Clear Sky Science · pl
Hybrydowe rozwiązanie ConvNeXt–BiLSTM dla odpornego rozpoznawania tekstu w scenach
Dlaczego czytanie tekstu na zdjęciach ma znaczenie
Codziennie aparaty rejestrują znaki uliczne, nazwy sklepów, przystanki autobusowe i zrzuty ekranu wypełnione słowami. Nauczenie komputerów czytania tego rodzaju tekstu może zasilać aplikacje nawigacyjne, pomagać osobom z niedowidzeniem i przekształcać chaotyczne zdjęcia w przeszukiwalne informacje. Tymczasem tekst w naturalnym środowisku rzadko bywa uporządkowany: może być zakrzywiony, nachylony, zamazany lub ukryty na zatłoczonym tle. W badaniu tym przedstawiono mądrzejszy i szybszy sposób, w jaki komputery mogą czytać taki wymagający tekst w scenach, przez przeprojektowanie sposobu analizy obrazu i procesu uczenia się na przykładach syntetycznych i rzeczywistych. 
Od czystych skanów do chaotycznej rzeczywistości
Tradycyjne oprogramowanie do odczytu tekstu było tworzone pod kątem skanowanych dokumentów, gdzie litery znajdują się na płaskich, czystych stronach. Rozpoznawanie tekstu w scenach musi z kolei radzić sobie ze znakami drogowymi sfotografowanymi pod kątem, neonowymi logotypami, odbiciami na metalu oraz mieszaniną czcionek i języków. Poprzednie systemy opierały się w dużej mierze na danych syntetycznych: komputerowo generowanych słowach wklejanych w obrazy. Te obszerne sztuczne zbiory są łatwe do oznaczenia, ale brakuje im pełnego chaosu prawdziwych ulic. W rezultacie modele, które dobrze wypadają na zestawach testowych, mogą zawodzić w zetknięciu z zatłoczonymi billboardami, zakrzywionymi nazwami sklepów lub słabym oświetleniem. Autorzy twierdzą, że dalszy postęp zależy teraz zarówno od lepszego przetwarzania obrazu, jak i bogatszego zasobu przykładów z rzeczywistego świata.
Nowy sposób patrzenia na słowa na obrazach
Rdzeniem proponowanego systemu jest nowoczesny analizator obrazu o nazwie ConvNeXt, połączony z czytnikiem sekwencji znanym jako dwukierunkowy LSTM. Zanim obraz zostanie przeanalizowany, specjalny etap transformacji delikatnie prostuje zniekształcony lub zakrzywiony tekst, tak aby przypominał bardziej poziome słowo. ConvNeXt następnie dzieli obraz na wiele małych fragmentów i uczy się wzorców uchwytujących drobne pociągnięcia, kształty znaków oraz dłuższy poziomy przepływ słów, ignorując przy tym rozpraszające tło. Dodatkowe moduły pomagają sieci wyważyć kontekst globalny wobec detalu lokalnego i skierować uwagę na najbardziej informatywne obszary, takie jak miejsca występowania liter. Na końcu czytnik sekwencji skanuje te cechy z lewej do prawej i z prawej do lewej, a dekoder oparty na mechanizmie uwagi odczytuje najbardziej prawdopodobną sekwencję znaków znak po znaku.
Nauczanie systemu na przykładach sztucznych i rzeczywistych
Szkolenie takiego systemu wymaga ogromnej liczby oznaczonych przykładów. Autorzy stosują dwuetapową strategię. Najpierw przeprowadzają wstępne szkolenie na milionach syntetycznych obrazów słów, które oferują ogromną różnorodność krojów, rozmiarów i zniekształceń. W tym etapie stosują funkcję straty, która skupia naukę na trudnych przykładach i zapobiega nadmiernej pewności modelu wobec pojedynczej predykcji. Następnie dokonują dopracowania (fine-tuningu) na dużym zbiorze danych z rzeczywistych scen zebranych z międzynarodowych konkursów i otwartych projektów obrazowych. Zbiory te obejmują tekst prosty i zakrzywiony, wiele języków, numery domów i znaki w różnych warunkach oświetleniowych i pogodowych. Zespół starannie zmienia rozmiary, filtruje i równoważy próbki, tak aby model widział zrównoważony miks przypadków i nie przeuczał się na którymś z pojedynczych źródeł.
Jak to działa w praktyce
Testowany na sześciu powszechnie używanych benchmarkach, nowy framework osiąga średnią dokładność około 94,7 procent przy treningu na danych syntetycznych i rzeczywistych, wyraźnie wyprzedzając własną wersję trenowaną wyłącznie na danych syntetycznych oraz konkurując z innymi wiodącymi metodami trenowanymi w podobnych warunkach. Szczegółowe rozbicie pokazuje, że dodane bloki normalizacji i uwagi szczególnie pomagają w przypadku nieregularnego tekstu, takiego jak zakrzywione lub nachylone słowa na zatłoczonym tle. Jednocześnie system pozostaje stosunkowo lekki: wykorzystuje około 20 milionów parametrów i potrafi odczytać obraz słowa w kilka tysięcznych sekundy na nowoczesnej karcie graficznej. To wyważenie szybkości i dokładności czyni go odpowiednim do zastosowań w czasie rzeczywistym, takich jak asysta kierowcy czy tłumaczenie na żywo na urządzeniach mobilnych. 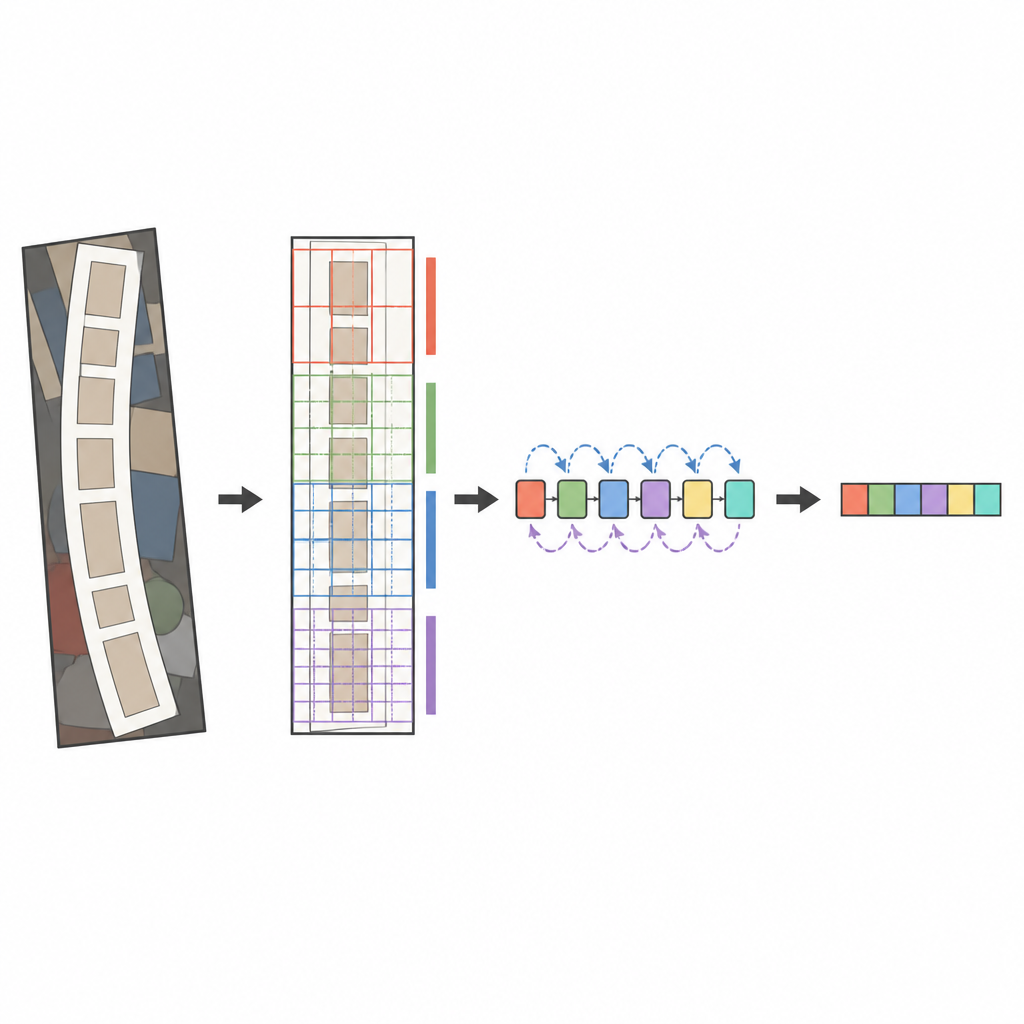
Co to oznacza dla technologii codziennego użytku
Krótko mówiąc, badanie pokazuje, że starannie zaprojektowany rdzeń obrazowy, połączony z inteligentnym czytnikiem sekwencji i trenowany na scenach zarówno sztucznych, jak i rzeczywistych, potrafi czytać chaotyczny tekst z rzeczywistego świata bardziej niezawodnie i szybciej. Dla użytkowników nietechnicznych oznacza to, że przyszłe aplikacje mogą lepiej odczytywać znaki uliczne przez przednią szybę, rozpoznawać etykiety w supermarketach lub opisywać zawartość sceny dla osób słabowidzących. Choć system wciąż ma problemy z ekstremalnym rozmyciem, silnym oślepieniem i bardzo stylizowanymi krojami pisma, stanowi solidną podstawę pod bardziej odporne i elastyczne narzędzia do czytania tekstu działające w złożonych wizualnych warunkach codziennego życia.
Cytowanie: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
Słowa kluczowe: rozpoznawanie tekstu w scenach, uczenie głębokie, ConvNeXt, dane z rzeczywistego świata, widzenie komputerowe