Clear Sky Science · sv
Jämförelse av agentbaserade storspråksmodeller för kliniska beslutsuppgifter
Smartare medicinsk AI — men till vilket pris?
Artificiell intelligens får allt oftare i uppdrag att hjälpa läkare att sålla i komplex information och fatta bättre beslut. En ny studie ställer en enkel men avgörande fråga: presterar dagens mest avancerade ”agentiska” AI-system — utformade för att resonera steg för steg och använda externa verktyg — faktiskt bättre än vanliga chattbotar i realistiska medicinska uppgifter, och är de värda den extra tid och beräkningskraft de kräver?
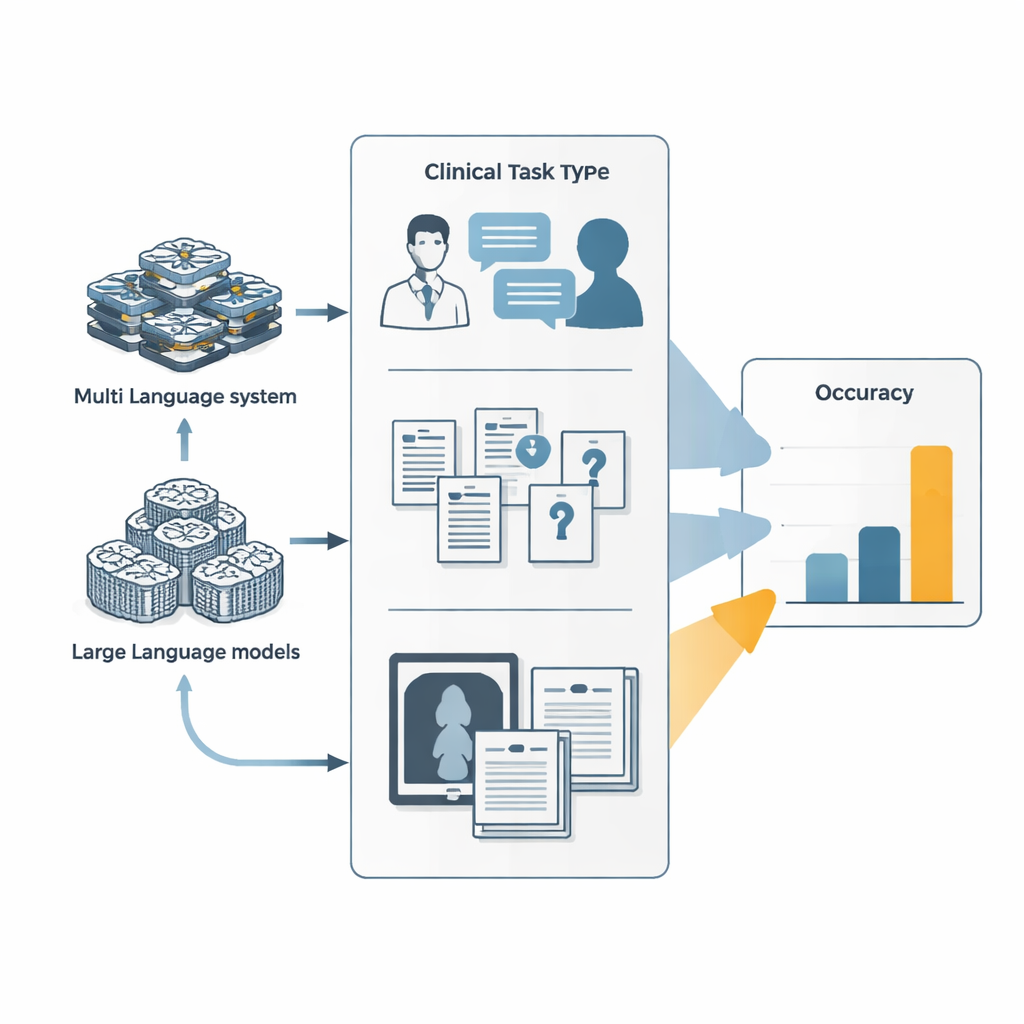
Från enkla chattbotar till uppgiftsutförande agenter
De flesta känner igen storspråksmodeller som chattbotar som svarar på frågor i ett enda svep. Agentiska system bygger vidare på dessa modeller genom att förvandla dem till digitala arbetare som kan planera, anropa externa verktyg som webbläsare eller kodkörningar, och samordna flera specialiserade underagenter. I den här studien jämförde forskarna två sådana agentsystem — Manus och dess öppen källkods-kusin OpenManus — med ledande språkmodeller från större AI-lab. Alla system testades mot tre typer av uppgifter: simulerade läkare–patient-samtal som pågår över många konversationsomgångar, extremt svåra medicinska tentamens- och läroboksfrågor, samt blandade text- och bildutmaningar såsom tolkning av kliniska foton tillsammans med fallbeskrivningar.
Hur bra gick det egentligen för agenterna?
Över dessa riktmärken presterade agentsystemen något bättre än sina underliggande språkmodeller, men endast marginellt. I simulerade diagnostiska samtal ökade tuning av OpenManus för att bete sig som en läkarmedarbetare och använda verktyg mer aktivt dess noggrannhet med omkring 7–9 procentenheter jämfört med baskomponenten. På en krävande uppsättning komplexa, kunskapsintensiva frågor presterade OpenManus återigen något bättre än sin grundmodell och ungefär i paritet med ledande proprietära system. Men de absoluta poängen förblev modest: på några av de svåraste medicinska frågorna, utformade för att motverka genvägar, svarade även de bästa agenterna rätt i färre än en av tio fall — långt under vad som skulle krävas för oövervakad användning i kliniker.
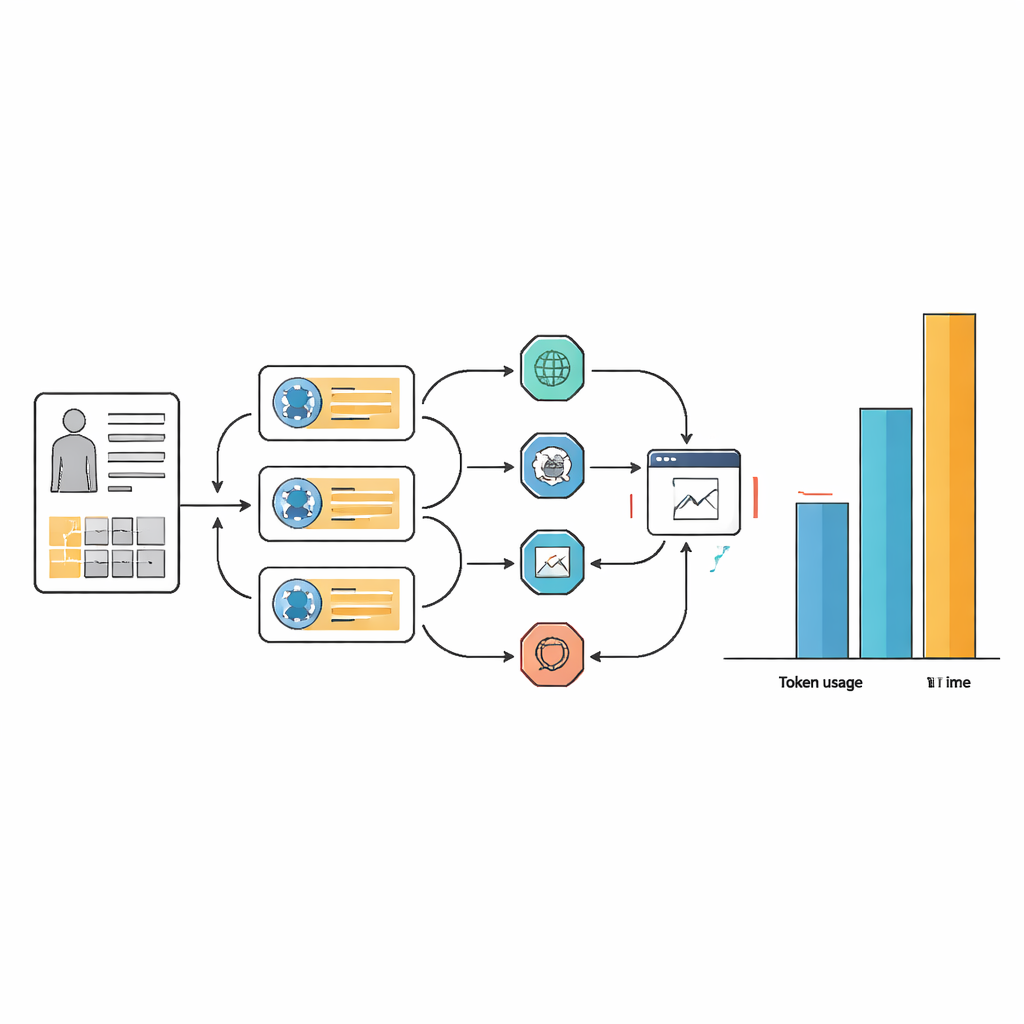
Den dolda kostnaden: tid, komplexitet och beräkningar
Dessa små förbättringar i noggrannhet kom till ett högt pris i form av resurser och arbetsflödets komplexitet. För många uppgifter använde agentsystemen 10 till 100 gånger fler texttoken än den underliggande språkmodellen ensam, och tog ofta mer än dubbelt så lång tid att svara. Denna overhead beror på att agenterna upprepade gånger går igenom planering, webbsökningar, informationsutvinning och omprövningar av svaren. Medan noggrann promptdesign gjorde agenternas arbetsflöden mer strömlinjeformade och konsekventa i verktygsval, avlägsnade det inte behovet av många interna steg. I praktiska termer kan en AI-assistent som tar över en minut och kräver enorm beräkningskraft per fall vara svår att motivera i ett upptaget sjukhus eller i miljöer med begränsade resurser.
Problemet med påhittade detaljer
En annan oro var hallucinationer — när en AI självsäkert hittar på patientsymptom eller laboratorievärden som aldrig gavs. Forskarna fann att nästan varje agentdrivet fall innehöll någon form av hallucination, särskilt fabricerade patientuttalanden eller testvärden. De lade till säkerhetslager som efterbehandlade agenternas output, skrev om prompts för att avråda från gissningar och gav exempel på korrekt beteende. Dessa åtgärder blockerade nästan 90% av det hallucinerade innehållet och minskade andelen fall där hallucinationer påverkade slutdiagnosen till ungefär en tredjedel. Intressant nog fanns ingen tydlig skillnad i den övergripande noggrannheten mellan fall med och utan hallucinationer, möjligen för att uppfunna detaljer ibland utlöste ytterligare kontroller som korrigerade initiala misstag.
Vad detta betyder för framtida AI i kliniker
För icke-specialister är slutsatsen att dagens mer avancerade medicinska AI-agenter inte är magiska uppgraderingar jämfört med starka chattbotar. De kan styras att prestera något bättre genom stegvis resonemang och användning av onlineverktyg, men deras nuvarande noggrannhet är fortfarande för låg och deras behov av tid och beräkningsresurser för högt för rutinmässig klinisk användning utan nära mänsklig övervakning. Studien argumenterar för att framsteg bör fokusera inte bara på att pressa poängen något högre, utan även på att göra systemen snabbare, mindre resurskrävande, mindre benägna att hitta på saker och bättre förankrade i verkliga patientdata. Först då kommer agentisk AI att vara redo att säkert och pålitligt stödja kliniker i vardaglig vård.
Citering: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
Nyckelord: klinisk AI, storspråksmodeller, stöd för medicinska beslut, AI-agenter, jämförande utvärdering inom vården