Clear Sky Science · ru
Гибридная схема ConvNeXt–BiLSTM для надёжного распознавания текста в сценах
Почему важно читать текст на фотографиях
Ежедневно камеры фиксируют уличные знаки, названия магазинов, остановки и скриншоты, полные слов. Научить компьютеры читать такие тексты позволяет улучшить приложения для навигации, помочь людям с нарушением зрения и превратить беспорядочные фото в индексируемую информацию. Однако текст «в дикой природе» редко бывает аккуратным: он может быть изогнутым, наклонённым, размытым или скрытым на загруженном фоне. В этом исследовании предлагается более умный и быстрый способ для компьютеров распознавать такие сложные сцены, путём переработки подхода к анализу изображений и обучения на синтетических и реальных примерах. 
От чистых сканов к хаосу реальной жизни
Традиционное ПО для чтения текста разрабатывали для отсканированных документов, где буквы лежат на плоской, чистой странице. Напротив, распознавание текста в сцене сталкивается со знаком на дороге, снятым под углом, неоновым логотипом, отражениями на металле и сочетанием шрифтов и языков. Ранее системы во многом опирались на синтетические данные: генерируемые компьютером слова, вставленные в изображения. Такие большие искусственные наборы легко разметить, но в них отсутствует весь хаос реальных улиц. В результате модели, которые хорошо показывают себя на контрольных наборах, могут ошибаться при столкновении с переполненными рекламными щитами, изогнутыми названиями магазинов или слабым освещением. Авторы утверждают, что дальнейший прогресс зависит как от улучшенной обработки изображений, так и от более богатого набора реальных примеров.
Новый способ взглянуть на слова в изображениях
Ядро предлагаемой системы — современный анализатор изображений ConvNeXt в сочетании с последовательным считывателем на базе двунаправленного LSTM. Перед анализом изображения специальный этап трансформации аккуратно выпрямляет искажённый или изогнутый текст, чтобы он стал ближе к горизонтальному слову. ConvNeXt затем разбивает изображение на множество мелких фрагментов и изучает шаблоны, захватывающие тонкие штрихи, формы символов и более длинное горизонтальное течение слова, при этом игнорируя отвлекающий фон. Дополнительные модули помогают сети уравновешивать глобальный контекст и локальные детали и фокусироваться на наиболее информативных областях, таких как места появления букв. Наконец, последовательный считыватель просматривает эти признаки слева направо и справа налево, а декодер на основе механизма внимания по одному символу выводит наиболее вероятную последовательность символов.
Обучение системы на искусственных и реальных словах
Обучение такой системы требует гигантского числа размеченных примеров. Авторы применяют двухэтапную стратегию. Сначала проводятся предобучение на миллионах синтетических изображений слов, которые дают огромное разнообразие шрифтов, размеров и искажений. На этой стадии используется функция потерь, которая концентрирует обучение на сложных примерах и не позволяет модели слишком уверенно относиться к одиночному предсказанию. Затем следует дообучение на большой коллекции реальных наборов данных, собранных из международных конкурсов и открытых проектов с изображениями. Эти наборы включают прямой и изогнутый текст, несколько языков, номера домов и знаки при разном освещении и погодных условиях. Команда тщательно изменяет размер, фильтрует и уравновешивает образцы, чтобы модель видела справедливое сочетание случаев и не переобучалась на одном источнике.
Насколько это работает на практике
Проверенная на шести широко используемых бенчмарках, новая схема достигает средней точности около 94,7 процента при обучении на синтетических и реальных данных, заметно опережая свою версию, обученную только на синтетике, и конкурируя или превосходя другие лидирующие методы в сходных условиях обучения. Детальное разложение показывает, что добавленная нормализация и блоки внимания особенно помогают с нерегулярным текстом, таким как изогнутые или наклонённые слова на загруженном фоне. При этом система остаётся относительно лёгкой: она использует около 20 миллионов параметров и может распознавать изображение слова за несколько тысячных секунды на современной видеокарте. Этот баланс между скоростью и точностью делает её пригодной для приложений в реальном времени, таких как помощь водителю или перевод в реальном времени на мобильных устройствах. 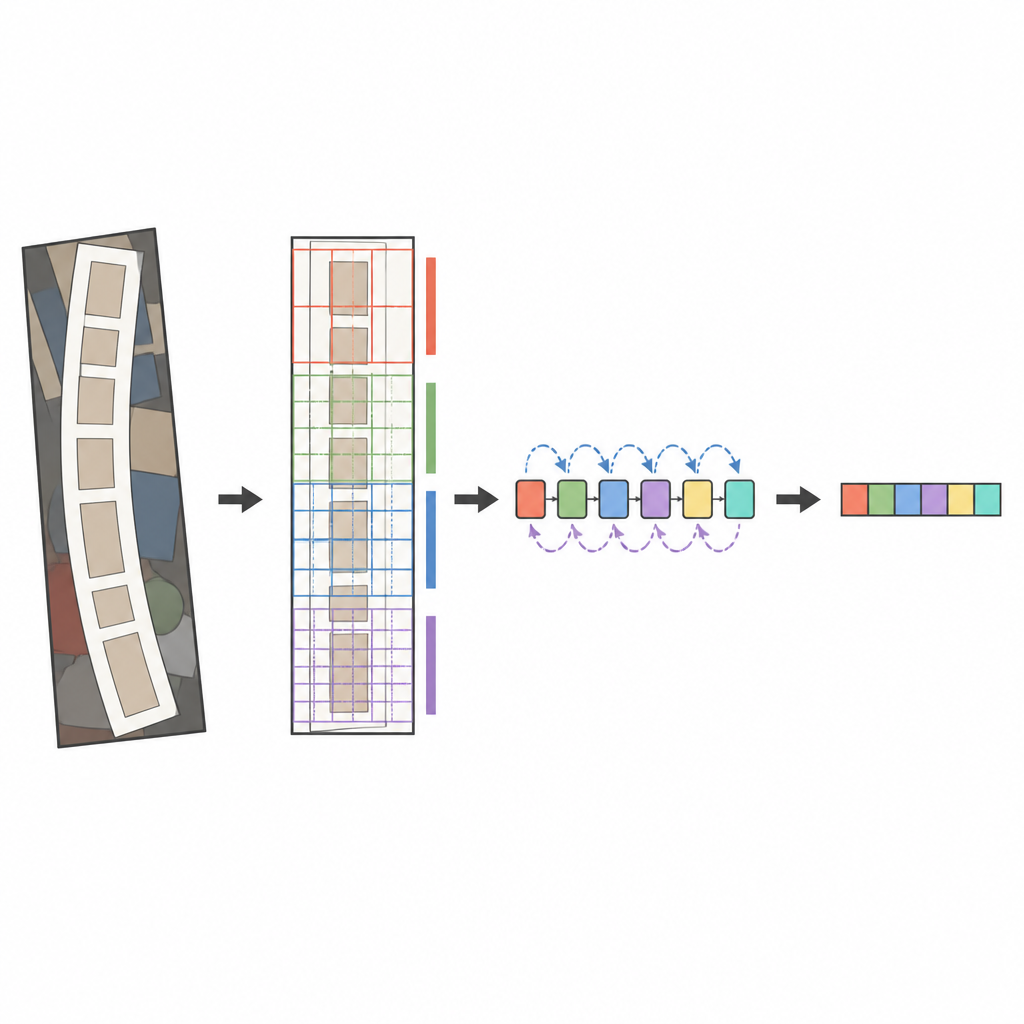
Что это значит для повседневных технологий
Проще говоря, исследование показывает, что тщательно спроектированная основы изображения в сочетании с умным последовательным считывателем и обучением на синтетических и реальных сценах может надёжнее и быстрее читать беспорядочный текст реального мира. Для неспециалистов это означает, что будущие приложения смогут лучше читать уличные знаки через лобовое стекло, распознавать этикетки в супермаркетах или описывать содержимое сцены для пользователей с нарушенным зрением. Хотя система по-прежнему испытывает трудности при сильной размытости, интенсивных бликах и сильно стилизованных шрифтах, она закладывает прочную основу для более надёжных и гибких инструментов чтения текста, работающих в сложных визуальных средах повседневной жизни.
Цитирование: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
Ключевые слова: распознавание текста в сцене, глубокое обучение, ConvNeXt, реальные наборы данных, компьютерное зрение