamento, busca na web, extração de informação e reavaliação de respostas. Embora um design cuidadoso de prompts tenha tornado os fluxos de trabalho dos agentes mais enxutos e consistentes na escolha de ferramentas, isso não eliminou a necessidade básica de muitos passos internos. Em termos práticos, um assistente de IA que leva mais de um minuto e exige grande poder computacional por caso pode ser difícil de justificar em hospitais movimentados ou em cenários com recursos limitados.
O problema dos detalhes inventados
Outra preocupação foi a alucinação — quando uma IA inventa com confiança sintomas de paciente ou resultados de exames que nunca foram fornecidos. Os pesquisadores constataram que quase todos os casos executados pelos agentes continham alguma alucinação, especialmente declarações de pacientes ou valores de testes fabricados. Eles adicionaram camadas de segurança que pós-processavam a saída dos agentes, reescreveram prompts para desencorajar conjecturas e forneceram exemplos de comportamento correto. Essas intervenções bloquearam quase 90% do conteúdo alucinado e reduziram a fração de casos em que alucinações afetaram o diagnóstico final para cerca de um terço. Curiosamente, não houve diferença clara na precisão geral entre casos com e sem alucinações, talvez porque detalhes inventados às vezes desencadeavam checagens adicionais que corrigiam erros iniciais.
O que isso significa para o futuro da IA em clínicas
Para não especialistas, a conclusão é que os agentes médicos mais elaborados de hoje não são atualizações milagrosas em relação a chatbots robustos. Eles podem ser ajustados para ter desempenho um pouco melhor ao raciocinar em etapas e usar ferramentas online, mas sua precisão atual ainda é baixa demais, e seu apetite por tempo e computação é alto demais, para uso clínico rotineiro sem supervisão humana próxima. O estudo argumenta que o progresso deve focar não apenas em elevar ligeiramente as pontuações, mas também em tornar os sistemas mais rápidos, menos dependentes de recursos, menos propensos a inventar informações e melhor ancorados em dados reais de pacientes. Só então a IA agentiva estará pronta para auxiliar clinicamente, de forma segura e confiável, no cuidado diário.
Citação: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
Palavras-chave: IA clínica, grandes modelos de linguagem, suporte à decisão médica, agentes de IA, benchmarking em saúde