Clear Sky Science · de
Ein hybrides ConvNeXt–BiLSTM‑Framework für robuste Texterkennung in Szenen
Warum das Lesen von Texten auf Fotos wichtig ist
Jeden Tag erfassen Kameras Straßenschilder, Ladennamen, Bushaltestellen und Bildschirmausschnitte voller Wörter. Computern beizubringen, solche Texte zu lesen, kann Navigations-Apps antreiben, Menschen mit eingeschränktem Sehvermögen helfen und unordentliche Fotos in durchsuchbare Informationen verwandeln. Doch Text in freier Wildbahn ist selten ordentlich: Er kann gebogen, geneigt, verschwommen oder in einem unruhigen Hintergrund versteckt sein. Diese Studie stellt einen schlaueren und schnelleren Ansatz vor, mit dem Computer solche herausfordernden Szenentexte lesen können, indem ihre Bildsicht und ihr Lernen aus synthetischen sowie realen Beispielen neu gestaltet werden. 
Von sauberen Scans zu unordentlichem Realbild
Traditionelle Texterkennungssoftware wurde für gescannte Dokumente entwickelt, in denen Buchstaben auf flachen, sauberen Seiten stehen. Die Texterkennung in Szenen dagegen muss mit Straßenschildern zurechtkommen, die schräg aufgenommen wurden, Neonlogos, Reflexionen auf Metall sowie einer Mischung aus Schriftarten und Sprachen. Frühere Systeme setzten stark auf synthetische Daten: computergenerierte Wörter, die in Bilder eingefügt wurden. Diese großen künstlichen Sammlungen sind leicht zu beschriften, fehlen jedoch die volle Unordnung realer Straßen. Infolgedessen können Modelle, die in Testsets gut abschneiden, bei überfüllten Werbetafeln, geschwungenen Ladenschriften oder bei wenig Licht versagen. Die Autoren argumentieren, dass weiterer Fortschritt nun sowohl bessere Bildverarbeitung als auch eine reichhaltigere Auswahl an realen Beispielen erfordert.
Eine neue Art, Wörter in Bildern zu betrachten
Der Kern des vorgeschlagenen Systems ist ein moderner Bildanalysator namens ConvNeXt, kombiniert mit einem Sequenzleser, der als bidirektionales LSTM bekannt ist. Bevor das Bild analysiert wird, begradigt eine spezielle Transformationsstufe verzerrten oder gebogenen Text so, dass er eher wie ein horizontaler Wortverlauf aussieht. ConvNeXt zerlegt das Bild dann in viele kleine Teile und lernt Muster, die feine Striche, Zeichenformen und den längeren horizontalen Fluss von Wörtern erfassen, während störender Hintergrund ausgeblendet wird. Zusätzliche Module helfen dem Netzwerk, globalen Kontext gegen lokale Details abzuwägen und seine Aufmerksamkeit auf die informativsten Bereiche zu richten, etwa dort, wo tatsächlich Buchstaben erscheinen. Schließlich scannt der Sequenzleser diese Merkmale von links nach rechts und von rechts nach links, und ein auf Aufmerksamkeit basierender Decoder buchstabiert die wahrscheinlichste Zeichenfolge ein Symbol nach dem anderen.
Das System mit künstlichen und realen Wörtern lehren
Für das Training eines solchen Systems sind riesige Mengen beschrifteter Beispiele erforderlich. Die Autoren verwenden eine zweistufige Strategie. Zuerst pre‑trainieren sie mit Millionen synthetischer Wortbilder, die eine große Vielfalt an Schriftarten, Größen und Verzerrungen bieten. Während dieser Phase wenden sie eine Verlustfunktion an, die das Lernen auf harte Beispiele konzentriert und verhindert, dass das Modell zu selbstsicher in einzelne Vorhersagen wird. Anschließend fine‑tun sie an einer großen Sammlung realer Datensätze, die aus internationalen Wettbewerben und Open‑Image‑Projekten stammen. Diese Datensätze enthalten gerade und geschwungene Texte, mehrere Sprachen, Hausnummern und Schilder bei unterschiedlichen Licht‑ und Wetterverhältnissen. Das Team passt Größen an, filtert und balanciert die Proben sorgfältig, sodass das Modell eine faire Mischung von Fällen sieht und nicht auf eine einzelne Quelle überangepasst wird.
Wie gut es in der Praxis funktioniert
Getestet auf sechs weit verbreiteten Benchmarks erreicht das neue Framework eine durchschnittliche Genauigkeit von etwa 94,7 Prozent, wenn es auf synthetischen und realen Daten trainiert wurde — klar vor seiner reinen Synthese‑Variante und konkurrenzfähig oder besser als andere führende Methoden unter ähnlichen Bedingungen. Eine detaillierte Aufschlüsselung zeigt, dass die hinzugefügten Normalisierungs‑ und Aufmerksamkeitsblöcke besonders bei unregelmäßigem Text helfen, etwa bei geschwungenen oder geneigten Wörtern vor unruhigem Hintergrund. Gleichzeitig bleibt das System relativ leichtgewichtig: Es nutzt etwa 20 Millionen Parameter und kann ein Wortbild in wenigen Tausendstelsekunden auf einer modernen Grafikkarte lesen. Dieses Gleichgewicht aus Geschwindigkeit und Genauigkeit macht es geeignet für Echtzeitanwendungen wie Fahrerassistenz oder Live‑Übersetzung auf Mobilgeräten. 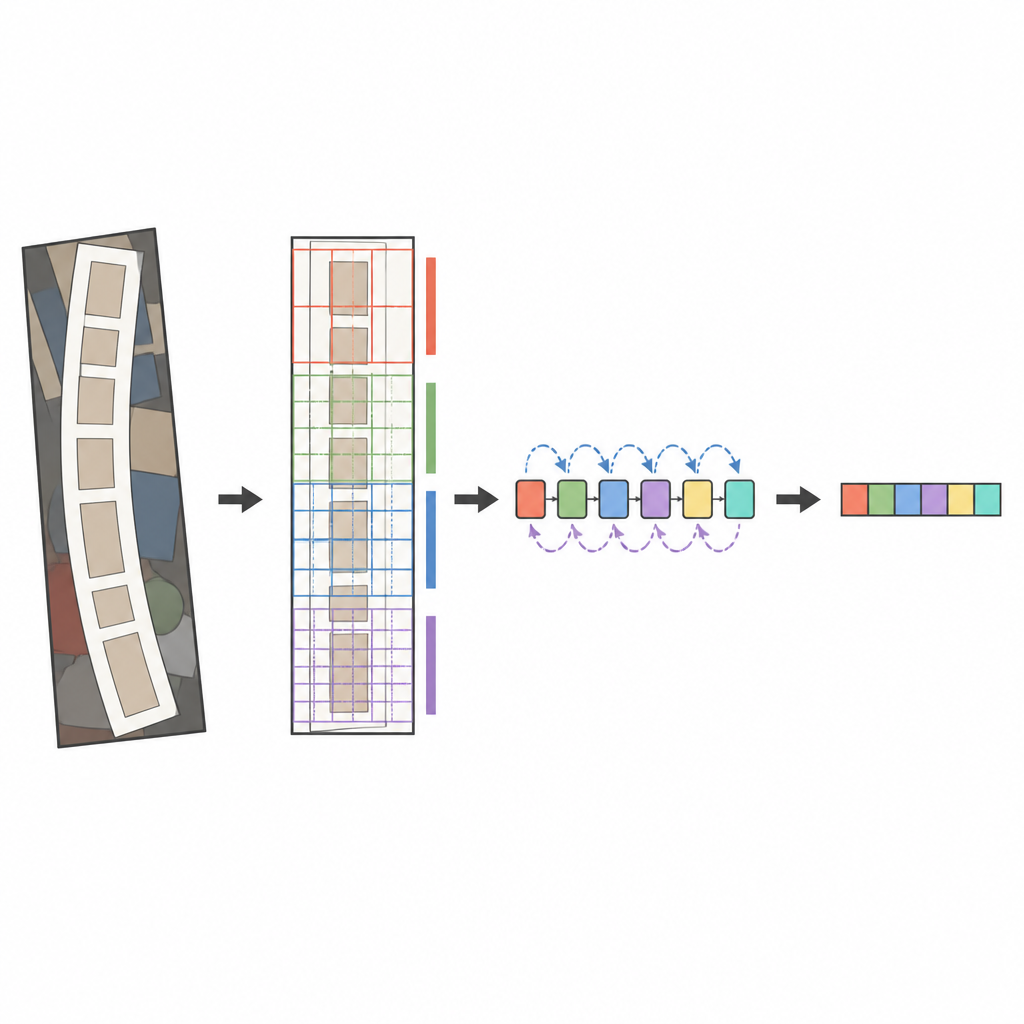
Was das für Alltagstechnik bedeutet
Kurz gesagt zeigt die Studie, dass ein sorgfältig gestaltetes Bild‑Backbone, kombiniert mit einem schlauen Sequenzleser und trainiert auf synthetischen sowie realen Szenen, unordentlichen Realwelttext zuverlässiger und schneller lesen kann. Für Nicht‑Spezialisten bedeutet das, dass künftige Apps Straßenschilder durch die Windschutzscheibe besser lesen, Etiketten im Supermarkt erkennen oder den Inhalt einer Szene für Menschen mit eingeschränktem Sehvermögen besser beschreiben könnten. Zwar hat das System weiterhin Probleme mit extremer Unschärfe, starkem Blendeffekt und sehr stilisierten Schriften, dennoch legt es eine solide Grundlage für robustere, flexiblere Texterkennungswerkzeuge, die in den komplexen visuellen Umgebungen des Alltags funktionieren.
Zitation: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
Schlüsselwörter: Texterkennung in Szenen, Tiefes Lernen, ConvNeXt, reale Datensätze, Computer Vision