Clear Sky Science · tr
Büyük dil modeli tabanlı ajan sistemlerini klinik karar görevleri için karşılaştırma
Daha Akıllı Tıbbi Yapay Zeka, Ama Hangi Bedelle?
Yapay zeka, doktorların karmaşık bilgileri değerlendirmesine ve daha iyi kararlar almasına yardımcı olmaları için giderek daha fazla talep görüyor. Yeni bir çalışma, basit ama hayati bir soruyu gündeme getiriyor: Bugünün en gelişmiş “ajan” yapay zeka sistemleri—adım adım akıl yürütme ve çevrimiçi araçları kullanma üzere tasarlanmış olanlar—gerçek dünyaya yakın tıbbi görevlerde standart sohbet botlarından gerçekten daha iyi performans gösteriyor mu ve gerektirdikleri ek zaman ve hesaplama gücüne değiyorlar mı?
Basit Sohbet Botlarından Görev Yürüten Ajanlara
Çoğu kişinin büyük dil modellerini tek geçişte soruları yanıtlayan sohbet botları olarak bildiği doğru. Ajanik sistemler, bu modelleri plan yapabilen, web tarayıcıları veya kod çalıştırıcılar gibi harici araçları çağırabilen ve birkaç uzman alt ajanın koordinasyonunu sağlayabilen dijital işçilere dönüştürerek üzerine inşa edilir. Bu çalışmada araştırmacılar, Manus ve açık kaynak kuzeni OpenManus olmak üzere iki ajan sistemini büyük AI laboratuvarlarının önde gelen dil modelleriyle karşılaştırdı. Tüm sistemler üç aile teste tabi tutuldu: çok tur boyunca gelişen simüle edilmiş doktor–hasta görüşmeleri, son derece zorlu tıbbi sınav ve ders kitabı soruları ile olgu açıklamalarıyla birlikte klinik fotoğrafları yorumlamayı içeren metin ve görsel karışık zorluklar.
Ajanlar Gerçekte Ne Kadar İyiydiler?
Bu kıstaslar genelinde, ajan sistemleri temel dil modellerinin önüne ufak bir farkla geçti, ancak sadece sınırlı ölçüde. Simüle edilmiş tanısal konuşmalarda, OpenManus’u bir hekim asistanı gibi davranacak ve araçları daha aktif kullanacak şekilde ayarlamak, temel modele kıyasla doğruluğu yaklaşık %7–9 puan artırdı. Bilgi yoğun, zorlu bir soru setinde OpenManus yine omurga modeliyle kıyaslandığında biraz daha iyi performans gösterdi ve önde gelen tescilli sistemlerle yaklaşık olarak benzer düzeydeydi. Yine de mutlak puanlar mütevazi kaldı: kestirme yolları boşa çıkaracak şekilde tasarlanmış en zor tıbbi sorularda bile en iyi ajanlar doğru yanıtları onda birden az verdi; bu, kliniklerde denetimsiz kullanım için gereken düzeyin çok altında.
Gizli Bedel: Zaman, Karmaşıklık ve Hesaplama
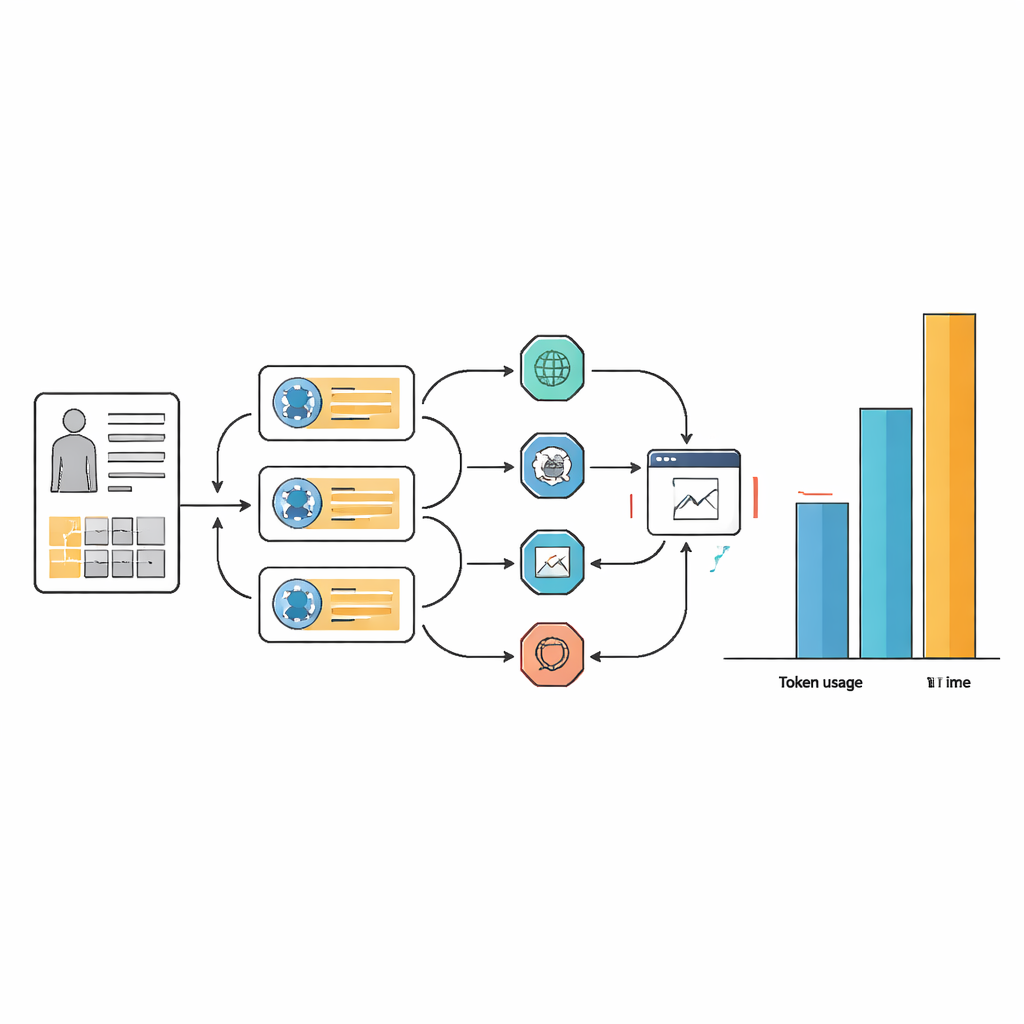
Bu küçük doğruluk artışları, kaynaklar ve iş akışı karmaşıklığı bakımından yüksek bir maliyetle geldi. Birçok görevde ajan sistemleri, yalnızca temel dil modelinin kullandığı metin token’larının 10 ila 100 katını kullandı ve genellikle yanıt vermesi iki kattan fazla sürdü. Bu ek yük, ajanların planlama, web araması, bilgi çıkarma ve yanıtlarını yeniden değerlendirme döngülerini tekrarlama biçiminden kaynaklanıyor. Titiz istem tasarımı (prompt engineering) ajan iş akışlarını daha düzenli ve kullandıkları araçlar açısından tutarlı hale getirse de, birçok iç adım gereksinimini ortadan kaldırmadı. Pratik açıdan, vakada bir dakikadan uzun süren ve büyük hesaplama gücü gerektiren bir yapay zeka asistanı, yoğun hastanelerde veya kaynak kısıtlı ortamlarda haklı çıkarılması zor olabilir.
Uydurulmuş Detaylar Sorunu
Diğer bir endişe de halüsinasyon—yani bir yapay zekanın kendinden emin bir şekilde sağlanmamış hasta semptomları veya laboratuvar sonuçları uydurması. Araştırmacılar, neredeyse her ajan yürütmeli vakada bazı halüsinasyonlar bulunduğunu, özellikle üretilmiş hasta beyanları veya test değerleri olduğunu saptadı. Çıktıları son işlemden geçiren güvenlik katmanları eklediler, tahminleri caydırmak için istemleri yeniden yazdılar ve doğru davranış örnekleri sundular. Bu müdahaleler, uydurulmuş içeriğin yaklaşık %90’ını engelledi ve halüsinasyonların nihai tanıyı etkilediği vaka oranını yaklaşık üçte bire düşürdü. İlginç olarak, halüsinasyonlu ve halüsinasyonsuz vakalar arasında genel doğrulukta belirgin bir fark yoktu; bunun nedeni bazen uydurulan detayların ek kontrol adımlarını tetiklemesi ve ilk hataları düzeltmesi olabilir.
Bu, Kliniklerdeki Gelecek Yapay Zeka İçin Ne Anlama Geliyor?
Uzman olmayanlar için çıkarım şu: Bugünün daha ayrıntılı tıbbi yapay zeka ajanları güçlü sohbet botlarına göre sihirli bir yükseltme sunmuyor. Aşamalar halinde akıl yürütme ve çevrimiçi araç kullanımıyla biraz daha iyi performans göstermeleri sağlanabiliyor, ancak mevcut doğrulukları hâlâ çok düşük ve zaman ile hesaplama açlıkları rutin klinik kullanım için, yakın insan denetimi olmadan, çok yüksek. Çalışma, ilerlemenin sadece puanları biraz daha yükseltmeye değil, aynı zamanda sistemleri daha hızlı, daha az kaynak tüketen, uydurma eğilimi daha az olan ve gerçek hasta verileriyle daha iyi temellendirilmiş hâle getirmeye odaklanması gerektiğini savunuyor. Ancak o zaman ajanik yapay zeka, klinisyenlere günlük bakımda güvenli ve güvenilir şekilde yardımcı olmaya hazır olacaktır.
Atıf: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
Anahtar kelimeler: klinik yapay zeka, büyük dil modelleri, tıbbi karar desteği, yapay zeka ajanları, sağlık hizmetlerinde kıyaslama