Clear Sky Science · nl
Een hybride ConvNeXt–BiLSTM-kader voor robuuste herkenning van tekst in scènes
Waarom tekst lezen op foto’s ertoe doet
Elke dag leggen camera’s straatnaamborden, winkelnamen, bushaltes en schermafbeeldingen vol woorden vast. Computers leren dit soort tekst te lezen kan navigatie-apps aandrijven, mensen met een visuele beperking helpen en rommelige foto’s doorzoekbare informatie maken. Toch is tekst in de echte wereld zelden netjes: het kan gebogen, gekanteld, wazig of verscholen in drukke achtergronden zijn. Deze studie introduceert een slimmere en snellere manier voor computers om zulke uitdagende tekst in scènes te lezen, door te herontwerpen hoe ze naar beelden kijken en hoe ze leren van zowel synthetische als echte voorbeelden. 
Van schone scans naar rommelige realiteit
Traditionele tekstleessoftware was gebouwd voor gescande documenten, waar letters op vlakke, schone pagina’s staan. Herkenning van tekst in scènes moet daarentegen omgaan met verkeersborden vanuit een hoek gefotografeerd, neonlogo’s, weerspiegelingen op metaal en een mix van lettertypen en talen. Vroegere systemen leunden zwaar op synthetische data: computergeneratorwoorden geplakt op afbeeldingen. Deze grote kunstmatige verzamelingen zijn gemakkelijk te labelen maar missen de volledige chaos van echte straten. Daardoor kunnen modellen die het goed doen op testsuites alsnog falen bij drukke reclameborden, gebogen winkelnamen of weinig licht. De auteurs stellen dat vooruitgang nu afhangt van zowel betere beeldverwerking als een rijkere voeding van real-world voorbeelden.
Een nieuwe manier om woorden in beelden te bekijken
De kern van het voorgestelde systeem is een moderne image-analyzer genaamd ConvNeXt, gecombineerd met een sequentielezer bekend als een bidirectionele LSTM. Voordat het beeld geanalyseerd wordt, recht een speciale transformatiefase vervormde of gebogen tekst zachtjes zodat het meer als een horizontaal woord lijkt. ConvNeXt verdeelt het beeld vervolgens in vele kleine onderdelen en leert patronen die fijne streken, tekenvormen en de langere horizontale stroom van woorden vastleggen, terwijl afleidende achtergrondrommel wordt genegeerd. Extra modules helpen het netwerk globale context tegen lokale details af te wegen en concentreren de aandacht op de meest informatieve regio’s, zoals waar letters daadwerkelijk voorkomen. Tenslotte scant de sequentielezer deze kenmerken van links naar rechts en van rechts naar links, en een attention-gebaseerde decoder spelt telkens het meest waarschijnlijke teken in de reeks uit.
Het systeem leren met nep- en echte woorden
Het trainen van zo’n systeem vereist enorme aantallen gelabelde voorbeelden. De auteurs gebruiken een tweestapsstrategie. Eerst pre-trainen ze op miljoenen synthetische woordafbeeldingen, die enorme variatie bieden in lettertypen, groottes en vervormingen. Tijdens deze fase passen ze een loss-functie toe die leren richt op moeilijke voorbeelden en voorkomt dat het model te zelfverzekerd wordt in een enkele voorspelling. Vervolgens fine-tunen ze op een grote verzameling real-world datasets, verzameld uit internationale competities en open image-projecten. Deze datasets bevatten rechte en gebogen tekst, meerdere talen, huisnummers en borden onder verschillende licht- en weersomstandigheden. Het team schaalt, filtert en balanceert voorbeelden zorgvuldig zodat het model een eerlijke mix van gevallen ziet en niet overfit op één bron.
Hoe goed het in de praktijk werkt
Getest op zes veelgebruikte benchmarks bereikt het nieuwe kader een gemiddelde nauwkeurigheid van ongeveer 94,7 procent wanneer getraind op zowel synthetische als echte data, duidelijk voor op zijn synthetische-only versie en concurrerend of beter dan andere toonaangevende methoden die onder vergelijkbare voorwaarden zijn getraind. Een gedetailleerde uitsplitsing toont dat de toegevoegde normalisatie- en aandachtblokken vooral helpen bij onregelmatige tekst, zoals gebogen of gekantelde woorden tegen drukke achtergronden. Tegelijk blijft het systeem relatief compact: het gebruikt ongeveer 20 miljoen parameters en kan een woordafbeelding in enkele duizendsten van een seconde lezen op een moderne grafische kaart. Deze balans tussen snelheid en nauwkeurigheid maakt het geschikt voor realtime toepassingen zoals rijhulpsystemen of livevertaling op mobiele apparaten. 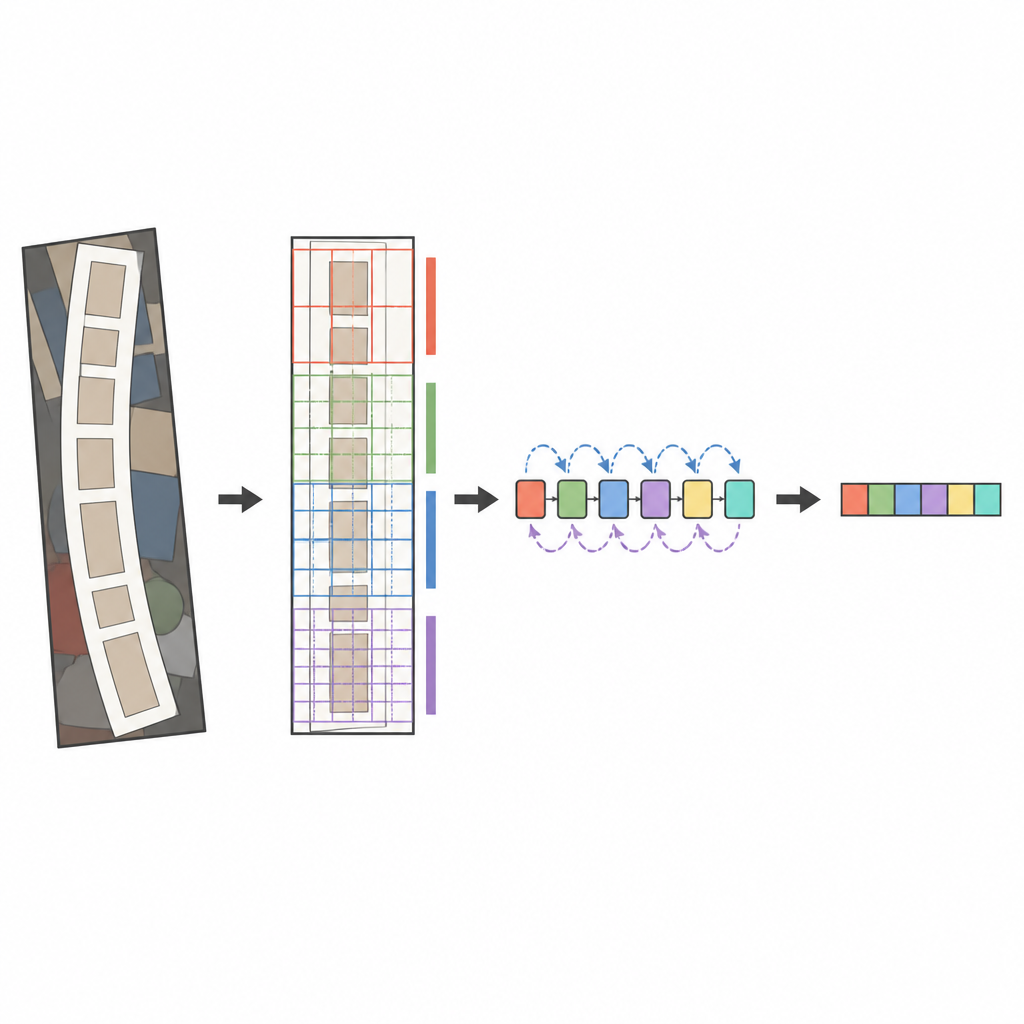
Wat dit betekent voor alledaagse technologie
Kort gezegd laat de studie zien dat een zorgvuldig ontworpen beeldbackbone, gekoppeld aan een slimme sequentielezer en getraind op zowel nep- als echte scènes, rommelige real-world tekst betrouwbaarder en sneller kan lezen. Voor niet-specialisten betekent dit dat toekomstige apps mogelijk beter straatnaamborden door een voorruit kunnen lezen, etiketten in supermarkten herkennen of de inhoud van een scène voorlezen voor gebruikers die die slecht kunnen zien. Hoewel het systeem nog steeds moeite heeft met extreem wazige beelden, sterke schittering en sterk gestileerde lettertypen, vormt het een stevige basis voor robuustere, flexibele tekstleesinstrumenten die functioneren in de complexe visuele omgevingen van het dagelijks leven.
Bronvermelding: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
Trefwoorden: herkenning van tekst in scènes, deep learning, ConvNeXt, real-world datasets, computer vision