Clear Sky Science · he
מסגרת היברידית ConvNeXt–BiLSTM לזיהוי טקסט בסצנות בעמידות גבוהה
מדוע קריאת טקסט בתמונות חשובה
כל יום מצלמות לוכדות שלטי רחוב, שמות חנויות, תחנות אוטובוס וצילומי מסך מלאים במילים. ללמד מחשבים לקרוא סוג טקסט זה יכול להניע אפליקציות ניווט, לסייע לאנשים עם ירידה בראייה ולהפוך תמונות מבולגנות למידע שניתן לחפש בו. ואולם טקסט בסביבה מעולם לא מסודר: הוא עלול להיות מעוקל, מוטה, מטושטש או מוסתר ברקע עמוס. במחקר זה מוצגת דרך חכמה ומהירה יותר לגרום למחשבים לקרוא טקסט קשה כזה, על ידי עיצוב מחודש של האופן שבו הם מסתכלים על תמונות וכיצד הם לומדים מדוגמאות מלאכותיות ומהעולם האמיתי. 
מסריקות נקיות לחיים האמיתיים העמוסים
תוכנות קריאת טקסט מסורתיות נבנו למסמכים סרוקים, שבהם אותיות נמצאות על דפים שטוחים ונקיים. לעומת זאת, זיהוי טקסט בסצנה חייב להתמודד עם שלטי דרכים שצולמו בזווית, לוגואים ניאוניים, השתקפויות על מתכת ותערובת של פונטים ושפות. מערכות קודמות הסתמכו מאוד על נתונים סינטטיים: מילים שנוצרו על ידי מחשב והודבקו על תמונות. אוספים מלאכותיים גדולים אלה קלים לתיוג אך חסרים בהם כל הכאוס של הרחובות האמיתיים. כתוצאה מכך, מודלים שמצליחים במערכי מבחן יכולים עדיין להיכשל מול שלטי חוצות צפופים, שמות חנויות מעוקלות או תאורה חלשה. המחברים טוענים שהתקדמות כיום תלויה הן בעיבוד תמונה משופר והן בדיאטה עשירה יותר של דוגמאות מהעולם האמיתי.
דרך חדשה להסתכל על מילים בתמונות
ליבת המערכת המוצעת היא מנתח תמונה מודרני בשם ConvNeXt, המשולב עם קורא רצפים הידוע כ-BiLSTM (LSTM דו-כיווני). לפני ניתוח התמונה, שלב טרנספורמציה מיוחד מיישר בעדינות טקסט מעוות או מעוקל כך שייראה יותר כמו מילה אופקית. ConvNeXt מחלק אז את התמונה לריבוי חתיכות קטנות ולומד דפוסים שתופסים קווים עדינים, צורות תווים ואת הזרימה האופקית הארוכה של מילים, תוך התעלמות מהמטרדים ברקע. מודולים נוספים עוזרים לרשת לאזן בין הקשר גלובלי לפרטים מקומיים ולכוון את תשומת הלב לאזורים המידעיים ביותר, כמו המקומות שבהם אותיות מופיעות בפועל. לבסוף, קורא הרצפים סורק את התכונות הללו משמאל לימין ומימין לשמאל, והממפענח המבוסס תשומת לב מאיית את רצף התווים הסביר ביותר סימן אחר סימן.
להכשיר את המערכת עם מילים מזויפות ואמיתיות
אימון מערכת כזו דורש כמויות עצומות של דוגמאות מתויגות. המחברים משתמשים באסטרטגיה בעלת שני שלבים. ראשית, הם מבצעים אימון מקדים על מיליוני תמונות מילים סינטטיות, שמציעות מגוון עצום בפונטים, גדלים ועיוותים. במהלך שלב זה הם משתמשים בפונקציית איבוד שממקדת את הלמידה על דוגמאות קשות ומונעת מהמודל להיות בטוח מדי בכל תחזית בודדת. לאחר מכן הם מבצעים כוונון עדין על אוסף גדול של מאגרי נתונים מהעולם האמיתי שנאספו מתחרויות בינלאומיות ופרויקטים פתוחים של תמונות. מאגרים אלה כוללים טקסט ישר ומעוקל, שפות מרובות, מספרי בתים ושלטים בתנאי תאורה ומזג אוויר שונים. הצוות משנה גדלים, מסנן ומאזן דוגמאות בקפידה כדי שהמודל יראה תערובת הוגנת של מקרים ולא יתרגל למקור בודד.
כמה טוב זה עובד בפועל
נבדק בשישה בקרות-תקן נפוצות, המסגרת החדשה מגיעה לדיוק ממוצע של כ-94.7 אחוז כאשר היא מאומנת על נתונים סינטטיים ואמיתיים יחד, בצורה שמציגה יתרון ברור על פני הגרסה המאומנת רק על סינטטי ותחרותיות או עליונות ביחס לשיטות מובילות אחרות שאומנו בתנאים דומים. ניתוח מפורט מראה שהחסמים הנוספים של נרמול ותשומת לב עוזרים במיוחד בטקסטים לא סדירים, כגון מילים מעוקלות או מוטות על רקעים עמוסים. יחד עם זאת, המערכת נשארת יחסית קלת: היא משתמשת בכ-20 מיליון פרמטרים ויכולה לקרוא תמונת מילה תוך אלפי שניות של שנייה על כרטיס גרפי מודרני. האיזון הזה בין מהירות לדיוק הופך אותה מתאימה לשימושים בזמן אמת כמו סיוע לנהג או תרגום חי במכשירים ניידים. 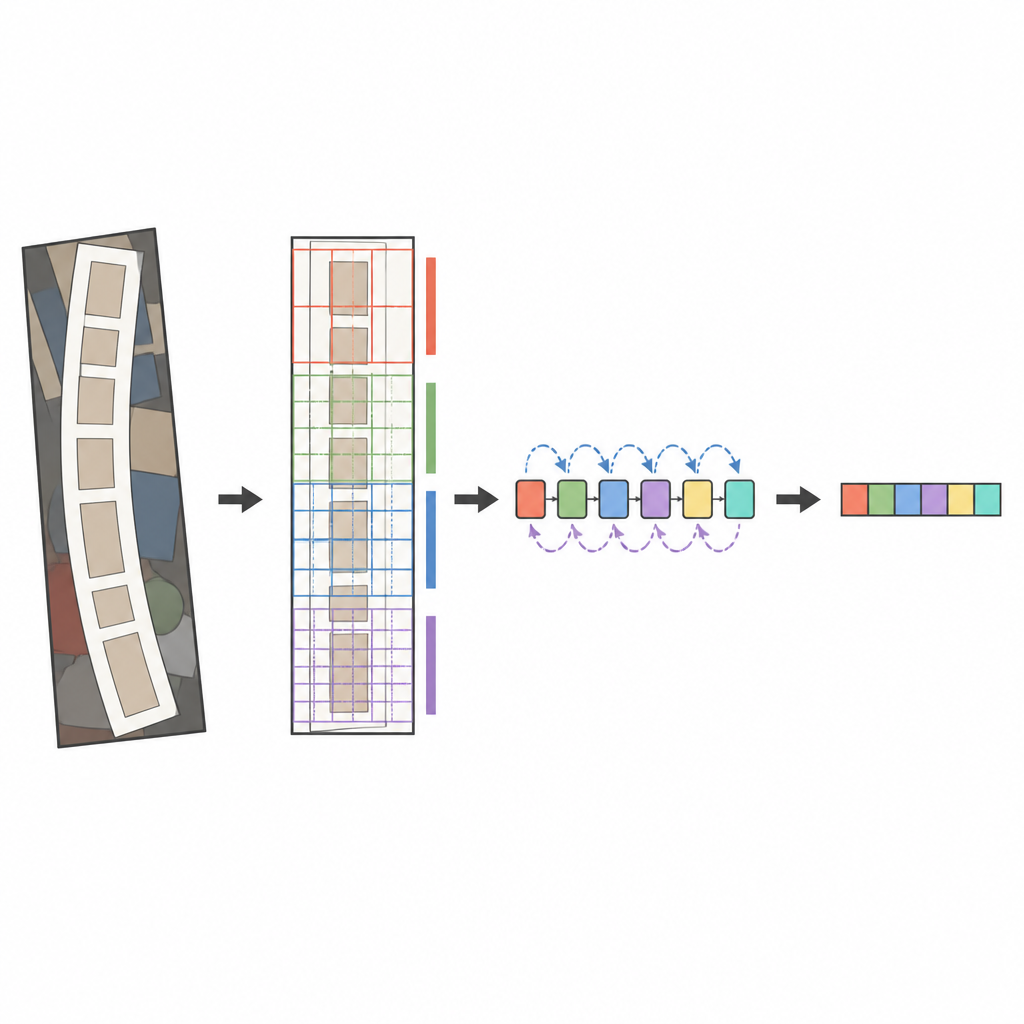
מה זה אומר לטכנולוגיה היומיומית
באופן פשוט, המחקר מראה שמערכת גב חזק לתמונה שעוצבה בקפידה, המשולבת עם קורא רצפים חכם ומאומנת על סצנות מזויפות ואמיתיות, יכולה לקרוא טקסטים מבולגנים מהעולם האמיתי באופן אמין ומהיר יותר. עבור שאינם מומחים, המשמעות היא שאפליקציות עתידיות עשויות לעשות עבודה טובה יותר בקריאת שלטי רחוב דרך שמשת הרכב, בזיהוי תוויות בסופרמרקטים או בסיפר תוכן הסצנה עבור משתמשים שאינם רואים היטב. למרות שהמערכת עדיין מתקשה בטשטוש קיצוני, בזוהר חזק ופונטים מעוצבים מאוד, היא שמה יסוד חזק לכלים קריאת טקסט גמישים ועמידים יותר שפועלים בסביבות הוויזואליות המורכבות של חיי היומיום.
ציטוט: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
מילות מפתח: זיהוי טקסט בסצנה, למידה עמוקה, ConvNeXt, מאגרי נתונים מהעולם האמיתי, ראייה ממוחשבת