Clear Sky Science · zh
一种混合 ConvNeXt–BiLSTM 框架以实现稳健的场景文本识别
为什么在照片中识别文本很重要
每天,摄像头都会捕捉到街牌、店名、公交站牌以及充满文字的屏幕截图。教会计算机识别这类文本可以为导航应用提供动力、帮助低视力人群,并将凌乱的照片变成可检索的信息。然而,真实场景中的文本很少整洁:它可能弯曲、倾斜、模糊或被繁杂背景部分遮挡。本研究提出了一种更智能、更快速的方式来让计算机读取这些具有挑战性的场景文本,通过重新设计图像的观察方式以及如何从合成与真实样本中学习。 
从干净扫描件到凌乱的现实世界
传统的文本识别软件是为扫描文档构建的,字符位于平整、干净的页面上。相比之下,场景文本识别必须应对被角度拍摄的路标、霓虹标志、金属反光,以及混杂的字体和语言。以往系统在很大程度上依赖合成数据:将计算机生成的词粘贴到图像上。这些大规模的人工集合易于标注,但缺乏真实街头的全部混乱。因此,在测试集上表现良好的模型在遇到拥挤的广告牌、弯曲的店名或光线不足时仍可能失败。作者认为,进展现在依赖于更好的图像处理和更丰富的真实样本。
以新的方式观察图像中的单词
所提出系统的核心是一个现代图像解析器 ConvNeXt,结合了一个称为双向 LSTM 的序列读取器。在图像被分析之前,先经过一个特殊的变换阶段,将扭曲或弯曲的文本轻柔拉直,使其更像水平单词。然后 ConvNeXt 将图像分解为许多小片段,学习捕捉细微笔画、字符形状以及单词的长水平流动的模式,同时忽略干扰性的背景杂色。额外模块帮助网络在全局上下文与局部细节之间进行平衡,并将注意力集中在最有信息的区域,例如字母实际出现的位置。最后,序列读取器从左到右和从右到左扫描这些特征,基于注意力的解码器逐符号拼出最可能的字符序列。
用合成词与真实词教会系统
训练这样一个系统需要大量标注样本。作者采用了两步策略。首先,他们在数百万合成单词图像上进行预训练,合成图像在字体、大小和扭曲方面提供了巨大的多样性。在此阶段,他们使用一种关注难例并防止模型对单一预测过于自信的损失函数来引导学习。接着,他们在从国际竞赛和开放图像项目收集的大量真实世界数据集上进行微调。这些数据集包含直线和弯曲文本、多种语言、门牌号以及不同光照和天气下的标志。团队对样本进行仔细的调整大小、过滤和均衡,使模型看到公平的案例混合,而不过度拟合到任何单一来源。
实际效果如何
在六个广泛使用的基准上测试时,该新框架在同时使用合成与真实数据训练时达到约 94.7% 的平均准确率,明显优于仅用合成数据的版本,并在类似条件下与其他领先方法相比具有竞争力或更好。详细分析显示,加入的归一化和注意力模块对不规则文本(如弯曲或倾斜且背景混乱的单词)尤其有帮助。与此同时,该系统仍然相对轻量:大约使用 2000 万参数,并且在现代显卡上可在几毫秒的千分之一级时间内识别一个单词图像。这种速度与精度之间的平衡使其适用于实时应用,如驾驶辅助或移动设备上的实时翻译。 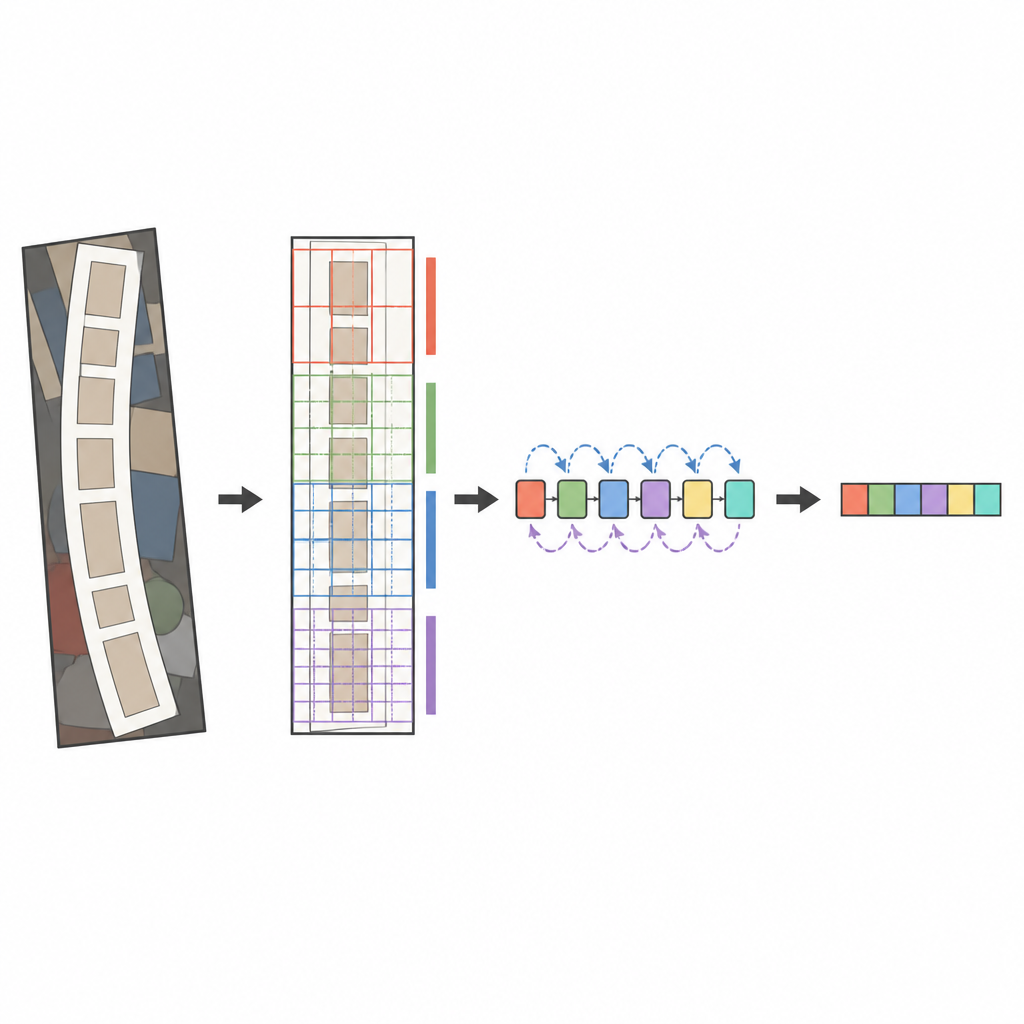
这对日常技术意味着什么
简言之,这项研究表明,经过精心设计的图像骨干网络、搭配智能序列读取器并在合成与真实场景上训练,可以更可靠、更快速地读取凌乱的真实世界文本。对非专业读者而言,这意味着未来的应用程序可能在透过挡风玻璃读取路牌、识别超市标签或为视力不佳的用户朗读场景内容方面表现更好。尽管该系统在极端模糊、强烈眩光和高度风格化字体下仍存在困难,但它为在日常生活复杂视觉环境中运行的更稳健、灵活的文本读取工具奠定了坚实基础。
引用: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
关键词: 场景文本识别, 深度学习, ConvNeXt, 真实世界数据集, 计算机视觉