Clear Sky Science · nl
Benchmarking van agentensystemen op basis van grote taalmodellen voor klinische besluitvormingstaken
Slimmere medische AI, maar tegen welke prijs?
Kunstmatige intelligentie wordt steeds vaker ingezet om artsen te helpen complexe informatie te ordenen en betere beslissingen te nemen. Een nieuwe studie stelt een eenvoudige maar essentiële vraag: presteren de meest geavanceerde ‘agentachtige’ AI-systemen van vandaag — ontworpen om stap voor stap te redeneren en online tools te gebruiken — daadwerkelijk beter dan standaardchatbots bij medische taken in realistische situaties, en wegen die voordelen op tegen de extra tijd en rekenkracht die ze vereisen?
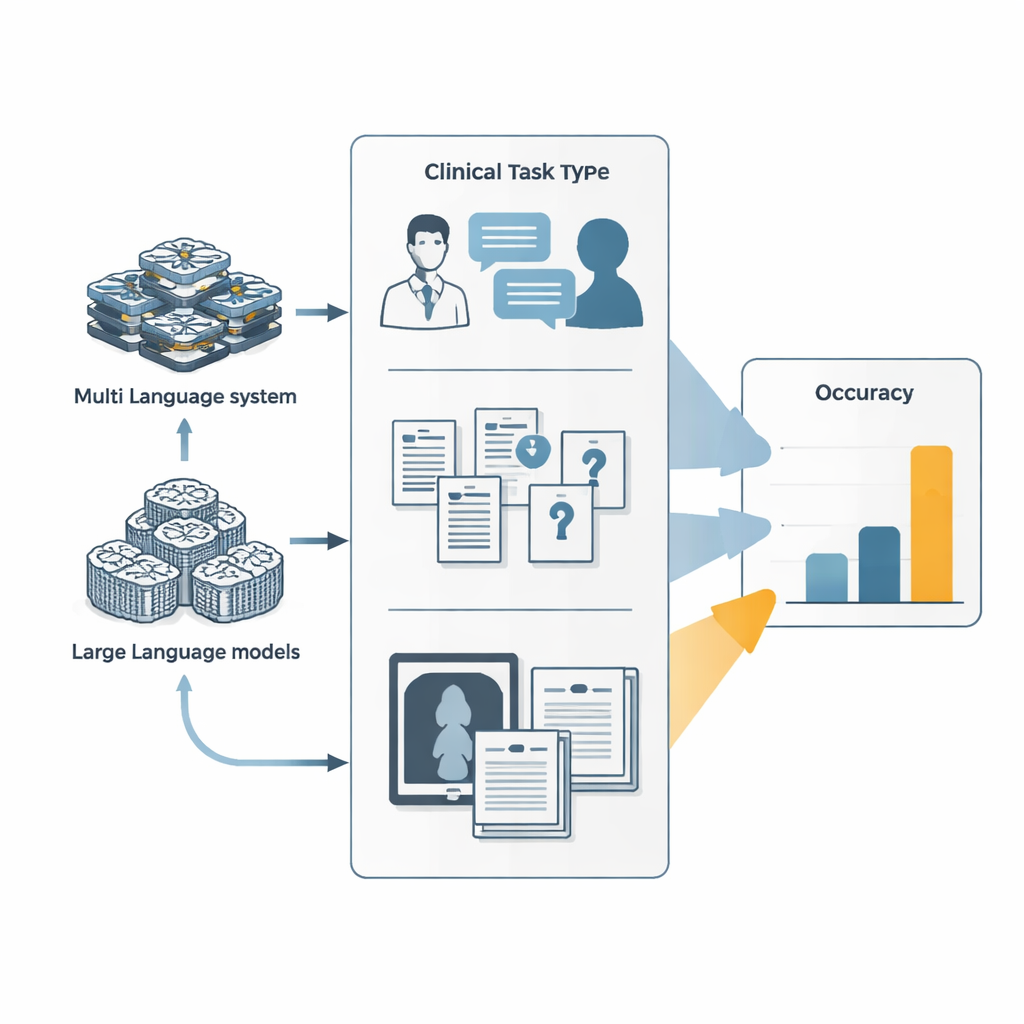
Van eenvoudige chatbots naar taakuitvoerende agenten
De meeste mensen kennen grote taalmodellen als chatbots die in één keer vragen beantwoorden. Agentachtige systemen bouwen voort op deze modellen door ze om te vormen tot digitale medewerkers die kunnen plannen, externe tools zoals webbrowsers of code-executors kunnen aanroepen, en meerdere gespecialiseerde sub-agenten kunnen coördineren. In deze studie vergeleken onderzoekers twee dergelijke agentsystemen — Manus en de open-source tegenhanger OpenManus — met toonaangevende taalmodellen van grote AI‑labben. Alle systemen doorliepen drie typen toetsen: gesimuleerde arts‑patiëntgesprekken die zich over vele conversatierondes ontvouwen, uitermate moeilijke medische examen- en tekstboekvragen, en gemengde tekst‑en‑beelduitdagingen zoals het interpreteren van klinische foto’s naast casusbeschrijvingen.
Hoe goed deden de agenten het echt?
Over deze benchmarks heen behaalden de agentsystemen iets betere resultaten dan hun onderliggende taalmodellen, maar slechts marginaal. In gesimuleerde diagnostische gesprekken leidde het afstemmen van OpenManus zodat het zich gedraagt als een assistent van een arts en actiever tools gebruikt tot een nauwkeurigheidstoename van ongeveer 7–9 procentpunten vergeleken met het basismodel. Bij een veeleisende set complexe, kennisintensieve vragen presteerde OpenManus opnieuw iets beter dan zijn backbone-model en grofweg vergelijkbaar met de beste propriëtaire systemen. De absolute scores bleven echter bescheiden: bij sommige van de moeilijkste medische vragen, ontworpen om korte routes te blokkeren, beantwoordden zelfs de beste agenten minder dan één op de tien correct, ver onder wat nodig zou zijn voor onbegeleide toepassing in klinieken.
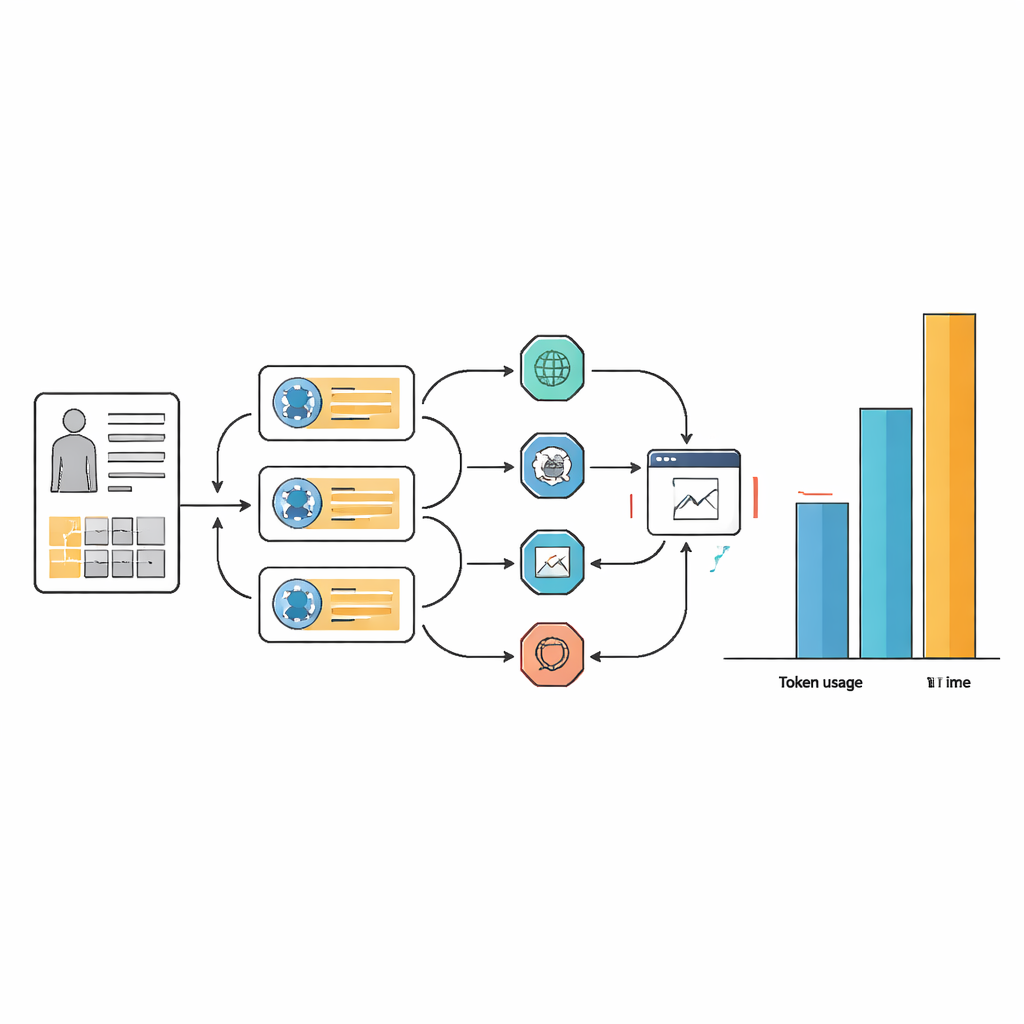
De verborgen prijs: tijd, complexiteit en rekenkracht
Die kleine winst in nauwkeurigheid ging gepaard met een hoge prijs in middelen en workflowcomplexiteit. Voor veel taken gebruikten de agentsystemen 10 tot 100 keer meer teksttokens dan het onderliggende taalmodel alleen, en ze deden er vaak meer dan twee keer zo lang over om te antwoorden. Deze overhead komt doordat agenten herhaaldelijk door planningsstappen lopen, het web doorzoeken, informatie extraheren en hun antwoorden heroverwegen. Hoewel zorgvuldige promptontwerpen agentworkflows gestroomlijnder maakten en consistenter in hun keuze van tools, nam dat de fundamentele noodzaak voor veel interne stappen niet weg. In praktische termen kan een AI‑assistent die per casus meer dan een minuut en enorme rekenkracht vergt moeilijk te rechtvaardigen zijn in drukke ziekenhuizen of situaties met beperkte middelen.
Het probleem van verzonnen details
Een andere zorg was hallucination — wanneer een AI vol vertrouwen patiëntsymptomen of labwaarden verzint die nooit zijn gegeven. De onderzoekers vonden dat bijna elke door een agent verwerkte casus enige hallucinations bevatte, vooral gefabriceerde patiëntuitspraken of testwaarden. Ze voegden beveiligingslagen toe die de output van de agenten nabewerkten, herschreven prompts om gokken te ontmoedigen, en voorbeelden gaven van correct gedrag. Deze interventies blokkeerden bijna 90% van de gehallucineerde inhoud en verminderden het aandeel casussen waarbij hallucinations de uiteindelijke diagnose beïnvloedden tot ongeveer een derde. Interessant genoeg was er geen duidelijk verschil in algemene nauwkeurigheid tussen casussen met en zonder hallucinations, mogelijk omdat uitgevonden details soms extra controlestappen triggerden die aanvankelijke fouten corrigeerden.
Wat dit betekent voor toekomstige AI in klinieken
Voor niet‑specialisten is de conclusie dat de huidige, meer uitgewerkte medische AI‑agenten geen magische verbetering zijn ten opzichte van sterke chatbots. Ze kunnen door stapsgewijs redeneren en het gebruik van online tools enigszins beter worden gemaakt, maar hun huidige nauwkeurigheid is nog te laag en hun vraatzucht naar tijd en rekenkracht te groot voor routinematig klinisch gebruik zonder nauwlettend menselijk toezicht. De studie pleit ervoor om vooruitgang niet alleen te richten op het iets hoger duwen van scores, maar ook op het sneller maken van systemen, het verlagen van hun middelengebruik, het verminderen van het verzinnen van feiten, en het beter verankeren in echte patiëntdata. Pas dan zullen agentachtige AI’s klaar zijn om klinici veilig en betrouwbaar te ondersteunen in de dagelijkse zorg.
Bronvermelding: Liu, Y., Carrero, Z.I., Jiang, X. et al. Benchmarking large language model-based agent systems for clinical decision tasks. npj Digit. Med. 9, 259 (2026). https://doi.org/10.1038/s41746-026-02443-6
Trefwoorden: klinische AI, grote taalmodellen, ondersteuning medische besluitvorming, AI-agenten, benchmarking in de gezondheidszorg