Clear Sky Science · pl
Porównanie systemów agentowych opartych na dużych modelach językowych dla zadań decyzyjnych w klinice
Mądrzejsza medyczna SI — ale jaką cenę przy tym płacimy?
Sztuczna inteligencja coraz częściej ma pomagać lekarzom w przeszukiwaniu złożonych informacji i podejmowaniu lepszych decyzji. Nowe badanie stawia proste, lecz istotne pytanie: czy dzisiejsze, najbardziej zaawansowane systemy „agentowe” — zaprojektowane do rozumowania krok po kroku i korzystania z narzędzi online — rzeczywiście wypadają lepiej od standardowych chatbotów w zadaniach medycznych przypominających rzeczywiste sytuacje, i czy przewaga ta uzasadnia dodatkowy czas i moc obliczeniową, których wymagają?
Od prostych chatbotów do agentów wykonujących zadania
Większość osób zna duże modele językowe jako chatboty odpowiadające na pytania w jednym przebiegu. Systemy agentowe rozbudowują te modele, przekształcając je w cyfrowych pracowników, którzy potrafią planować, wywoływać zewnętrzne narzędzia, takie jak przeglądarki czy interpretery kodu, oraz koordynować wyspecjalizowane pod-agenty. W badaniu porównano dwa takie systemy — Manus i jego otwartoźródłowego kuzyna OpenManus — z czołowymi modelami językowymi z największych firm AI. Wszystkie systemy mierzyły się z trzema grupami testów: symulowanymi wizytami lekarskimi toczącymi się w wielu turach rozmowy, ekstremalnie trudnymi pytaniami z egzaminów i podręczników medycznych oraz zadaniami mieszanymi tekstowo-obrazowymi, jak interpretacja zdjęć klinicznych wraz z opisem przypadku.
Jak dobrze wypadły agenty?
W tych benchmarkach systemy agentowe rzeczywiście nieznacznie przewyższały swoje bazowe modele językowe, lecz tylko w niewielkim stopniu. W symulowanych rozmowach diagnostycznych dostrojenie OpenManus tak, by zachowywał się jak asystent lekarza i aktywniej korzystał z narzędzi, zwiększyło jego dokładność o około 7–9 punktów procentowych w porównaniu z modelem bazowym. W wymagającym zbiorze skomplikowanych, obciążonych wiedzą pytań OpenManus również wypadł nieco lepiej niż model bazowy i w przybliżeniu porównywalnie z najlepszymi systemami komercyjnymi. Jednak wartości bezwzględne pozostały umiarkowane: w niektórych najtrudniejszych pytaniach medycznych zaprojektowanych tak, by zniwelować skróty myślowe, nawet najlepsze agenty odpowiadały prawidłowo w mniej niż jednym na dziesięć przypadków — daleko od poziomu wymagającego zastosowania bez nadzoru w klinikach.
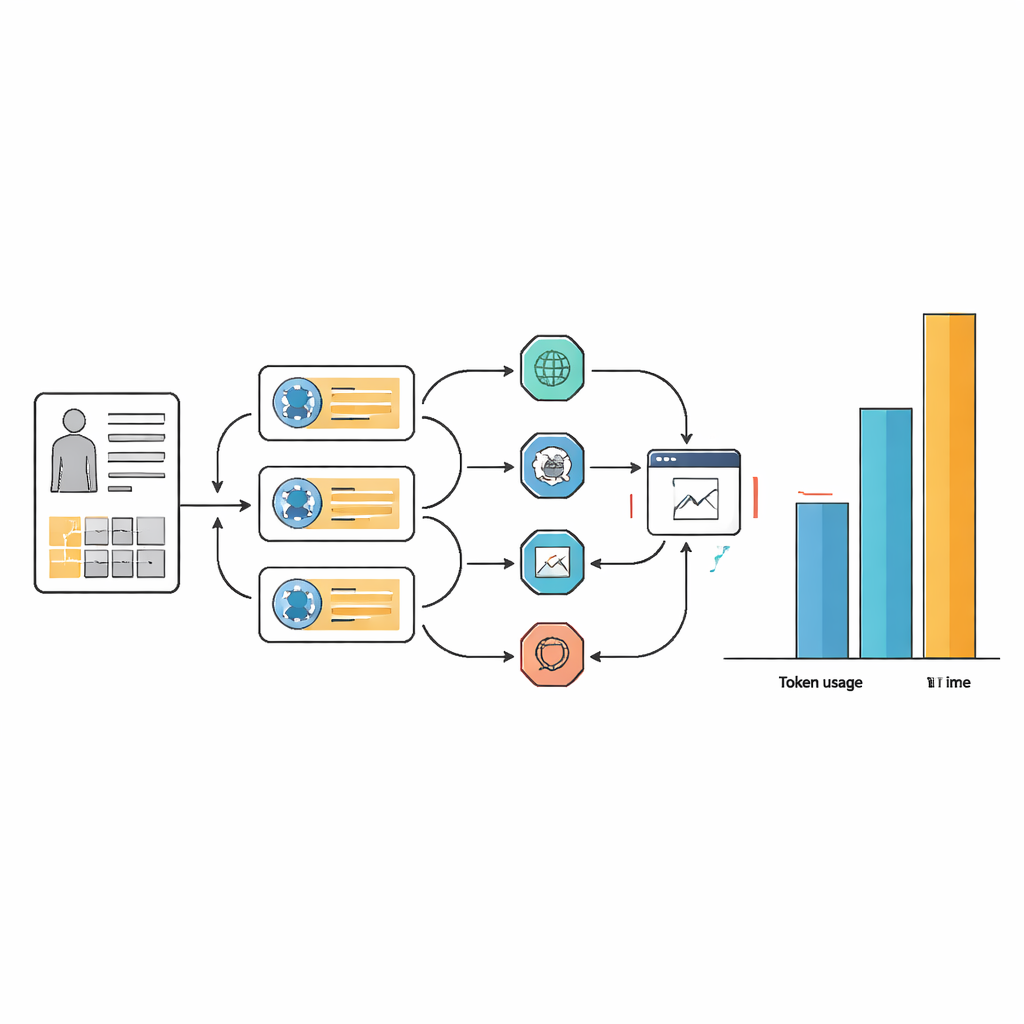
Ukryta cena: czas, złożoność i zasoby obliczeniowe
Te niewielkie zyski w dokładności wiązały się z wysokimi kosztami w postaci zasobów i złożoności przepływu pracy. W wielu zadaniach systemy agentowe używały od 10 do 100 razy więcej tokenów tekstowych niż sam model bazowy i często potrzebowały ponad dwukrotnie więcej czasu na odpowiedź. Ten narzut wynika z mechanizmu, w którym agenty wielokrotnie przechodzą przez etapy planowania, przeszukiwania sieci, wydobywania informacji i ponownego rozważania odpowiedzi. Choć staranne projektowanie promptów uczyniło przepływy pracy agentów bardziej wydajnymi i spójnymi w doborze narzędzi, nie wyeliminowało podstawowej potrzeby wielu wewnętrznych kroków. W praktyce asystent SI, który na każdą sprawę poświęca ponad minutę i ogromne moce obliczeniowe, może być trudny do uzasadnienia w zatłoczonych szpitalach czy w warunkach z ograniczonymi zasobami.
Problem z wymyślonymi szczegółami
Kolejnym problemem były halucynacje — sytuacje, gdy SI pewnie fabrykuje objawy pacjenta lub wyniki badań, które nigdy nie zostały podane. Badacze stwierdzili, że niemal w każdym przypadku obsługiwanym przez agenty pojawiały się pewne halucynacje, zwłaszcza sfabrykowane wypowiedzi pacjenta lub wartości testów. Dodali warstwy bezpieczeństwa, które postprocesowały wyjścia agentów, przepisali prompty tak, by zniechęcać do zgadywania, i dostarczyli przykłady prawidłowego zachowania. Interwencje te zablokowały prawie 90% zhalucynowanego materiału i zmniejszyły odsetek przypadków, w których halucynacje wpłynęły na ostateczną diagnozę, do około jednej trzeciej. Co ciekawe, nie stwierdzono wyraźnej różnicy w ogólnej dokładności między przypadkami z halucynacjami i bez nich — być może dlatego, że wymyślone szczegóły czasem uruchamiały dodatkowe kroki weryfikacyjne, które korygowały początkowe błędy.
Co to oznacza dla przyszłej SI w klinikach
Dla osób niezajmujących się specjalistycznie tematem wniosek jest taki, że dzisiejsze bardziej rozbudowane medyczne agenty AI nie stanowią magicznej poprawy względem dobrych chatbotów. Można je popchnąć, by pracowały nieco lepiej poprzez rozumowanie etapami i korzystanie z narzędzi online, ale ich obecna dokładność nadal jest zbyt niska, a zapotrzebowanie na czas i moc obliczeniową zbyt duże, by stosować je rutynowo bez ścisłego nadzoru człowieka. Autorzy badania argumentują, że postęp powinien koncentrować się nie tylko na nieznacznym podnoszeniu wyników, lecz także na przyspieszeniu systemów, zmniejszeniu ich zapotrzebowania na zasoby, ograniczeniu skłonności do wymyślania faktów i lepszym osadzeniu w rzeczywistych danych pacjentów. Tylko wtedy agentowa SI będzie gotowa, by bezpiecznie i niezawodnie wspierać klinicystów w codziennej opiece.
Cytowanie: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
Słowa kluczowe: Sztuczna inteligencja kliniczna, duże modele językowe, wsparcie decyzji medycznych, agenci AI, benchmarking w opiece zdrowotnej