Clear Sky Science · sv
En hybrid ConvNeXt–BiLSTM‑arkitektur för robust scen‑texterkänning
Varför det är viktigt att läsa text i foton
Varje dag fångar kameror upp gatuskyltar, butiksnamn, busshållplatser och skärmdumpar fyllda med ord. Att lära datorer att läsa denna typ av text kan driva navigationsappar, hjälpa personer med nedsatt syn och göra röriga foton sökbara. Text i det vilda är dock sällan prydlig: den kan vara böjd, sned, suddig eller gömd i röriga bakgrunder. Denna studie introducerar ett smartare och snabbare sätt för datorer att läsa sådan utmanande scen‑text genom att omformge hur de betraktar bilder och hur de lär sig från både syntetiska och verkliga exempel. 
Från rena skanningar till rörigt verklighetsmaterial
Traditionell textigenkänning mjukvara byggdes för skannade dokument, där bokstäver sitter på plana, rena sidor. Scen‑texterkänning måste däremot hantera vägskyltar fotograferade i sned vinkel, neonskyltar, reflektioner i metall och en blandning av typsnitt och språk. Tidigare system lutade tungt mot syntetiska data: datorgenererade ord inplacerade i bilder. Dessa stora artificiella samlingar är lätta att märka upp men saknar den fulla kaoset från verkliga gator. Följaktligen kan modeller som presterar bra på testset ändå misslyckas när de möter överfulla reklamplancher, böjda butiksskyltar eller svagt ljus. Författarna hävdar att framtida framsteg nu kräver både bättre bildbearbetning och ett rikare utbud av verkliga exempel.
Ett nytt sätt att betrakta ord i bilder
Kärnan i det föreslagna systemet är en modern bildanalysator kallad ConvNeXt, kombinerad med en sekvensläsare känd som en bidirektionell LSTM. Innan bilden analyseras utförs ett särskilt transformationssteg som varsamt rätar ut förvrängd eller böjd text så att den mer liknar ett horisontellt ord. ConvNeXt delar sedan upp bilden i många små delar och lär sig mönster som fångar fina streck, teckenformer och det längre horisontella flödet i ord, samtidigt som störande bakgrundsbrus ignoreras. Extra moduler hjälper nätverket att balansera global kontext mot lokal detalj och fokusera uppmärksamheten på de mest informativa regionerna, såsom där bokstäver faktiskt förekommer. Slutligen skannar sekvensläsaren dessa funktioner från vänster till höger och höger till vänster, och en uppmärksamhetsbaserad avkodare stavar ut den mest sannolika teckensekvensen ett symbol i taget.
Att lära systemet med fejkade och verkliga ord
Träning av ett sådant system kräver enorma mängder märkta exempel. Författarna använder en tvåstegsstrategi. Först förtränar de på miljontals syntetiska ordbilder, som erbjuder stor variation i typsnitt, storlekar och förvrängningar. Under detta skede tillämpar de en förlustfunktion som fokuserar lärandet på svåra exempel och förhindrar att modellen blir alltför säker i enskilda prediktioner. Därefter finjusterar de på en stor samling verkliga dataset insamlade från internationella tävlingar och öppna bildprojekt. Dessa dataset innehåller raka och böjda texter, flera språk, husnummer och skyltar under varierande ljus‑ och väderförhållanden. Teamet ändrar noggrant storlek, filtrerar och balanserar prover så att modellen får en rättvis blandning av fall och inte överanpassar sig till någon enskild källa.
Hur bra det fungerar i praktiken
Testat på sex allmänt använda benchmarks når den nya ramen en genomsnittlig noggrannhet på cirka 94,7 procent när den tränats på både syntetiska och verkliga data, tydligt före sin egen version som endast tränats på syntetiska data och konkurrenskraftig med eller bättre än andra ledande metoder som tränats under liknande förhållanden. En detaljerad uppdelning visar att de tillagda normaliserings‑ och uppmärksamhetsblocken särskilt hjälper vid oregelbunden text, såsom böjda eller sneda ord mot röriga bakgrunder. Samtidigt förblir systemet relativt lätt: det använder ungefär 20 miljoner parametrar och kan läsa en ordbild på några tusendelar av en sekund på ett modernt grafikkort. Denna balans mellan hastighet och noggrannhet gör det lämpligt för realtidsanvändning som förarassistans eller live‑översättning på mobil enhet. 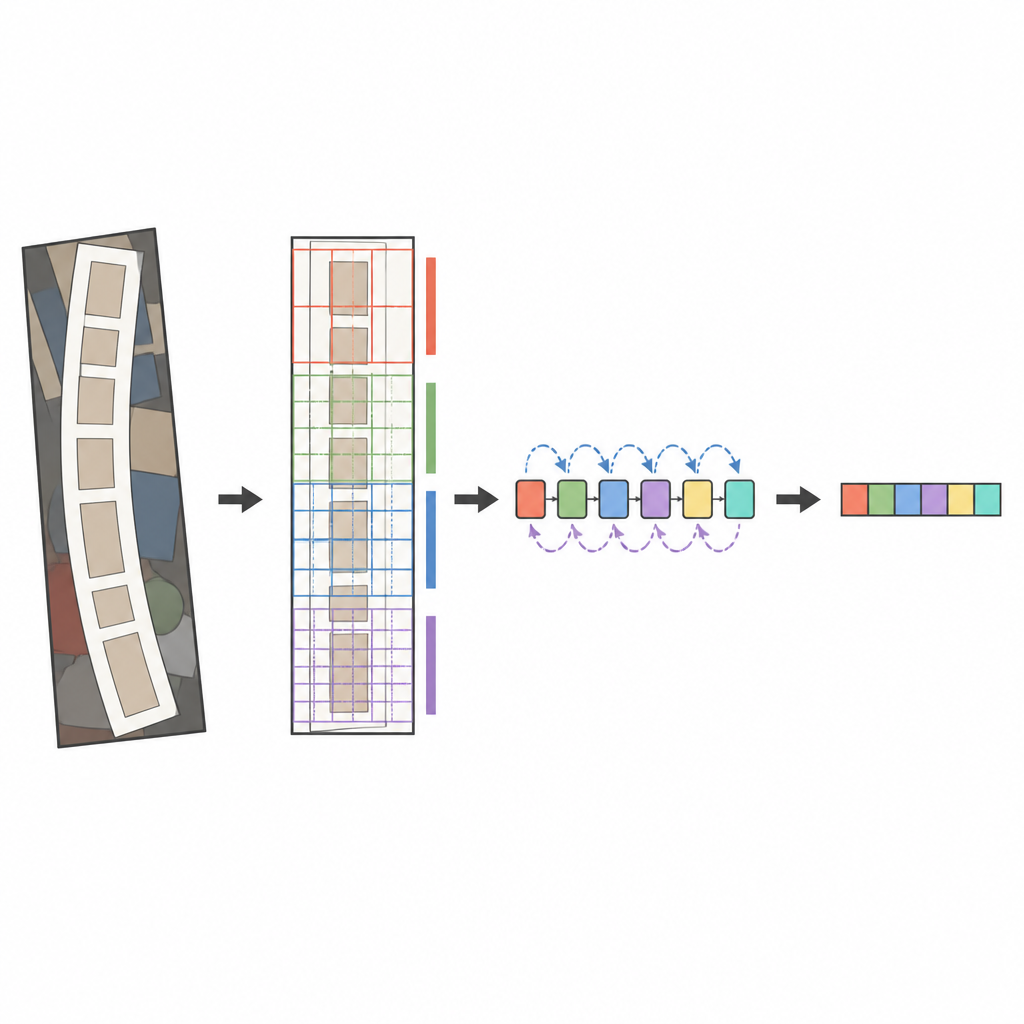
Vad detta innebär för vardagsteknik
Enkelt uttryckt visar studien att en noggrant utformad bildfront, ihopkopplad med en smart sekvensläsare och tränad på både fejkade och verkliga scener, kan läsa rörig text i verkliga miljöer mer pålitligt och snabbare. För icke‑specialister betyder det att framtida appar kan bli bättre på att läsa gatuskyltar genom vindrutan, känna igen etiketter i mataffärer eller återge innehållet i en scen för användare som har dålig syn. Även om systemet fortfarande kämpar med extrem oskärpa, kraftig bländning och mycket stiliserade typsnitt, lägger det en stark grund för mer robusta och flexibla verktyg för textläsning som fungerar i vardagens komplexa visuella miljöer.
Citering: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
Nyckelord: scen‑texterkänning, djuplärande, ConvNeXt, verkliga dataset, datorseende