Clear Sky Science · ja
臨床意思決定タスク向けの大規模言語モデルベースのエージェントシステムのベンチマーク
賢い医療AI、しかし代償は?
人工知能はますます医師が複雑な情報を整理し、より良い判断を下す手助けを求められるようになっています。新しい研究はシンプルだが重要な問いを投げかけます:今日の最先端の「エージェント型」AIシステム(段階的に推論しオンラインツールを使うよう設計されたもの)は、実世界に即した医療タスクで従来型のチャットボットより本当に優れているのか、そしてそれが要求する追加の時間や計算資源に見合う価値があるのか?
単純なチャットボットからタスクを実行するエージェントへ
多くの人が大規模言語モデルを一回で質問に答えるチャットボットとして認識しています。エージェント型システムはこれを踏み越え、計画を立て、ウェブブラウザやコード実行環境など外部ツールを呼び、複数の専門サブエージェントを調整するデジタル作業者に変えます。本研究では、研究者たちが2つのエージェントシステム—Manus とそのオープンソースの従兄弟である OpenManus—を主要なAI研究所のトップモデルと比較しました。全てのシステムは三つのカテゴリーのベンチマークに取り組みました:多くの会話ターンで進行する模擬医師–患者面接、非常に難しい医療試験や教科書の問題、臨床写真の解釈と症例記述を組み合わせたテキスト+画像の混合課題です。
エージェントは実際どれほど有効だったか?
これらのベンチマーク全体で、エージェントシステムは基盤となる言語モデルをわずかに上回りましたが、その差は小さなものでした。模擬診断の会話では、OpenManus を医師助手のように振る舞わせ、ツールの使用をより積極的に調整すると、ベースモデルに比べて精度が約7~9ポイント向上しました。知識負荷の高い難問では、OpenManus は再びバックボーンモデルよりやや良い成績を示し、主要な独自モデルと概ね同等でした。しかし絶対的なスコアは控えめのままで、ショートカットを封じるように設計された最も難しい医療問題では、最良のエージェントでも正答率が10%未満にとどまり、臨床での非監督利用に耐えうる水準からは遠く及びませんでした。
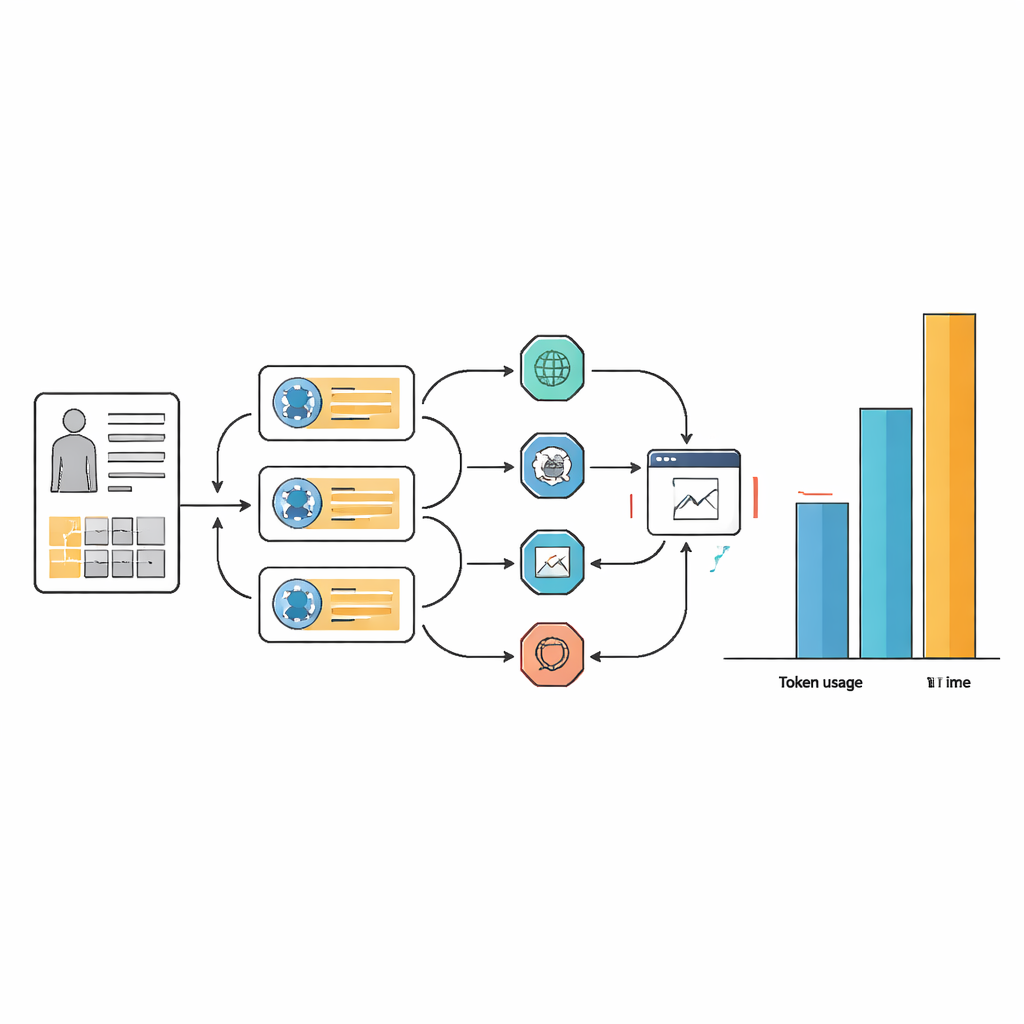
隠れた代償:時間、複雑さ、計算資源
そのわずかな精度向上は、資源とワークフローの複雑化という大きな代償を伴いました。多くのタスクで、エージェントシステムは基礎モデル単体より10倍から100倍のテキストトークンを消費し、応答に要する時間もしばしば2倍以上でした。このオーバーヘッドは、エージェントが計画、ウェブ検索、情報抽出、回答の再検討を繰り返しループする仕組みに起因します。慎重なプロンプト設計によりエージェントのワークフローはより効率的でツール選択が一貫するようにはなりましたが、多くの内部ステップが不可避という基本的な要件は取り除かれませんでした。実務面では、1症例あたり1分以上かかり膨大な計算資源を要するAIアシスタントは、忙しい病院や資源の乏しい現場で正当化しづらい可能性があります。
作り話(ハルシネーション)の問題
もう一つの懸念はハルシネーション、すなわちAIが提供されていない患者の症状や検査結果を自信満々に捏造することです。研究者たちは、ほとんどすべてのエージェント運用症例で何らかのハルシネーションが含まれていることを見出しました。特に患者の発言や検査値の捏造が目立ちました。彼らはエージェントの出力を後処理する安全層を追加し、推測を抑止するようプロンプトを改訂し、正しい振る舞いの例を示しました。これらの介入により、ハルシネートされた内容のほぼ90%が遮断され、最終診断にハルシネーションが影響した症例の割合は約3分の1まで減少しました。興味深いことに、ハルシネーションの有無で全体の精度に明確な差は見られませんでした。おそらく捏造された詳細が追加の検証手順を引き起こし、初期の誤りを訂正することがあったためと考えられます。
臨床でのAIの将来にとっての含意
非専門家向けの結論は、現時点のより精巧な医療AIエージェントは強力なチャットボットに対する魔法のようなアップグレードではない、ということです。段階的に推論しオンラインツールを使うことでやや良い成績を引き出せる場合はありますが、現状の精度は依然として低く、時間と計算資源の消費は高すぎるため、厳格な人間の監督なしに日常診療で使うには不十分です。研究は、スコアを僅かに押し上げることだけでなく、システムをより高速に、より少ない資源で、捏造を起こしにくく、実際の患者データにより確実に基づくようにすることにも進歩の焦点を当てるべきだと主張しています。そうなって初めて、エージェント型AIは臨床現場で安全かつ信頼できる形で臨床医を支援できるようになるでしょう。
引用: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
キーワード: 臨床AI, 大規模言語モデル, 医療意思決定支援, AIエージェント, ヘルスケアのベンチマーク