Clear Sky Science · pt
Uma estrutura híbrida ConvNeXt–BiLSTM para reconhecimento robusto de texto em cena
Por que ler textos em fotos importa
Diariamente, câmeras capturam placas de rua, nomes de lojas, pontos de ônibus e capturas de tela repletas de palavras. Ensinar computadores a ler esse tipo de texto pode impulsionar aplicativos de navegação, ajudar pessoas com baixa visão e transformar fotos desordenadas em informação pesquisável. Ainda assim, o texto em ambientes reais raramente está arrumado: pode estar curvado, inclinado, desfocado ou escondido em fundos visualmente movimentados. Este estudo apresenta uma maneira mais inteligente e mais rápida para computadores lerem esse texto desafiador, redesenhando tanto a forma como analisam imagens quanto a forma como aprendem a partir de exemplos sintéticos e reais. 
De digitalizações limpas para a vida real bagunçada
O software tradicional de leitura de texto foi criado para documentos digitalizados, onde as letras aparecem em páginas planas e limpas. O reconhecimento de texto em cena, por outro lado, precisa lidar com placas vistas em ângulo, logos de néon, reflexos em metal e uma mistura de fontes e idiomas. Sistemas anteriores dependiam fortemente de dados sintéticos: palavras geradas por computador coladas em imagens. Essas grandes coleções artificiais são fáceis de rotular, mas não capturam todo o caos das ruas reais. Como resultado, modelos que se saem bem em conjuntos de teste podem falhar diante de outdoors lotados, nomes de lojas curvados ou pouca luz. Os autores argumentam que o progresso agora depende tanto de um melhor processamento de imagem quanto de uma dieta mais rica de exemplos do mundo real.
Uma nova forma de ver palavras em imagens
O núcleo do sistema proposto é um analisador de imagem moderno chamado ConvNeXt, combinado com um leitor de sequência conhecido como LSTM bidirecional. Antes de a imagem ser analisada, uma etapa de transformação especial endireita suavemente textos deformados ou curvados para que se pareçam mais com uma palavra horizontal. O ConvNeXt então divide a imagem em muitas pequenas peças e aprende padrões que capturam traços finos, formas de caracteres e o fluxo horizontal mais longo das palavras, enquanto ignora ruído de fundo distrativo. Módulos extras ajudam a rede a equilibrar contexto global e detalhe local e a focar sua atenção nas regiões mais informativas, como onde as letras realmente aparecem. Finalmente, o leitor de sequência varre essas características da esquerda para a direita e da direita para a esquerda, e um decodificador baseado em atenção soletra a sequência de caracteres mais provável, um símbolo por vez.
Ensinando o sistema com palavras falsas e reais
Treinar um sistema desses requer um número vasto de exemplos rotulados. Os autores usam uma estratégia em duas etapas. Primeiro, eles pré-treinam com milhões de imagens de palavras sintéticas, que oferecem enorme variedade em fontes, tamanhos e distorções. Durante essa fase, aplicam uma função de perda que concentra o aprendizado em exemplos difíceis e impede que o modelo fique excessivamente confiante em qualquer previsão única. Em seguida, fazem o fine-tuning em uma grande coleção de conjuntos de dados do mundo real reunidos a partir de competições internacionais e projetos de imagens abertas. Esses conjuntos incluem texto reto e curvo, múltiplos idiomas, números de residências e placas sob diferentes condições de luz e clima. A equipe redimensiona, filtra e balanceia cuidadosamente as amostras para que o modelo veja uma mistura justa de casos e não se ajuste demais a uma única fonte.
Quão bem funciona na prática
Testado em seis benchmarks amplamente usados, o novo framework alcança uma acurácia média de cerca de 94,7% quando treinado com dados sintéticos e reais, claramente à frente de sua versão treinada apenas com sintéticos e competitivo ou superior a outros métodos líderes treinados em condições semelhantes. Uma análise detalhada mostra que os blocos adicionais de normalização e atenção ajudam especialmente com textos irregulares, como palavras curvadas ou inclinadas contra fundos movimentados. Ao mesmo tempo, o sistema permanece relativamente leve: usa cerca de 20 milhões de parâmetros e pode ler uma imagem de palavra em poucos milésimos de segundo em uma placa gráfica moderna. Esse equilíbrio entre velocidade e precisão o torna adequado para usos em tempo real, como assistência ao motorista ou tradução ao vivo em dispositivos móveis. 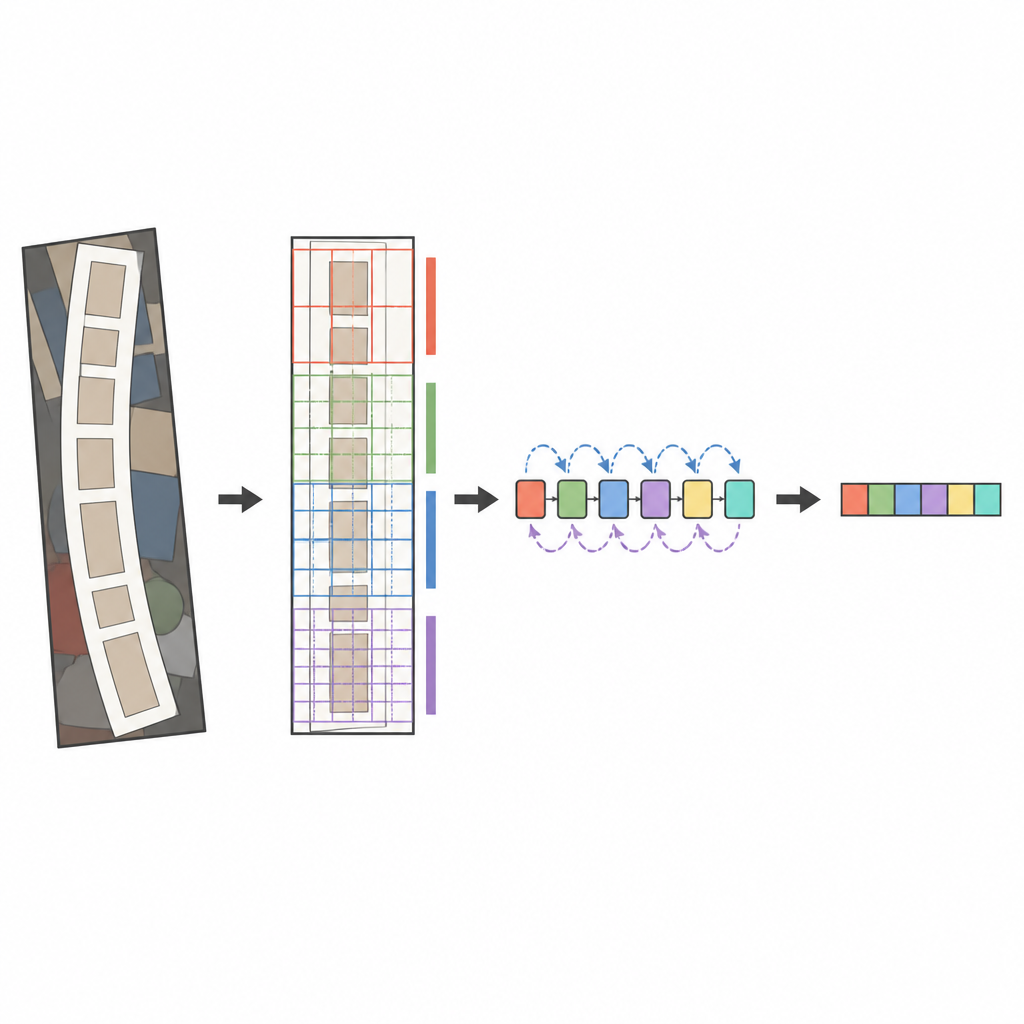
O que isso significa para a tecnologia do dia a dia
Em termos simples, o estudo mostra que um backbone de imagem cuidadosamente projetado, emparelhado com um leitor de sequência inteligente e treinado em cenas sintéticas e reais, pode ler texto do mundo real de forma mais confiável e rápida. Para não especialistas, isso significa que aplicativos futuros podem fazer um trabalho melhor ao ler placas de rua através de um para-brisa, reconhecer rótulos em supermercados ou narrar o conteúdo de uma cena para usuários com baixa visão. Embora o sistema ainda enfrente dificuldades com desfoque extremo, brilho intenso e fontes altamente estilizadas, ele estabelece uma base sólida para ferramentas de leitura de texto mais robustas e flexíveis que operem nos complexos ambientes visuais do cotidiano.
Citação: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
Palavras-chave: reconhecimento de texto em cena, aprendizado profundo, ConvNeXt, conjuntos de dados do mundo real, visão computacional