Clear Sky Science · ru
Оценка агентных систем на базе больших языковых моделей для клинических задач принятия решений
Более умный медицинский ИИ — но какой цене?
Искусственный интеллект всё чаще привлекают, чтобы помогать врачам разбирать сложную информацию и принимать более обоснованные решения. Новое исследование задаёт простой, но важный вопрос: действительно ли современные «агентные» ИИ-системы — разработанные для пошагового рассуждения и использования онлайн-инструментов — работают лучше обычных чат-ботов в задачах, приближённых к реальной клинической практике, и оправдывают ли они дополнительные затраты времени и вычислительных ресурсов?
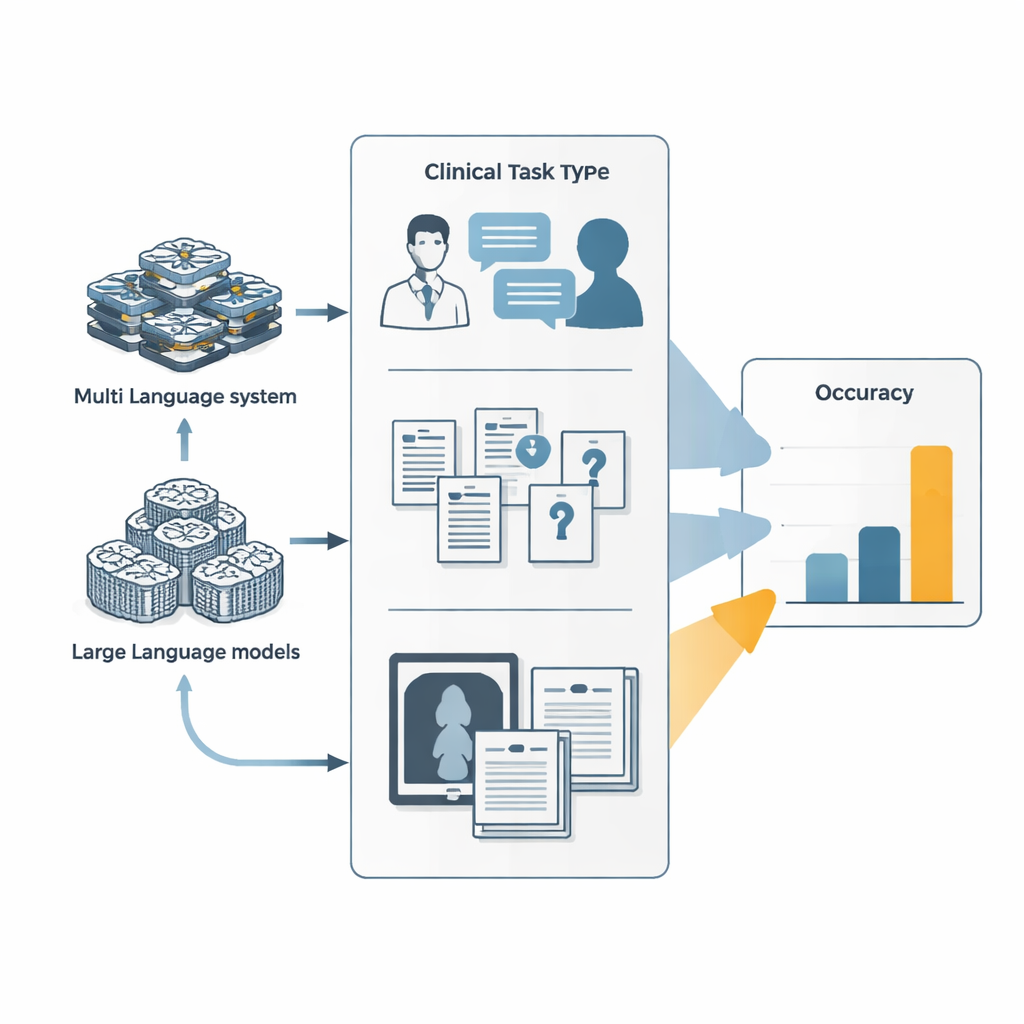
От простых чат-ботов к агентам, выполняющим задачи
Большинство знакомо с большими языковыми моделями как с чат-ботами, отвечающими на вопросы в один проход. Агентные системы развивают эти модели, превращая их в цифровых исполнителей, которые могут планировать, вызывать внешние инструменты — например браузеры или среды выполнения кода — и координировать нескольких специализированных подагентов. В этом исследовании авторы сравнили две такие агентные системы — Manus и её открытое воплощение OpenManus — с ведущими языковыми моделями крупных лабораторий. Все системы проходили три набора тестов: смоделированные визиты врач–пациент, развивающиеся в несколько раундов беседы; крайне сложные вопросы из медицинских экзаменов и учебников; и смешанные задачи с текстом и изображениями, например интерпретация клинических фото вместе с описанием случая.
Насколько хорошо агенты справились на самом деле?
По этим бенчмаркам агентные системы действительно немного превосходили свои базовые языковые модели, но лишь незначительно. В симулированных диагностических беседах настройка OpenManus на поведение ассистента врача и более активное использование инструментов повысила её точность примерно на 7–9 процентных пунктов по сравнению с базовой моделью. В наборе сложных вопросов, требующих глубоких знаний, OpenManus снова выступила лучше своей базовой модели и примерно на уровне лучших проприетарных систем. Однако абсолютные показатели оставались скромными: на некоторых из самых трудных медицинских вопросов, спроектированных для обхода упрощений, даже лучшие агенты отвечали правильно менее чем на один из десяти, что далеко от требований для автономного использования в клиниках.
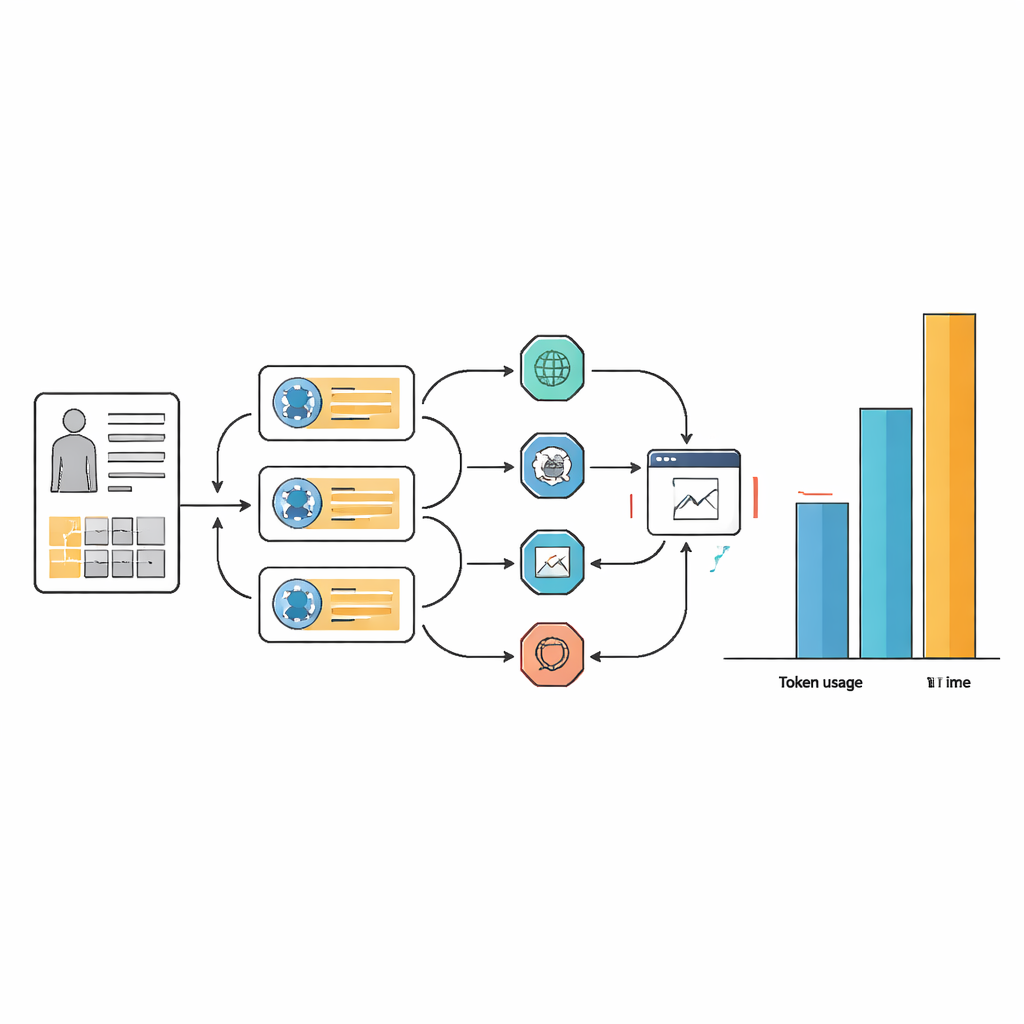
Скрытая плата: время, сложность и вычислительные ресурсы
Эти небольшие приращения точности потребовали значительных затрат ресурсов и усложнили рабочие процессы. Для многих задач агентные системы использовали в 10–100 раз больше текстовых токенов, чем сама базовая модель, а часто отвечали более чем вдвое медленнее. Такое увеличение обусловлено тем, что агенты многократно проходят циклы планирования, поиска в сети, извлечения информации и переосмысления ответов. Хотя тщательная проработка подсказок сделала рабочие процессы агентов более оптимизированными и последовательными в выборе инструментов, это не устранило базовой потребности в многочисленных внутренних шагах. Практически это означает, что помощник ИИ, требующий больше минуты и больших вычислительных затрат на каждый случай, вряд ли будет оправдан в загруженных больницах или при ограниченных ресурсах.
Проблема выдуманных деталей
Ещё одна проблема — галлюцинации, когда ИИ уверенно выдумывает симптомы пациента или результаты анализов, которые не были предоставлены. Исследователи обнаружили, что почти в каждом случае, обработанном агентом, встречались какие‑то выдумки, особенно сфабрикованные высказывания пациентов или значения тестов. Они добавили слои безопасности, которые постобрабатывали вывод агентов, переписывали подсказки, чтобы снижать склонность к догадкам, и приводили примеры корректного поведения. Эти меры блокировали почти 90% выдуманного контента и сократили долю случаев, в которых галлюцинации влияли на итоговый диагноз, примерно до одной трети. Любопытно, что общей разницы в точности между случаями с галлюцинациями и без них не обнаружилось: возможно, потому что выдуманные детали иногда запускали дополнительные проверки, которые исправляли первоначальные ошибки.
Что это означает для будущего ИИ в клиниках
Для неспециалистов главный вывод таков: современные более сложные медицинские ИИ‑агенты не являются волшебным улучшением по сравнению с сильными чат-ботами. Их можно направлять на более точные ответы через пошаговое рассуждение и использование онлайн-инструментов, но их текущая точность по‑прежнему слишком низка, а потребность во времени и вычислениях — слишком высока, чтобы применять их рутинно без пристального человеческого надзора. Авторы работы утверждают, что прогресс должен фокусироваться не только на незначительном повышении показателей, но и на ускорении систем, снижении их ресурсоемкости, уменьшении склонности к выдумкам и лучшем обосновании на реальных данных пациентов. Только тогда агентный ИИ будет готов безопасно и надёжно помогать клиницистам в повседневной практике.
Цитирование: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
Ключевые слова: клинический ИИ, большие языковые модели, поддержка медицинских решений, ИИ-агенты, бенчмаркинг в здравоохранении