Clear Sky Science · ar
تقييم أنظمة الوكلاء المعتمدة على نماذج اللغة الكبيرة لمهام القرار السريري
ذكاء اصطناعي طبي أذكى، لكن بأي ثمن؟
يُطلب الآن من الذكاء الاصطناعي بشكل متزايد مساعدة الأطباء في فرز معلومات معقدة واتخاذ قرارات أفضل. تطرح دراسة جديدة سؤالًا بسيطًا لكنه حيوي: هل أنظمة الذكاء الاصطناعي “الوكيلة” الأكثر تقدمًا اليوم—المصممة للتفكير خطوة بخطوة واستخدام أدوات عبر الإنترنت—تؤدي فعلاً أداءً أفضل من روبوتات الدردشة التقليدية في مهام طبية على غرار العالم الحقيقي، وهل تستحق الوقت الإضافي وقوة الحوسبة التي تتطلبها؟
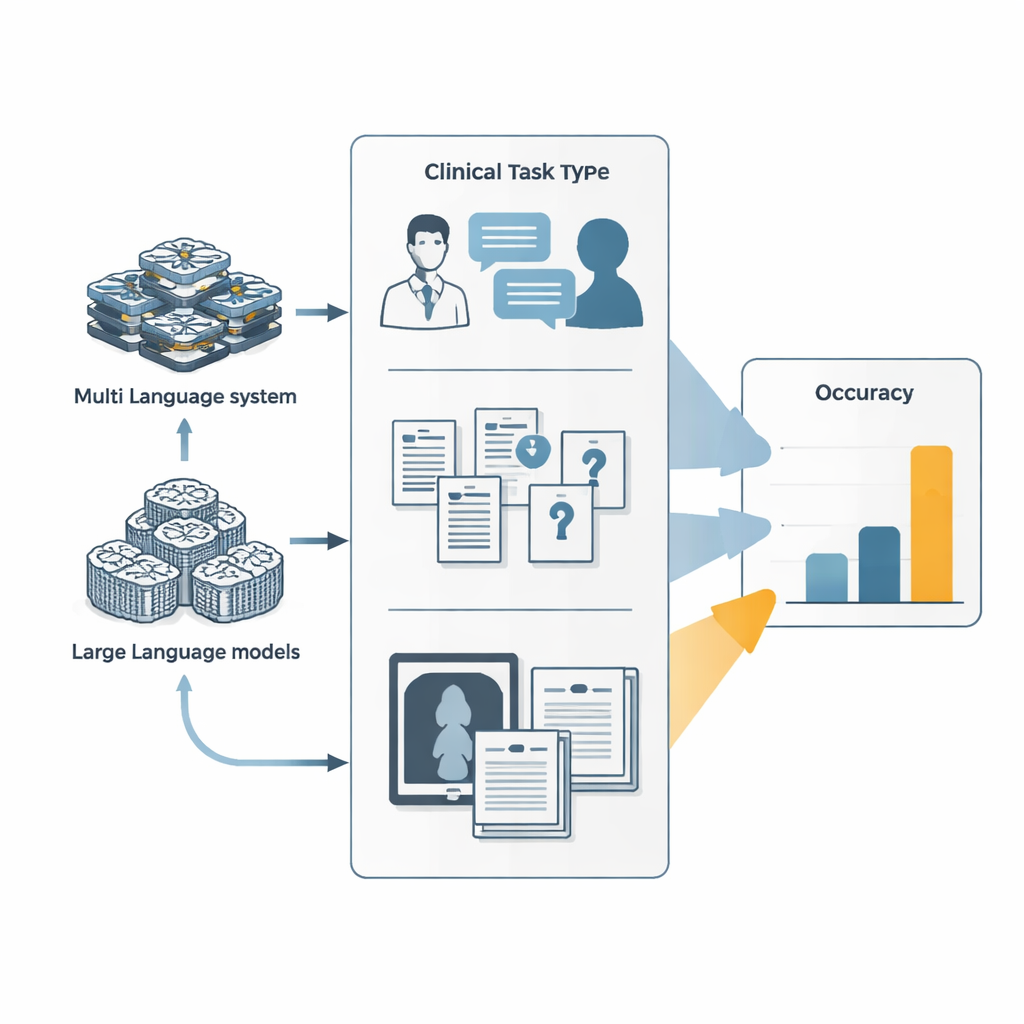
من روبوتات دردشة بسيطة إلى وكلاء ينفذون مهام
يعرف معظم الناس نماذج اللغة الكبيرة روبوتات دردشة تجيب على الأسئلة في خطوة واحدة. تبني الأنظمة الوكيلة على هذه النماذج بتحويلها إلى عمال رقميين يمكنهم التخطيط، واستدعاء أدوات خارجية مثل متصفحات الويب أو مشغلات الشيفرة، وتنسيق عدة وكلاء متخصصين. في هذه الدراسة، قارن الباحثون نظامي وكيل—Manus وقريبه مفتوح المصدر OpenManus—مع نماذج لغوية رائدة من مختبرات ذكاء اصطناعي كبرى. تعاملت جميع الأنظمة مع ثلاث مجموعات من الاختبارات: زيارات طبية محاكاة بين الطبيب والمريض تتطور على امتداد محادثات متعددة الدوران، وأسئلة امتحانات طبية ونصوص مدرسية صعبة جدًا، وتحديات مختلطة نصية وصورية مثل تفسير صور سريرية إلى جانب أوصاف الحالات.
إلى أي مدى أدت الأنظمة الوكيلة فعلاً؟
عبر هذه المقاييس، تفوقت الأنظمة الوكيلة على نماذجها الأساسية، لكن بفارق ضئيل فقط. في المحادثات التشخيصية المحاكاة، زاد ضبط OpenManus ليعمل كمساعد طبي واستخدامه للأدوات بشكل أكثر نشاطًا من دقته بنحو 7–9 نقاط مئوية مقارنة بنموذجه الأساسي. على مجموعة مطالبات من الأسئلة المعقدة والغنية بالمعرفة، أدت OpenManus أيضًا أداءً أفضل قليلاً من النموذج الأساسي وبما يقارب أداء الأنظمة المملوكة الكبرى. ومع ذلك بقيت الدرجات المطلقة متواضعة: في بعض أصعب الأسئلة الطبية المصممة لإحباط الحلول المختصرة، أجابت أفضل الوكلاء بأقل من سؤال واحد من كل عشرة بشكل صحيح، وهو أقل بكثير مما يتطلبه الاستخدام غير المراقب في العيادات.
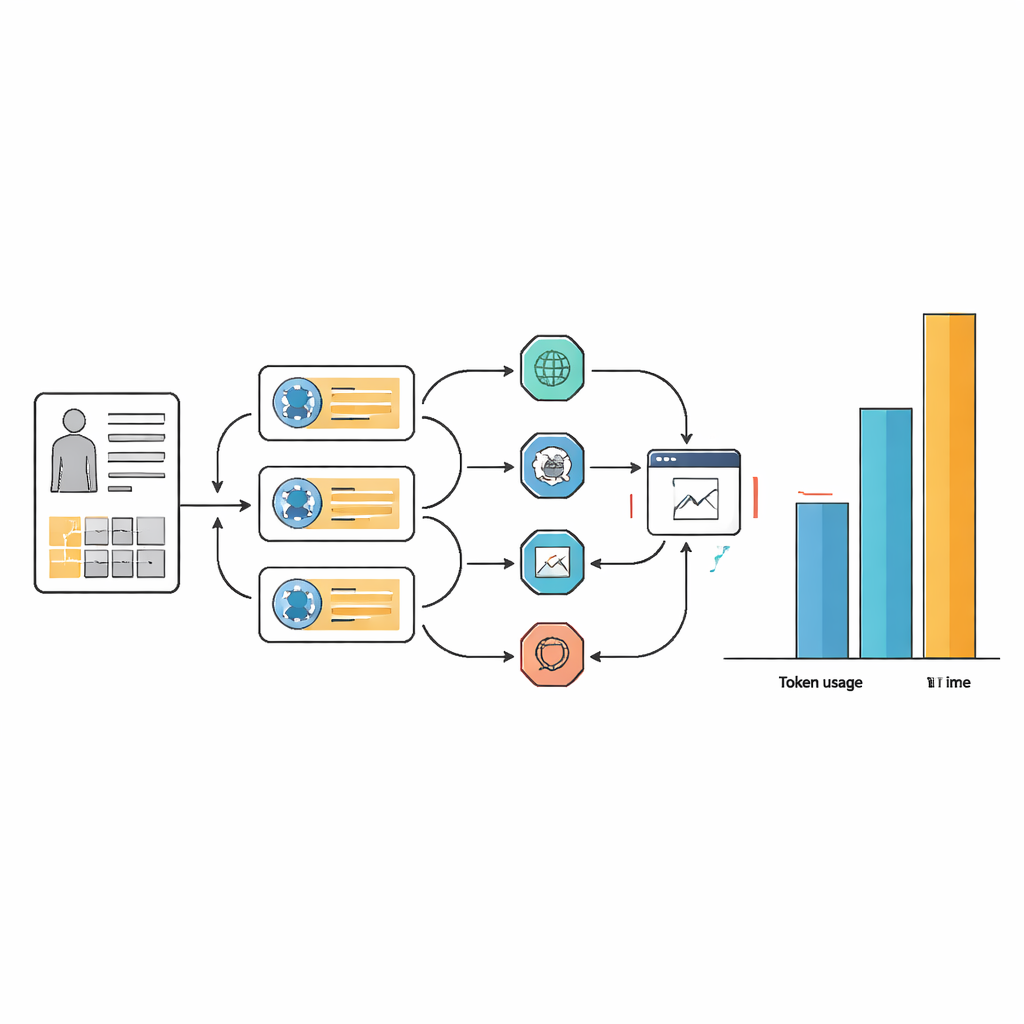
الثمن الخفي: الوقت والتعقيد والحوسبة
جاءت تلك المكاسب الصغيرة في الدقة بتكلفة باهظة من حيث الموارد وتعقيد سير العمل. في العديد من المهام، استخدمت الأنظمة الوكيلة من 10 إلى 100 ضعف عدد الرموز النصية مقارنةً بالنموذج اللغوي الأساسي وحده، وغالبًا ما استغرقت أكثر من ضعف الوقت للرد. ينبع هذا العبء من الطريقة التي تدور بها الوكلاء مرارًا وتكرارًا خلال مراحل التخطيط، والبحث على الويب، واستخراج المعلومات، وإعادة النظر في إجاباتهم. بينما جعل تصميم الموجهات الدقيق سير عمل الوكلاء أكثر انسيابية واتساقًا في اختيار الأدوات، إلا أنه لم يلغِ الحاجة الأساسية للعديد من الخطوات الداخلية. عمليًا، قد يصعب تبرير مساعد ذكاء اصطناعي يستغرق أكثر من دقيقة ويحتاج إلى قدرة حوسبة هائلة لكل حالة في مستشفيات مزدحمة أو بيئات محدودة الموارد.
مشكلة التفاصيل المختـلقة
كان من المخاوف أيضًا الهلوسة—عندما يخترع الذكاء الاصطناعي بثقة أعراض مريض أو نتائج مختبرية لم تُقدّم أبدًا. وجد الباحثون أن كل حالة تديرها الوكلاء تقريبًا احتوت على بعض الهلوسات، خاصة تصريحات أو قيم اختبارات ملفقة من المريض. أضافوا طبقات أمان تراجع مخرجات الوكلاء بعد المعالجة، وأعادوا صياغة الموجهات لتثبيط التكهن، وقدموا أمثلة على السلوك الصحيح. منعت هذه التدابير نحو 90% من المحتوى المخترع وخفضت نسبة الحالات التي أثرت فيها الهلوسات على التشخيص النهائي إلى نحو ثلث الحالات. ومن المثير للاهتمام أنه لم يكن هناك فرق واضح في الدقة الإجمالية بين الحالات التي احتوت على هلوسات وتلك التي لم تحتوِ عليها، ربما لأن التفاصيل المخترعة أحيانًا أثارت خطوات تدقيق إضافية صححت الأخطاء الأولية.
ماذا يعني هذا لمستقبل الذكاء الاصطناعي في العيادات
بالنسبة لغير المتخصصين، الخلاصة أن أنظمة الوكلاء الطبية الأكثر تفصيلاً اليوم ليست ترقيات سحرية على روبوتات الدردشة القوية. يمكن دفعها لتؤدي أداءً أفضل قليلًا عبر التفكير المرحلي واستخدام الأدوات عبر الإنترنت، لكن دقتها الحالية لا تزال منخفضة جدًا، وشهيتها للوقت وقوة الحوسبة مرتفعة جدًا، بحيث لا تصلح للاستخدام السريري الروتيني دون إشراف بشري دقيق. تجادل الدراسة بأن التقدم يجب أن يركّز ليس فقط على رفع الدرجات قليلًا، بل أيضًا على جعل الأنظمة أسرع، وأقل استهلاكًا للموارد، أقل ميلًا للاختلاق، وأكثر تمكينًا من بيانات المرضى الحقيقية. عندئذٍ فقط سيكون الذكاء الاصطناعي الوكلي جاهزًا لمساعدة الأطباء بأمان واعتمادية في الرعاية اليومية.
الاستشهاد: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
الكلمات المفتاحية: الذكاء الاصطناعي السريري, نماذج اللغة الكبيرة, دعم القرار الطبي, وكلاء الذكاء الاصطناعي, معايير الرعاية الصحية