Clear Sky Science · it
Un framework ibrido ConvNeXt–BiLSTM per il riconoscimento robusto del testo nelle scene
Perché leggere il testo nelle foto è importante
Ogni giorno le fotocamere catturano insegne stradali, nomi di negozi, fermate dell’autobus e schermate piene di parole. Insegnare ai computer a leggere questo tipo di testo può potenziare app di navigazione, aiutare le persone con bassa vista e trasformare foto disordinate in informazioni ricercabili. Eppure il testo “in natura” è raramente ordinato: può essere curvo, inclinato, sfocato o nascosto in sfondi affollati. Questo studio introduce un modo più intelligente e più veloce per far leggere ai computer questo testo difficile, ripensando il modo in cui analizzano le immagini e come apprendono da esempi sia sintetici sia reali. 
Dalle scansioni pulite alla vita reale caotica
Il software tradizionale per la lettura del testo è stato pensato per documenti scansionati, dove le lettere stanno su pagine piatte e pulite. Il riconoscimento del testo nelle scene, invece, deve affrontare cartelli stradali ripresi di sbieco, loghi al neon, riflessi sul metallo e una mescolanza di caratteri e lingue. I sistemi passati si sono appoggiati pesantemente a dati sintetici: parole generate al computer incollate su immagini. Queste grandi collezioni artificiali sono facili da etichettare ma non contengono tutto il caos delle strade reali. Di conseguenza, modelli che funzionano bene su set di test possono comunque fallire davanti a cartelloni affollati, nomi di negozi curvi o scarsa illuminazione. Gli autori sostengono che il progresso dipende ora sia da un migliore trattamento delle immagini sia da una dieta più ricca di esempi reali.
Un nuovo modo di guardare le parole nelle immagini
Il nucleo del sistema proposto è un analizzatore d’immagine moderno chiamato ConvNeXt, combinato con un lettore di sequenze noto come LSTM bidirezionale. Prima che l’immagine venga analizzata, una fase di trasformazione speciale raddrizza delicatamente il testo deformato o curvo in modo che assomigli di più a una parola orizzontale. ConvNeXt poi suddivide l’immagine in tanti piccoli pezzi e apprende pattern che catturano tratti fini, forme dei caratteri e il più ampio flusso orizzontale delle parole, ignorando il clutter di sfondo distraente. Moduli aggiuntivi aiutano la rete a bilanciare il contesto globale con i dettagli locali e a concentrare l’attenzione sulle regioni più informative, come quelle in cui compaiono effettivamente le lettere. Infine, il lettore di sequenze scansiona queste feature da sinistra a destra e da destra a sinistra, e un decoder basato sull’attenzione compone la sequenza di caratteri più probabile un simbolo alla volta.
Insegnare al sistema con parole finte e reali
L’addestramento di un sistema del genere richiede un numero vastissimo di esempi etichettati. Gli autori usano una strategia in due fasi. Prima, pre-addestrano su milioni di immagini di parole sintetiche, che offrono enorme varietà di font, dimensioni e distorsioni. Durante questa fase applicano una funzione di perdita che concentra l’apprendimento sugli esempi difficili e impedisce al modello di diventare troppo sicuro di una singola previsione. Poi affinano il modello su una grande raccolta di dataset reali provenienti da competizioni internazionali e progetti di immagini aperti. Questi dataset includono testo dritto e curvo, più lingue, numeri civici e insegne sotto diverse condizioni di luce e meteo. Il team ridimensiona, filtra e bilancia con cura i campioni in modo che il modello veda un mix equo di casi e non si sovraadatti a una sola fonte.
Quanto funziona nella pratica
Testato su sei benchmark ampiamente usati, il nuovo framework raggiunge un’accuratezza media di circa il 94,7% quando è addestrato sia su dati sintetici sia reali, nettamente avanti rispetto alla sua versione addestrata solo su sintetici e competitivo o migliore rispetto ad altri metodi di punta addestrati in condizioni simili. Un’analisi dettagliata mostra che la normalizzazione aggiuntiva e i blocchi di attenzione aiutano soprattutto con il testo irregolare, come parole curve o inclinate contro sfondi affollati. Allo stesso tempo, il sistema rimane relativamente leggero: utilizza circa 20 milioni di parametri e può leggere un’immagine di parola in pochi millesimi di secondo su una moderna GPU. Questo equilibrio tra velocità e accuratezza lo rende adatto a usi in tempo reale come l’assistenza alla guida o la traduzione live su dispositivi mobili. 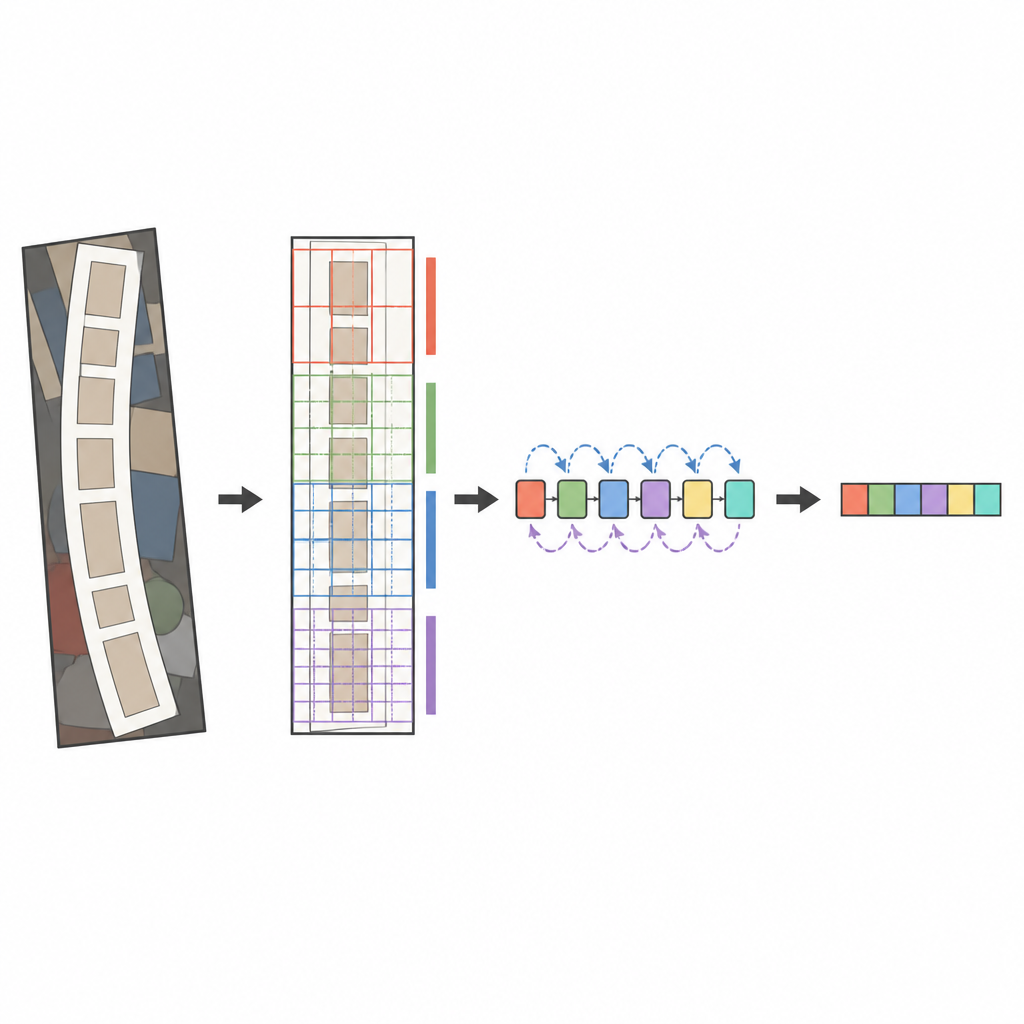
Cosa significa per la tecnologia di tutti i giorni
In parole semplici, lo studio mostra che un backbone d’immagine progettato con cura, abbinato a un lettore di sequenze intelligente e addestrato su scene sia finte sia reali, può leggere testo reale e disordinato in modo più affidabile e rapido. Per i non specialisti, questo significa che le app future potrebbero fare un lavoro migliore nel leggere insegne stradali attraverso un parabrezza, riconoscere etichette nei supermercati o narrare il contenuto di una scena per utenti con vista limitata. Sebbene il sistema fatichi ancora con sfocature estreme, forti abbagliamenti e font altamente stilizzati, pone una solida base per strumenti di lettura del testo più robusti e flessibili che operino negli ambienti visivi complessi della vita quotidiana.
Citazione: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
Parole chiave: riconoscimento del testo nelle scene, deep learning, ConvNeXt, dataset reali, computer vision