Clear Sky Science · fr
Évaluation des systèmes agents basés sur de grands modèles de langage pour les tâches décisionnelles cliniques
Une IA médicale plus intelligente, mais à quel prix ?
L’intelligence artificielle est de plus en plus sollicitée pour aider les médecins à trier des informations complexes et à prendre de meilleures décisions. Une nouvelle étude pose une question simple mais essentielle : les systèmes d’IA « agents » les plus avancés aujourd’hui — conçus pour raisonner étape par étape et utiliser des outils en ligne — performent-ils réellement mieux que les chatbots classiques dans des tâches médicales de type réel, et valent-ils le temps et la puissance de calcul supplémentaires qu’ils exigent ?
Des chatbots simples aux agents exécutant des tâches
La plupart des gens connaissent les grands modèles de langage comme des chatbots répondant aux questions en une seule passe. Les systèmes agents s’appuient sur ces modèles en les transformant en travailleurs numériques capables de planifier, d’appeler des outils externes comme des navigateurs web ou des environnements d’exécution de code, et de coordonner plusieurs sous-agents spécialisés. Dans cette étude, les chercheurs ont comparé deux systèmes agents — Manus et son pendant open source OpenManus — à des modèles de langage leaders de grands laboratoires d’IA. Tous les systèmes ont affronté trois familles de tests : des visites simulées médecin–patient se déroulant sur de nombreux tours de conversation, des questions d’examen médical et de manuel extrêmement difficiles, et des défis mixtes texte‑image comme l’interprétation de photos cliniques accompagnées de descriptions de cas.
Quelle a été la performance réelle des agents ?
Sur ces bancs d’essai, les systèmes agents ont devancé leurs modèles de langage sous-jacents, mais seulement légèrement. Dans les conversations diagnostiques simulées, le réglage d’OpenManus pour le faire agir comme un assistant médical et utiliser davantage d’outils a augmenté sa précision d’environ 7 à 9 points de pourcentage par rapport à son modèle de base. Sur un ensemble exigeant de questions complexes et riches en connaissances, OpenManus a encore une fois été un peu meilleur que son modèle de fond et à peu près au même niveau que les meilleurs systèmes propriétaires. Pourtant, les scores absolus sont restés modestes : sur certaines des questions médicales les plus difficiles conçues pour empêcher les raccourcis, même les meilleurs agents ont répondu correctement à moins d’une sur dix, bien en deçà de ce qui serait nécessaire pour une utilisation non supervisée en clinique.
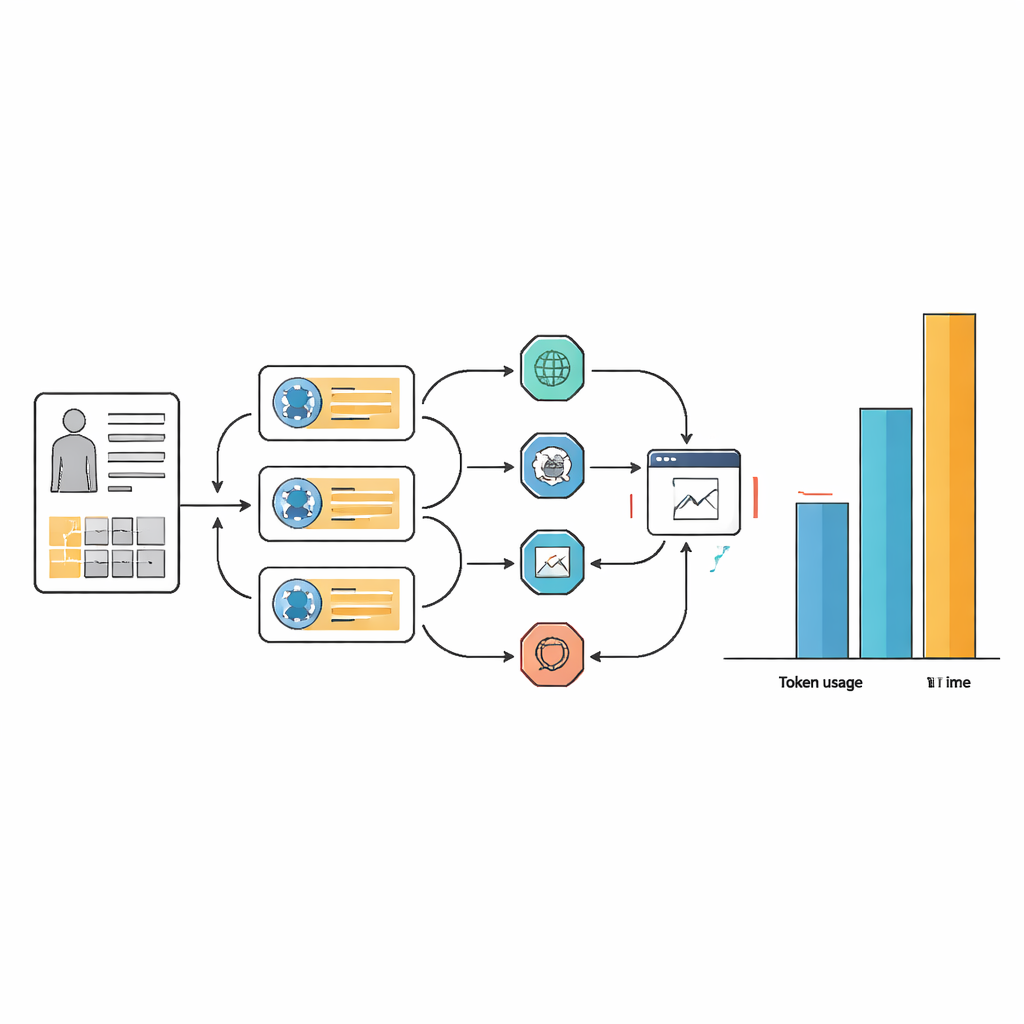
Le coût caché : temps, complexité et calcul
Ces petits gains de précision se sont faits au prix fort en ressources et en complexité de flux de travail. Pour de nombreuses tâches, les systèmes agents ont utilisé de 10 à 100 fois plus de jetons textuels que le modèle de langage sous-jacent seul, et ont souvent mis plus du double de temps à répondre. Cette surcharge provient de la façon dont les agents répètent des boucles de planification, de recherche web, d’extraction d’informations et de réévaluation de leurs réponses. Si une conception de prompt soignée a rendu les flux agents plus rationalisés et cohérents dans le choix des outils, elle n’a pas supprimé le besoin fondamental de nombreuses étapes internes. En pratique, un assistant IA qui prend plus d’une minute et exige d’importantes ressources de calcul par dossier peut être difficile à justifier dans des hôpitaux chargés ou des environnements à ressources limitées.
Le problème des détails inventés
Une autre préoccupation est celle des hallucinations — lorsque l’IA invente avec assurance des symptômes ou des résultats de tests qui n’avaient jamais été fournis. Les chercheurs ont constaté qu’à peu près chaque cas traité par un agent contenait des hallucinations, en particulier des déclarations de patients ou des valeurs de tests fabriquées. Ils ont ajouté des couches de sécurité qui post‑traitaient la sortie des agents, réécrit des prompts pour décourager les conjectures et fourni des exemples de comportement correct. Ces interventions ont bloqué près de 90 % du contenu halluciné et réduit la proportion de cas où les hallucinations affectaient le diagnostic final à environ un tiers. Fait intéressant, il n’y avait pas de différence claire de précision globale entre les cas avec et sans hallucinations, peut‑être parce que les détails inventés déclenchaient parfois des étapes de vérification supplémentaires qui corrigeaient les erreurs initiales.
Ce que cela signifie pour l’IA future en clinique
Pour les non‑spécialistes, la conclusion est que les agents médicaux plus sophistiqués d’aujourd’hui ne constituent pas une amélioration magique par rapport aux chatbots performants. Ils peuvent être orientés pour faire un peu mieux en raisonnant par étapes et en utilisant des outils en ligne, mais leur précision actuelle reste trop faible, et leur appétit pour le temps et la puissance de calcul trop élevé, pour une utilisation clinique courante sans supervision humaine étroite. L’étude soutient que les progrès doivent porter non seulement sur l’augmentation marginale des scores, mais aussi sur l’accélération des systèmes, la réduction de leur consommation de ressources, la limitation de leurs propensions à inventer des faits et leur meilleur ancrage dans des données patients réelles. Ce n’est qu’à ce prix que l’IA agent pourra aider les cliniciens de façon sûre et fiable dans les soins quotidiens.
Citation: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
Mots-clés: IA clinique, grands modèles de langage, assistance à la décision médicale, agents d'IA, évaluation en santé