Clear Sky Science · fr
Un cadre hybride ConvNeXt–BiLSTM pour une reconnaissance de texte en scène robuste
Pourquoi lire le texte dans les photos compte
Tous les jours, des caméras captent des panneaux de rue, des enseignes de magasin, des arrêts de bus et des captures d’écran remplies de mots. Apprendre aux ordinateurs à lire ce type de texte peut alimenter des applications de navigation, aider les personnes malvoyantes et transformer des photos désordonnées en informations consultables. Pourtant, le texte « en condition réelle » est rarement propre : il peut être courbé, incliné, flou ou noyé dans des arrière-plans chargés. Cette étude présente une méthode plus intelligente et plus rapide pour permettre aux ordinateurs de lire ce texte difficile en repensant la manière dont ils analysent les images et dont ils apprennent à partir d’exemples synthétiques et réels. 
Des scans propres à la vie réelle désordonnée
Les logiciels de lecture de texte traditionnels ont été conçus pour des documents numérisés, où les lettres reposent sur des pages planes et propres. La reconnaissance de texte en scène, en revanche, doit gérer des panneaux pris de biais, des logos au néon, des reflets sur le métal et un mélange de polices et de langues. Les systèmes antérieurs s’appuyaient fortement sur des données synthétiques : des mots générés par ordinateur collés sur des images. Ces grandes collections artificielles sont faciles à annoter mais n’embrassent pas tout le chaos des rues réelles. Par conséquent, des modèles qui performent bien sur des jeux de test peuvent encore échouer face à des panneaux publicitaires encombrés, des enseignes courbées ou des scènes en faible luminosité. Les auteurs soutiennent que les progrès dépendent désormais à la fois d’un meilleur traitement de l’image et d’un apport plus riche d’exemples du monde réel.
Une nouvelle manière d’observer les mots dans les images
Le cœur du système proposé est un analyseur d’images moderne appelé ConvNeXt, combiné à un lecteur de séquences connu sous le nom de LSTM bidirectionnel. Avant l’analyse, une étape de transformation spécifique redresse en douceur le texte déformé ou courbé pour qu’il ressemble davantage à un mot horizontal. ConvNeXt découpe ensuite l’image en nombreuses petites régions et apprend des motifs qui captent les traits fins, la forme des caractères et le flux horizontal plus long des mots, tout en ignorant le désordre de l’arrière-plan. Des modules supplémentaires aident le réseau à équilibrer contexte global et détails locaux et à concentrer son attention sur les régions les plus informatives, par exemple là où se trouvent effectivement les lettres. Enfin, le lecteur de séquence parcourt ces caractéristiques de gauche à droite et de droite à gauche, et un décodeur basé sur l’attention épelle la séquence de caractères la plus probable un symbole à la fois.
Enseigner le système avec des mots artificiels et réels
L’entraînement d’un tel système exige d’énormes quantités d’exemples annotés. Les auteurs utilisent une stratégie en deux étapes. D’abord, ils effectuent un pré-entraînement sur des millions d’images de mots synthétiques, qui offrent une grande variété de polices, tailles et distorsions. Pendant cette phase, ils appliquent une fonction de perte qui concentre l’apprentissage sur les exemples difficiles et empêche le modèle de devenir trop confiant dans une prédiction unique. Ensuite, ils affinent le modèle sur une large collection de jeux de données du monde réel rassemblés à partir de compétitions internationales et de projets d’images ouverts. Ces ensembles incluent du texte droit et curvé, plusieurs langues, des numéros de maison et des panneaux sous différents éclairages et conditions météorologiques. L’équipe redimensionne, filtre et équilibre soigneusement les échantillons afin que le modèle voie un mélange représentatif de cas et n’apprenne pas excessivement à partir d’une seule source.
Quelle est son efficacité en pratique
Testé sur six benchmarks largement utilisés, le nouveau cadre atteint une précision moyenne d’environ 94,7 % lorsqu’il est entraîné à la fois sur des données synthétiques et réelles, nettement devant sa propre version entraînée uniquement sur du synthétique et compétitif ou supérieur à d’autres méthodes de pointe entraînées dans des conditions similaires. Une analyse détaillée montre que la normalisation et les blocs d’attention ajoutés aident particulièrement pour le texte irrégulier, comme les mots courbés ou inclinés sur des arrière-plans encombrés. En parallèle, le système reste relativement léger : il utilise environ 20 millions de paramètres et peut lire une image de mot en quelques millièmes de seconde sur une carte graphique moderne. Cet équilibre entre vitesse et précision le rend adapté à des usages en temps réel comme l’assistance au conducteur ou la traduction en direct sur appareils mobiles. 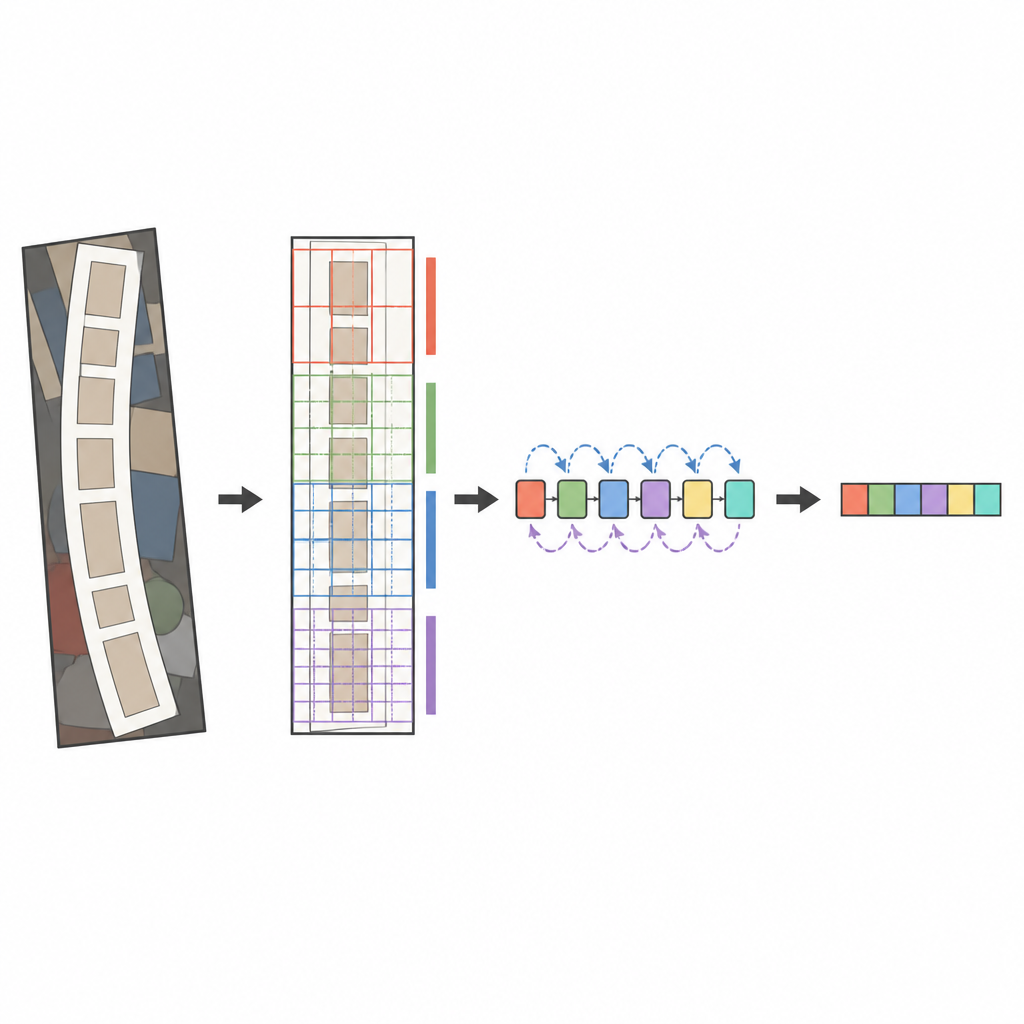
Ce que cela signifie pour la technologie quotidienne
En termes simples, l’étude montre qu’un backbone d’image soigneusement conçu, associé à un lecteur de séquences performant et entraîné sur des scènes synthétiques et réelles, peut lire le texte du monde réel de façon plus fiable et plus rapide. Pour les non-spécialistes, cela signifie que les applications futures pourront mieux lire les panneaux de rue à travers un pare-brise, reconnaître les étiquettes en supermarché ou décrire le contenu d’une scène pour des utilisateurs malvoyants. Bien que le système rencontre encore des difficultés face au flou extrême, aux éblouissements intenses et aux polices très stylisées, il pose une base solide pour des outils de lecture de texte plus robustes et plus flexibles, adaptés aux environnements visuels complexes de la vie quotidienne.
Citation: Khattab, A., Elpeltagy, M., Youness, F. et al. A hybrid ConvNeXt–BiLSTM framework for robust scene text recognition. Sci Rep 16, 15059 (2026). https://doi.org/10.1038/s41598-026-50234-6
Mots-clés: reconnaissance de texte en scène, apprentissage profond, ConvNeXt, jeux de données du monde réel, vision par ordinateur