Clear Sky Science · it
Benchmarking large language model-based agent systems for clinical decision tasks
Intelligenza artificiale medica più intelligente, ma a che prezzo?
L’intelligenza artificiale viene sempre più spesso impiegata per aiutare i medici a districarsi in informazioni complesse e prendere decisioni migliori. Un nuovo studio pone una domanda semplice ma cruciale: i sistemi AI «agenziali» più avanzati di oggi — progettati per ragionare passo dopo passo e usare strumenti online — funzionano davvero meglio rispetto ai chatbot standard in compiti medici di tipo realistico, e valgono il tempo e la potenza di calcolo aggiuntivi che richiedono?
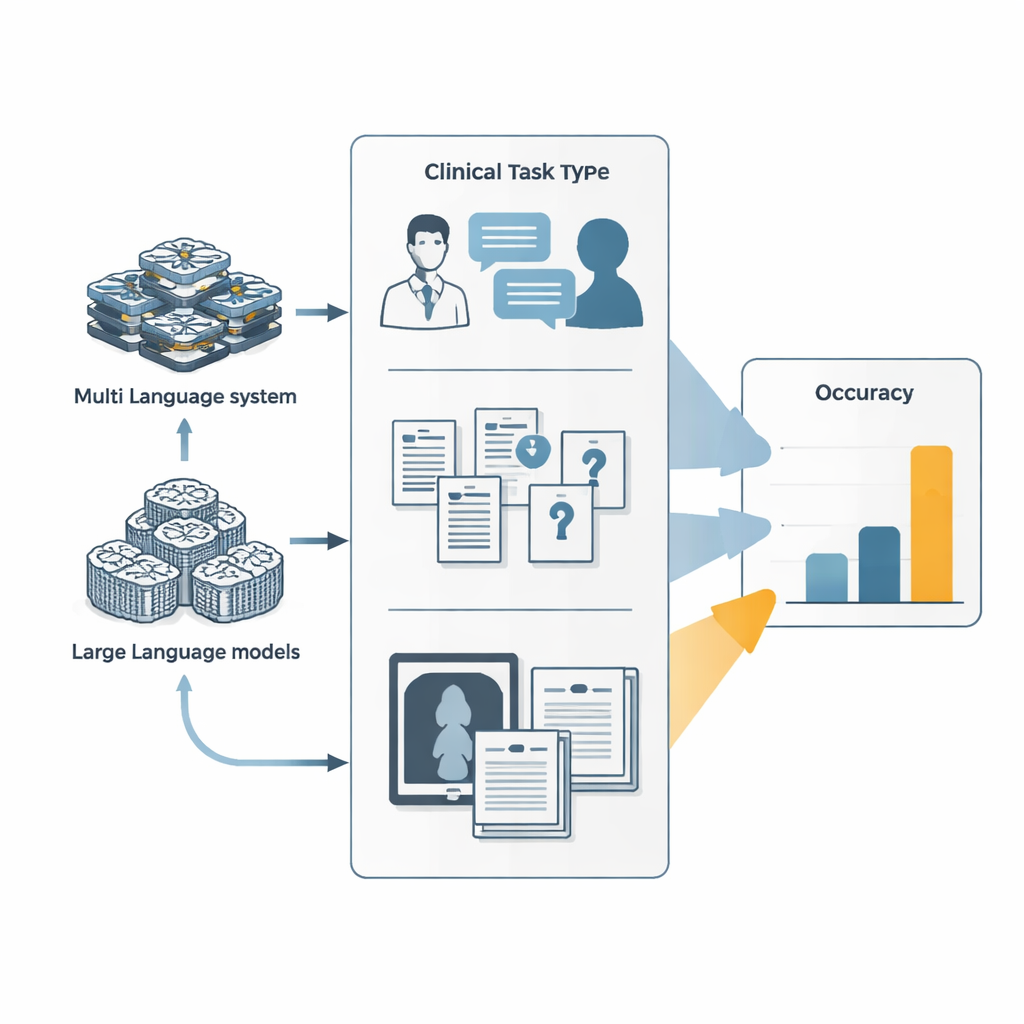
Da semplici chatbot ad agenti esecutori di compiti
La maggior parte delle persone conosce i modelli linguistici come chatbot che rispondono alle domande in un unico passaggio. I sistemi agenziali si basano su questi modelli trasformandoli in «lavoratori» digitali in grado di pianificare, chiamare strumenti esterni come browser web o esecutori di codice e coordinare più sotto-agenti specializzati. In questo studio i ricercatori hanno confrontato due di questi sistemi agenti — Manus e il suo equivalente open source OpenManus — con i principali modelli linguistici dei grandi laboratori di IA. Tutti i sistemi hanno affrontato tre famiglie di test: visite simulate medico–paziente che si svolgono su molti turni conversazionali, domande d’esame e di manuale estremamente difficili e sfide miste testo-e-immagine, come l’interpretazione di foto cliniche insieme a descrizioni dei casi.
Quanto bene se la sono cavata gli agenti?
In questi benchmark i sistemi agenti hanno sopravanzato i loro modelli di base, ma solo di poco. Nelle conversazioni diagnostiche simulate, la messa a punto di OpenManus per comportarsi come un assistente medico e per usare gli strumenti in modo più attivo ha aumentato la sua accuratezza di circa 7–9 punti percentuali rispetto al modello di base. Su un insieme impegnativo di domande complesse e ricche di conoscenza, OpenManus ha nuovamente ottenuto risultati leggermente migliori rispetto al suo modello di riferimento e in linea con i migliori sistemi proprietari. Tuttavia i punteggi assoluti sono rimasti modesti: su alcune delle domande mediche più difficili, progettate per contrastare le scorciatoie, anche i migliori agenti hanno risposto correttamente a meno di una su dieci, ben lontano da quanto sarebbe necessario per un uso non supervisionato in ambito clinico.
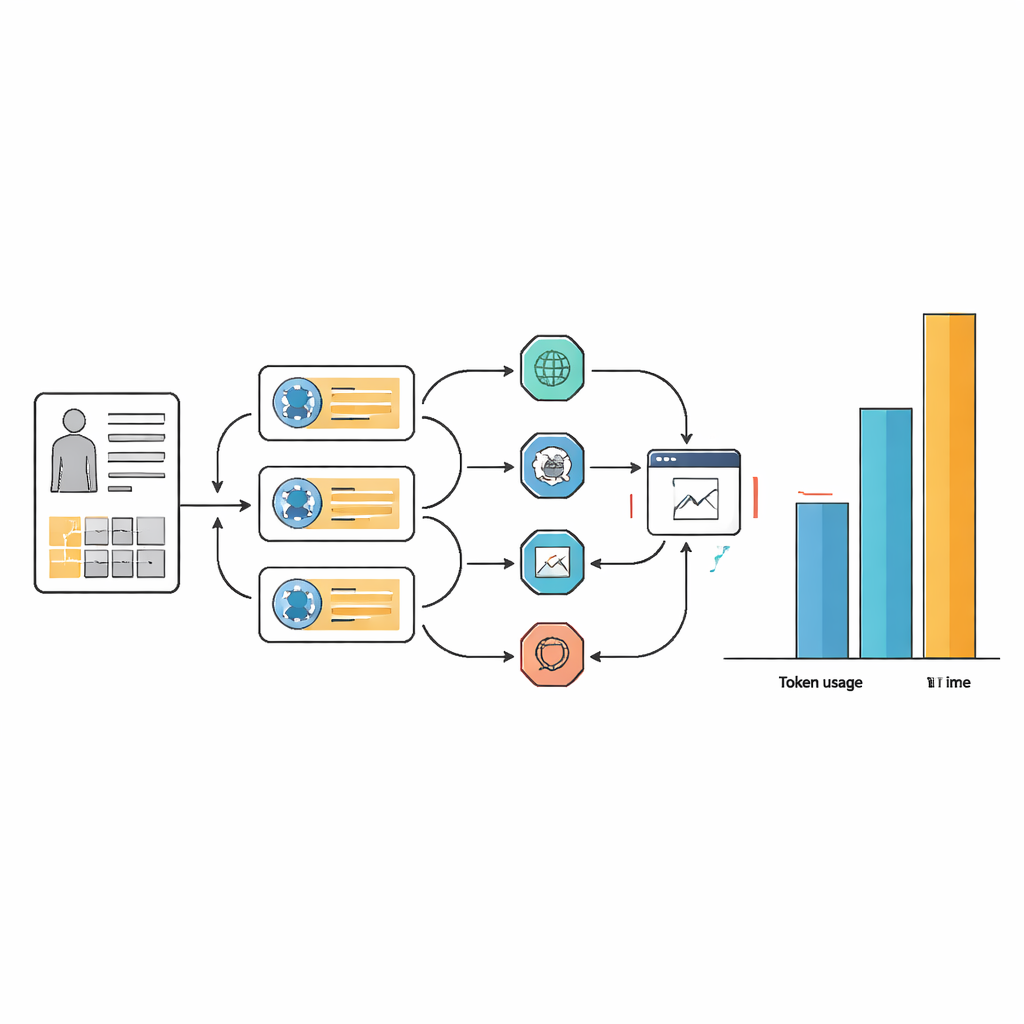
Il prezzo nascosto: tempo, complessità e calcolo
Questi piccoli guadagni in accuratezza sono costati molto in termini di risorse e complessità del flusso di lavoro. Per molti compiti i sistemi agenti hanno utilizzato da 10 a 100 volte più token di testo rispetto al solo modello linguistico di base e spesso hanno impiegato più del doppio del tempo per rispondere. Questo sovraccarico deriva dal modo in cui gli agenti iterano ripetutamente pianificazione, ricerca sul web, estrazione di informazioni e riconsiderazione delle risposte. Pur essendo una progettazione attenta dei prompt in grado di rendere i flussi di lavoro degli agenti più snelli e coerenti nella scelta degli strumenti, non è stata eliminata la necessità di numerosi passaggi interni. In termini pratici, un assistente AI che richiede oltre un minuto e ingenti risorse di calcolo per caso può risultare difficile da giustificare in ospedali affollati o in contesti con risorse limitate.
Il problema dei dettagli inventati
Un’altra preoccupazione è stata l’allucinazione — quando un’IA inventa con sicurezza sintomi del paziente o risultati di esami che non sono stati forniti. I ricercatori hanno osservato che quasi ogni caso gestito dagli agenti conteneva qualche allucinazione, in particolare dichiarazioni fabbricate del paziente o valori di test. Hanno introdotto livelli di sicurezza che post-elaboravano l’output degli agenti, riscritto i prompt per scoraggiare le ipotesi e fornito esempi di comportamento corretto. Questi interventi hanno bloccato quasi il 90% dei contenuti allucinati e hanno ridotto la frazione di casi in cui le allucinazioni influenzavano la diagnosi finale a circa un terzo. Interessante, non c’è stata una differenza netta nell’accuratezza complessiva tra i casi con e senza allucinazioni, forse perché i dettagli inventati talvolta innescavano controlli aggiuntivi che correggevano errori iniziali.
Cosa significa questo per il futuro dell’IA nelle cliniche
Per i non specialisti, la conclusione è che gli agenti medici più elaborati di oggi non sono aggiornamenti miracolosi rispetto ai chatbot avanzati. Possono essere spinti a ottenere risultati leggermente migliori ragionando per fasi e usando strumenti online, ma la loro accuratezza attuale è ancora troppo bassa e il loro consumo di tempo e risorse troppo elevato per un uso clinico routinario senza stretta supervisione umana. Lo studio sostiene che il progresso dovrebbe concentrarsi non solo sull’aumentare leggermente i punteggi, ma anche nel rendere i sistemi più veloci, meno assetati di risorse, meno propensi a inventare dettagli e meglio ancorati a dati reali dei pazienti. Solo allora l’IA agente sarà pronta per assistere clinici in modo sicuro e affidabile nella pratica quotidiana.
Citazione: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
Parole chiave: IA clinica, modelli linguistici di grandi dimensioni, supporto decisionale medico, agenti AI, benchmarking sanitario